 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuang Liang
UAV-enabled Collaborative Beamforming via Multi-Agent Deep Reinforcement Learning
Apr 11, 2024
In this paper, we investigate an unmanned aerial vehicle (UAV)-assistant air-to-ground communication system, where multiple UAVs form a UAV-enabled virtual antenna array (UVAA) to communicate with remote base stations by utilizing collaborative beamforming. To improve the work efficiency of the UVAA, we formulate a UAV-enabled collaborative beamforming multi-objective optimization problem (UCBMOP) to simultaneously maximize the transmission rate of the UVAA and minimize the energy consumption of all UAVs by optimizing the positions and excitation current weights of all UAVs. This problem is challenging because these two optimization objectives conflict with each other, and they are non-concave to the optimization variables. Moreover, the system is dynamic, and the cooperation among UAVs is complex, making traditional methods take much time to compute the optimization solution for a single task. In addition, as the task changes, the previously obtained solution will become obsolete and invalid. To handle these issues, we leverage the multi-agent deep reinforcement learning (MADRL) to address the UCBMOP. Specifically, we use the heterogeneous-agent trust region policy optimization (HATRPO) as the basic framework, and then propose an improved HATRPO algorithm, namely HATRPO-UCB, where three techniques are introduced to enhance the performance. Simulation results demonstrate that the proposed algorithm can learn a better strategy compared with other methods. Moreover, extensive experiments also demonstrate the effectiveness of the proposed techniques.
Two-Way Aerial Secure Communications via Distributed Collaborative Beamforming under Eavesdropper Collusion
Apr 11, 2024Unmanned aerial vehicles (UAVs)-enabled aerial communication provides a flexible, reliable, and cost-effective solution for a range of wireless applications. However, due to the high line-of-sight (LoS) probability, aerial communications between UAVs are vulnerable to eavesdropping attacks, particularly when multiple eavesdroppers collude. In this work, we aim to introduce distributed collaborative beamforming (DCB) into UAV swarms and handle the eavesdropper collusion by controlling the corresponding signal distributions. Specifically, we consider a two-way DCB-enabled aerial communication between two UAV swarms and construct these swarms as two UAV virtual antenna arrays. Then, we minimize the two-way known secrecy capacity and the maximum sidelobe level to avoid information leakage from the known and unknown eavesdroppers, respectively. Simultaneously, we also minimize the energy consumption of UAVs for constructing virtual antenna arrays. Due to the conflicting relationships between secure performance and energy efficiency, we consider these objectives as a multi-objective optimization problem. Following this, we propose an enhanced multi-objective swarm intelligence algorithm via the characterized properties of the problem. Simulation results show that our proposed algorithm can obtain a set of informative solutions and outperform other state-of-the-art baseline algorithms. Experimental tests demonstrate that our method can be deployed in limited computing power platforms of UAVs and is beneficial for saving computational resources.
Decoupling Meta-Reinforcement Learning with Gaussian Task Contexts and Skills
Dec 11, 2023Offline meta-reinforcement learning (meta-RL) methods, which adapt to unseen target tasks with prior experience, are essential in robot control tasks. Current methods typically utilize task contexts and skills as prior experience, where task contexts are related to the information within each task and skills represent a set of temporally extended actions for solving subtasks. However, these methods still suffer from limited performance when adapting to unseen target tasks, mainly because the learned prior experience lacks generalization, i.e., they are unable to extract effective prior experience from meta-training tasks by exploration and learning of continuous latent spaces. We propose a framework called decoupled meta-reinforcement learning (DCMRL), which (1) contrastively restricts the learning of task contexts through pulling in similar task contexts within the same task and pushing away different task contexts of different tasks, and (2) utilizes a Gaussian quantization variational autoencoder (GQ-VAE) for clustering the Gaussian distributions of the task contexts and skills respectively, and decoupling the exploration and learning processes of their spaces. These cluster centers which serve as representative and discrete distributions of task context and skill are stored in task context codebook and skill codebook, respectively. DCMRL can acquire generalizable prior experience and achieve effective adaptation to unseen target tasks during the meta-testing phase. Experiments in the navigation and robot manipulation continuous control tasks show that DCMRL is more effective than previous meta-RL methods with more generalizable prior experience.
