 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTian Lin
Uncertainty-inspired Open Set Learning for Retinal Anomaly Identification
Apr 08, 2023
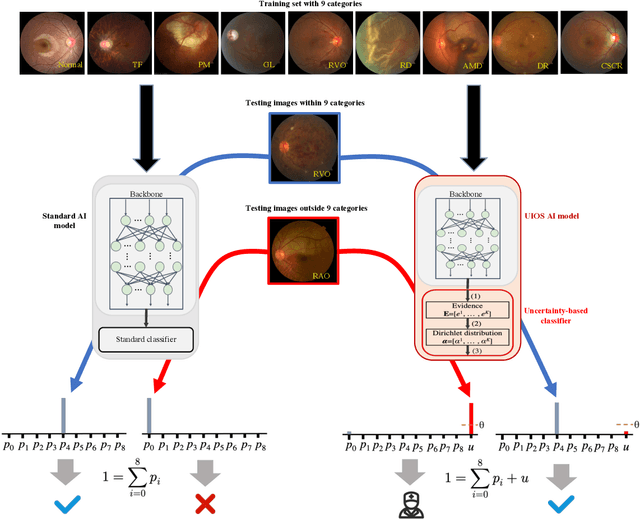

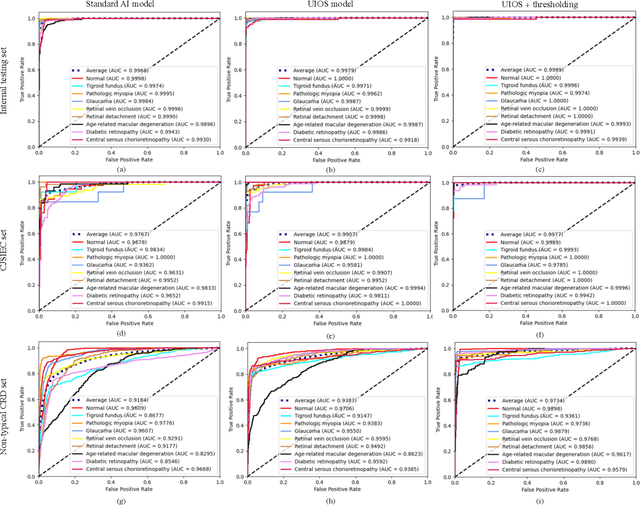
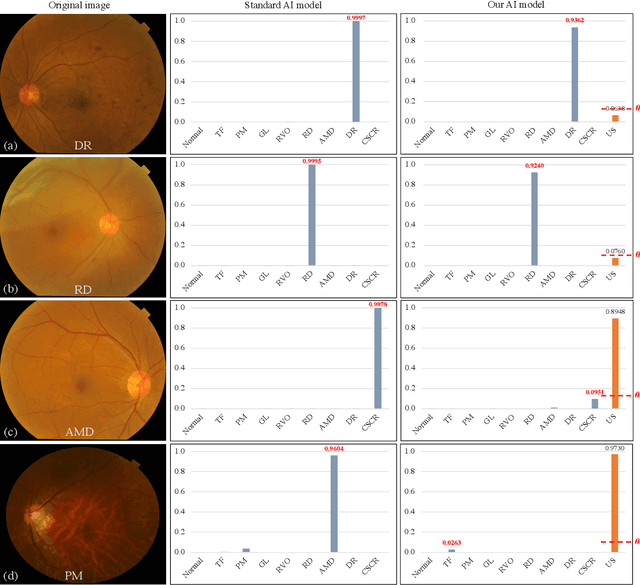
Failure to recognize samples from the classes unseen during training is a major limit of artificial intelligence (AI) in real-world implementation of retinal anomaly classification. To resolve this obstacle, we propose an uncertainty-inspired open-set (UIOS) model which was trained with fundus images of 9 common retinal conditions. Besides the probability of each category, UIOS also calculates an uncertainty score to express its confidence. Our UIOS model with thresholding strategy achieved an F1 score of 99.55%, 97.01% and 91.91% for the internal testing set, external testing set and non-typical testing set, respectively, compared to the F1 score of 92.20%, 80.69% and 64.74% by the standard AI model. Furthermore, UIOS correctly predicted high uncertainty scores, which prompted the need for a manual check, in the datasets of rare retinal diseases, low-quality fundus images, and non-fundus images. This work provides a robust method for real-world screening of retinal anomalies.
Reliable Multimodality Eye Disease Screening via Mixture of Student's t Distributions
Mar 17, 2023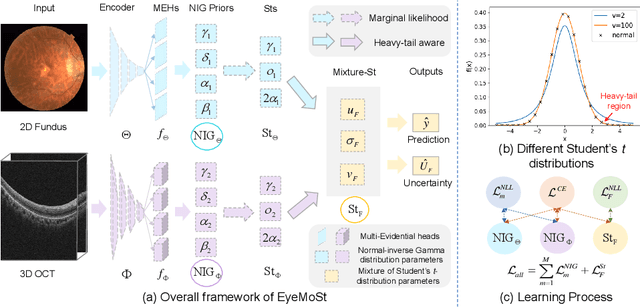