Enhancing Molecular Property Prediction via Mixture of Collaborative Experts
Dec 06, 2023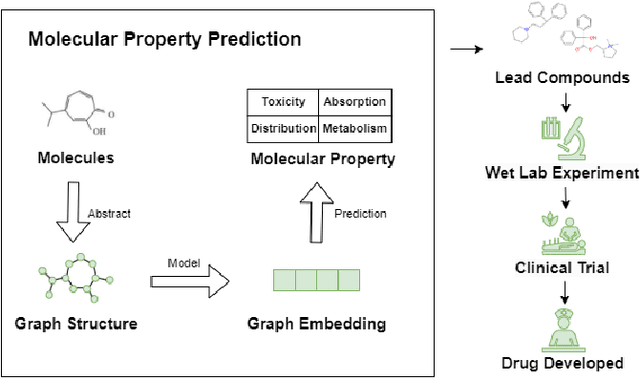
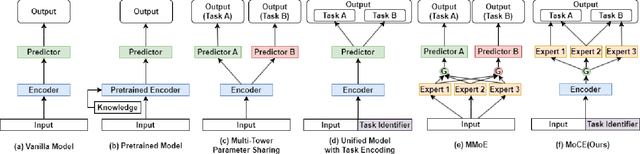
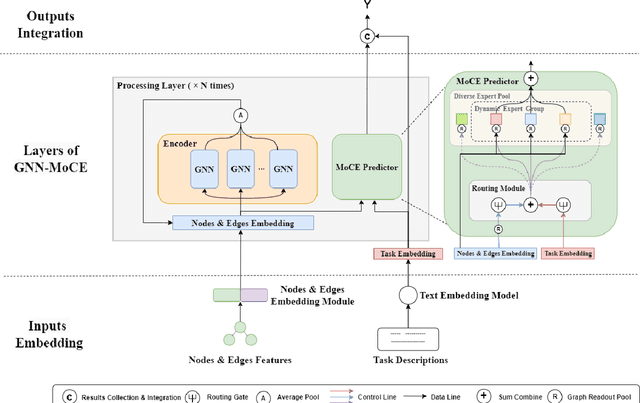
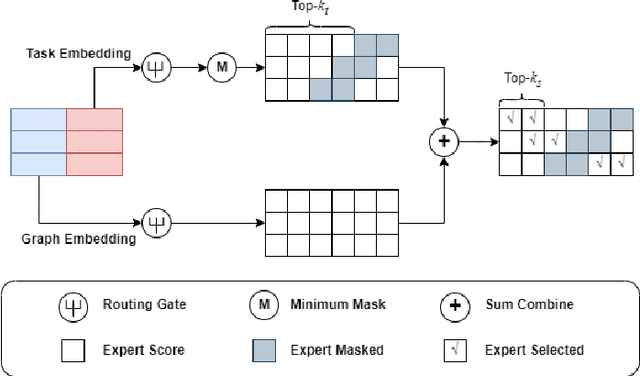
Molecular Property Prediction (MPP) task involves predicting biochemical properties based on molecular features, such as molecular graph structures, contributing to the discovery of lead compounds in drug development. To address data scarcity and imbalance in MPP, some studies have adopted Graph Neural Networks (GNN) as an encoder to extract commonalities from molecular graphs. However, these approaches often use a separate predictor for each task, neglecting the shared characteristics among predictors corresponding to different tasks. In response to this limitation, we introduce the GNN-MoCE architecture. It employs the Mixture of Collaborative Experts (MoCE) as predictors, exploiting task commonalities while confronting the homogeneity issue in the expert pool and the decision dominance dilemma within the expert group. To enhance expert diversity for collaboration among all experts, the Expert-Specific Projection method is proposed to assign a unique projection perspective to each expert. To balance decision-making influence for collaboration within the expert group, the Expert-Specific Loss is presented to integrate individual expert loss into the weighted decision loss of the group for more equitable training. Benefiting from the enhancements of MoCE in expert creation, dynamic expert group formation, and experts' collaboration, our model demonstrates superior performance over traditional methods on 24 MPP datasets, especially in tasks with limited data or high imbalance.
UAV Swarm-enabled Collaborative Secure Relay Communications with Time-domain Colluding Eavesdropper
Oct 03, 2023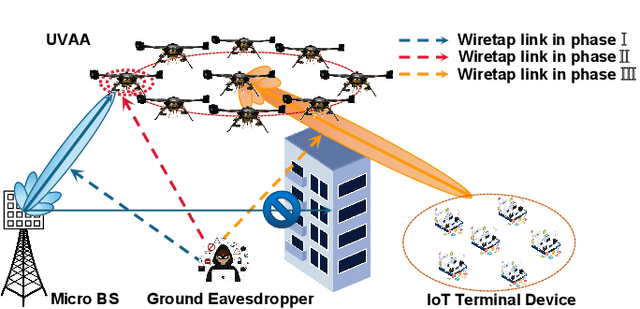
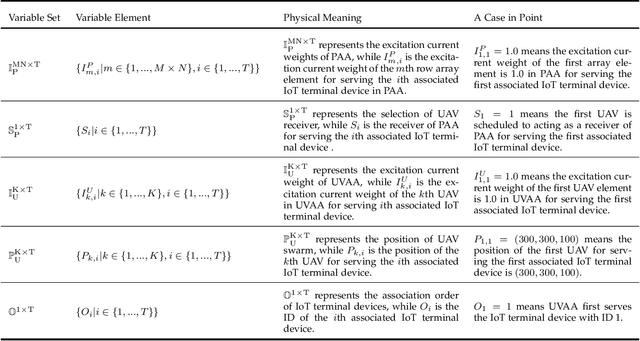
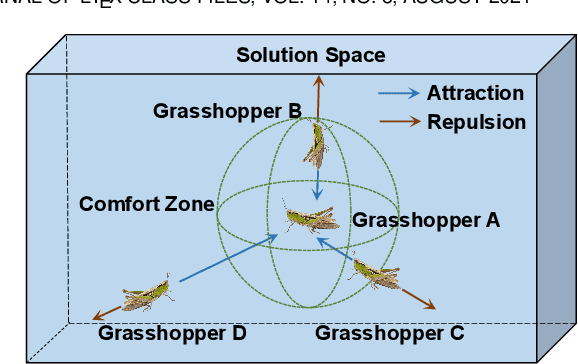

Unmanned aerial vehicles (UAVs) as aerial relays are practically appealing for assisting Internet of Things (IoT) network. In this work, we aim to utilize the UAV swarm to assist the secure communication between the micro base station (MBS) equipped with the planar array antenna (PAA) and the IoT terminal devices by collaborative beamforming (CB), so as to counteract the effects of collusive eavesdropping attacks in time-domain. Specifically, we formulate a UAV swarm-enabled secure relay multi-objective optimization problem (US2RMOP) for simultaneously maximizing the achievable sum rate of associated IoT terminal devices, minimizing the achievable sum rate of the eavesdropper and minimizing the energy consumption of UAV swarm, by jointly optimizing the excitation current weights of both MBS and UAV swarm, the selection of the UAV receiver, the position of UAVs and user association order of IoT terminal devices. Furthermore, the formulated US2RMOP is proved to be a non-convex, NP-hard and large-scale optimization problem. Therefore, we propose an improved multi-objective grasshopper algorithm (IMOGOA) with some specific designs to address the problem. Simulation results exhibit the effectiveness of the proposed UAV swarm-enabled collaborative secure relay strategy and demonstrate the superiority of IMOGOA.
Compositional Learning in Transformer-Based Human-Object Interaction Detection
Aug 11, 2023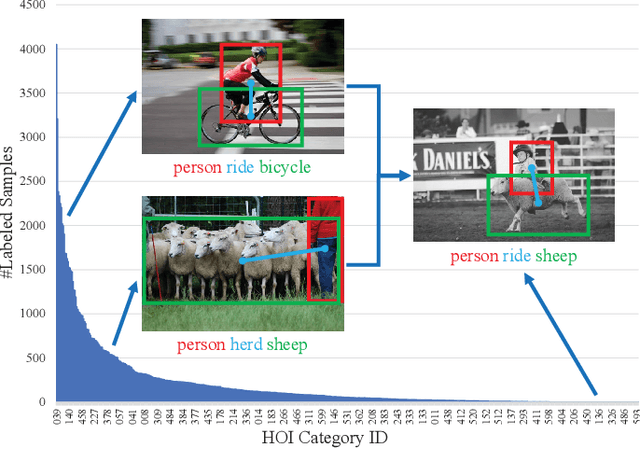
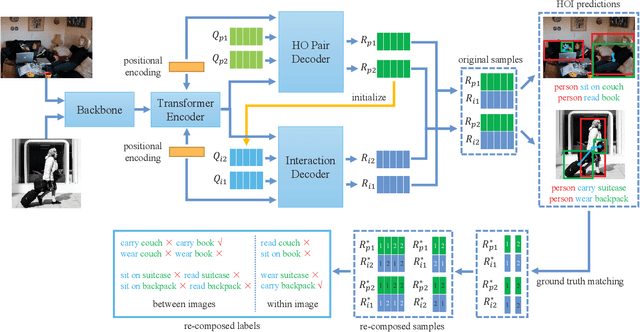

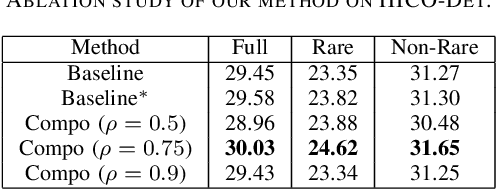
Human-object interaction (HOI) detection is an important part of understanding human activities and visual scenes. The long-tailed distribution of labeled instances is a primary challenge in HOI detection, promoting research in few-shot and zero-shot learning. Inspired by the combinatorial nature of HOI triplets, some existing approaches adopt the idea of compositional learning, in which object and action features are learned individually and re-composed as new training samples. However, these methods follow the CNN-based two-stage paradigm with limited feature extraction ability, and often rely on auxiliary information for better performance. Without introducing any additional information, we creatively propose a transformer-based framework for compositional HOI learning. Human-object pair representations and interaction representations are re-composed across different HOI instances, which involves richer contextual information and promotes the generalization of knowledge. Experiments show our simple but effective method achieves state-of-the-art performance, especially on rare HOI classes.
Uncertainty-Aware Cross-Modal Transfer Network for Sketch-Based 3D Shape Retrieval
Aug 11, 2023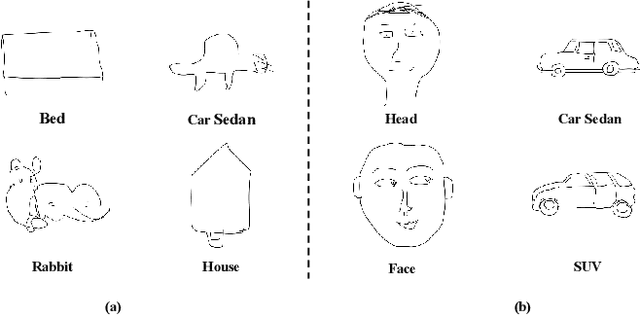
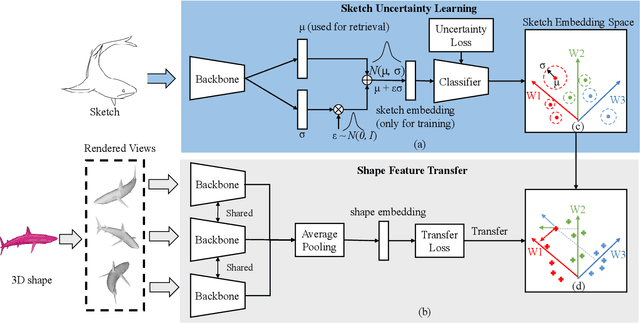
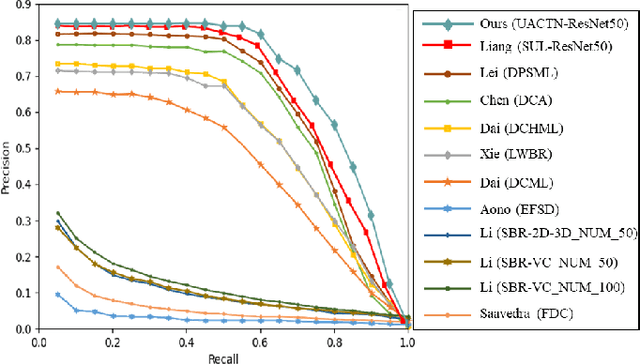
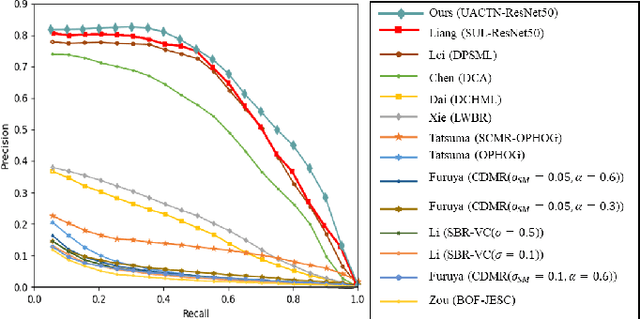
In recent years, sketch-based 3D shape retrieval has attracted growing attention. While many previous studies have focused on cross-modal matching between hand-drawn sketches and 3D shapes, the critical issue of how to handle low-quality and noisy samples in sketch data has been largely neglected. This paper presents an uncertainty-aware cross-modal transfer network (UACTN) that addresses this issue. UACTN decouples the representation learning of sketches and 3D shapes into two separate tasks: classification-based sketch uncertainty learning and 3D shape feature transfer. We first introduce an end-to-end classification-based approach that simultaneously learns sketch features and uncertainty, allowing uncertainty to prevent overfitting noisy sketches by assigning different levels of importance to clean and noisy sketches. Then, 3D shape features are mapped into the pre-learned sketch embedding space for feature alignment. Extensive experiments and ablation studies on two benchmarks demonstrate the superiority of our proposed method compared to state-of-the-art methods.
Exposing the Troublemakers in Described Object Detection
Jul 24, 2023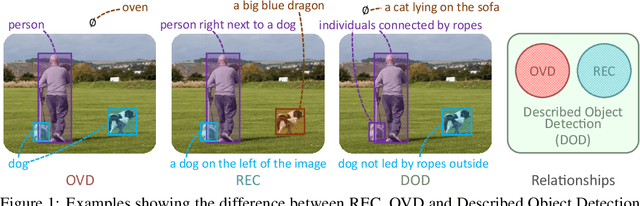

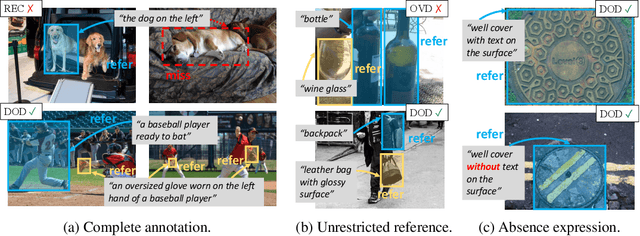
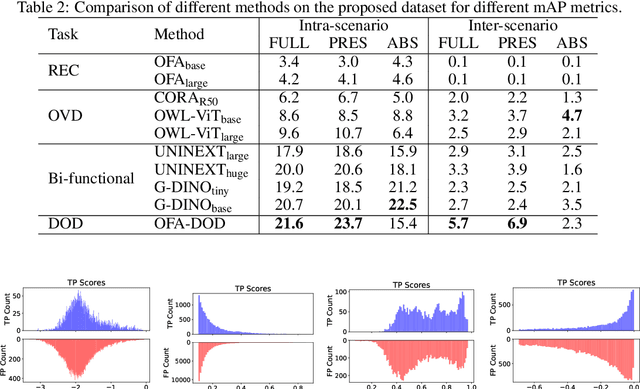
Detecting objects based on language descriptions is a popular task that includes Open-Vocabulary object Detection (OVD) and Referring Expression Comprehension (REC). In this paper, we advance them to a more practical setting called Described Object Detection (DOD) by expanding category names to flexible language expressions for OVD and overcoming the limitation of REC to only grounding the pre-existing object. We establish the research foundation for DOD tasks by constructing a Description Detection Dataset ($D^3$), featuring flexible language expressions and annotating all described objects without omission. By evaluating previous SOTA methods on $D^3$, we find some troublemakers that fail current REC, OVD, and bi-functional methods. REC methods struggle with confidence scores, rejecting negative instances, and multi-target scenarios, while OVD methods face constraints with long and complex descriptions. Recent bi-functional methods also do not work well on DOD due to their separated training procedures and inference strategies for REC and OVD tasks. Building upon the aforementioned findings, we propose a baseline that largely improves REC methods by reconstructing the training data and introducing a binary classification sub-task, outperforming existing methods. Data and code is available at https://github.com/shikras/d-cube.
EgoVM: Achieving Precise Ego-Localization using Lightweight Vectorized Maps
Jul 18, 2023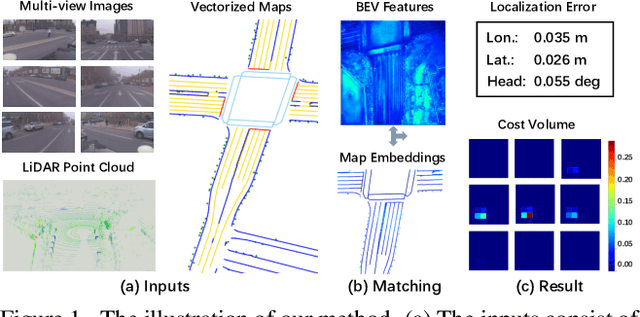

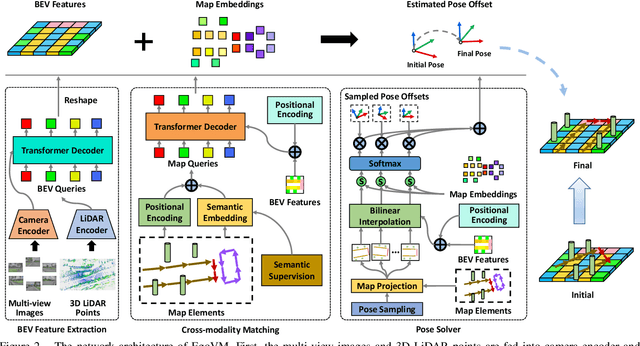

Accurate and reliable ego-localization is critical for autonomous driving. In this paper, we present EgoVM, an end-to-end localization network that achieves comparable localization accuracy to prior state-of-the-art methods, but uses lightweight vectorized maps instead of heavy point-based maps. To begin with, we extract BEV features from online multi-view images and LiDAR point cloud. Then, we employ a set of learnable semantic embeddings to encode the semantic types of map elements and supervise them with semantic segmentation, to make their feature representation consistent with BEV features. After that, we feed map queries, composed of learnable semantic embeddings and coordinates of map elements, into a transformer decoder to perform cross-modality matching with BEV features. Finally, we adopt a robust histogram-based pose solver to estimate the optimal pose by searching exhaustively over candidate poses. We comprehensively validate the effectiveness of our method using both the nuScenes dataset and a newly collected dataset. The experimental results show that our method achieves centimeter-level localization accuracy, and outperforms existing methods using vectorized maps by a large margin. Furthermore, our model has been extensively tested in a large fleet of autonomous vehicles under various challenging urban scenes.
Category Query Learning for Human-Object Interaction Classification
Mar 24, 2023
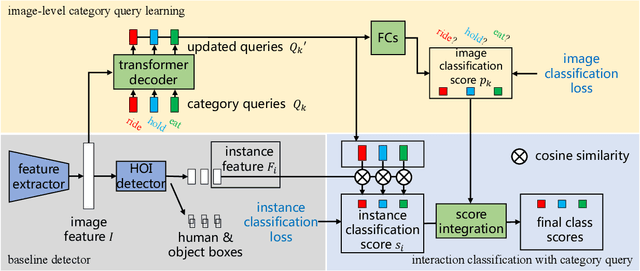
Unlike most previous HOI methods that focus on learning better human-object features, we propose a novel and complementary approach called category query learning. Such queries are explicitly associated to interaction categories, converted to image specific category representation via a transformer decoder, and learnt via an auxiliary image-level classification task. This idea is motivated by an earlier multi-label image classification method, but is for the first time applied for the challenging human-object interaction classification task. Our method is simple, general and effective. It is validated on three representative HOI baselines and achieves new state-of-the-art results on two benchmarks.