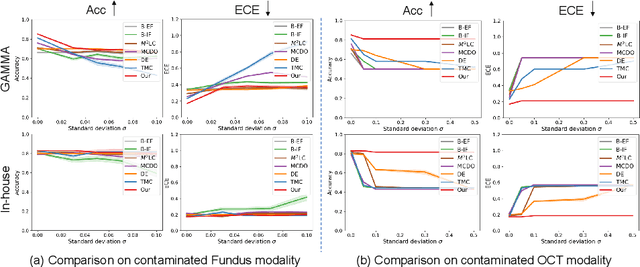
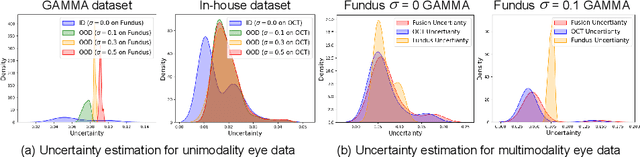
Multimodality eye disease screening is crucial in ophthalmology as it integrates information from diverse sources to complement their respective performances. However, the existing methods are weak in assessing the reliability of each unimodality, and directly fusing an unreliable modality may cause screening errors. To address this issue, we introduce a novel multimodality evidential fusion pipeline for eye disease screening, EyeMoS$t$, which provides a measure of confidence for unimodality and elegantly integrates the multimodality information from a multi-distribution fusion perspective. Specifically, our model estimates both local uncertainty for unimodality and global uncertainty for the fusion modality to produce reliable classification results. More importantly, the proposed mixture of Student's $t$ distributions adaptively integrates different modalities to endow the model with heavy-tailed properties, increasing robustness and reliability. Our experimental findings on both public and in-house datasets show that our model is more reliable than current methods. Additionally, EyeMos$t$ has the potential ability to serve as a data quality discriminator, enabling reliable decision-making for multimodality eye disease screening.
Channel Estimation for BIOS-Assisted Multi-User MIMO Systems: A Heterogeneous Two-timescale Strategy
Feb 16, 2023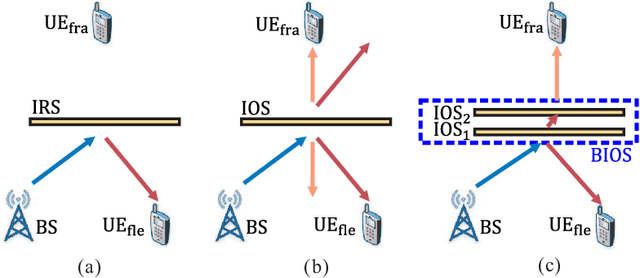
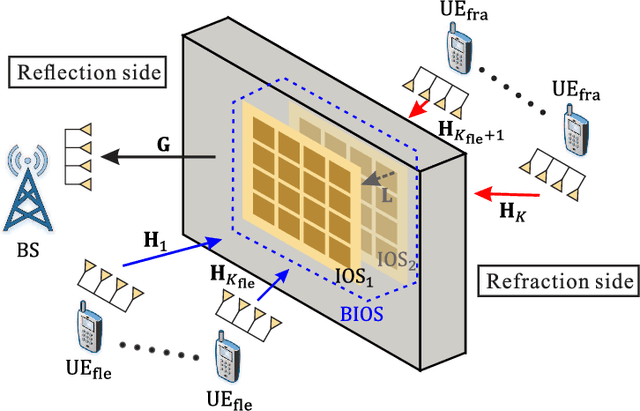

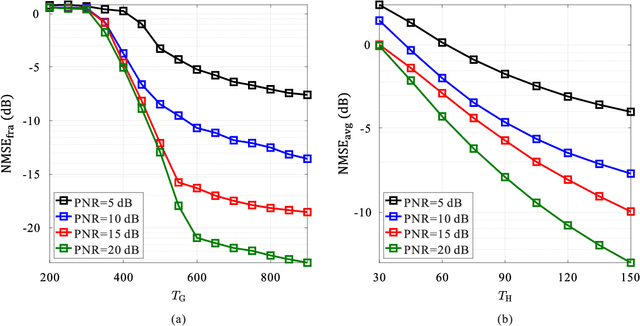
Bilayer intelligent omni-surface (BIOS) has recently attracted increasing attention due to its capability of independent beamforming on both reflection and refraction sides. However, its specific bilayer structure makes the channel estimation problem more challenging than the conventional intelligent reflecting surface (IRS) or intelligent omni-surface (IOS). In this paper, we investigate the channel estimation problem in the BIOS-assisted multi-user multiple-input multiple-output system. We find that in contrast to the IRS or IOS, where the forms of the cascaded channels of all user equipments (UEs) are the same, in the BIOS, those of the UEs on the reflection side are different from those on the refraction side, which is referred to as the heterogeneous channel property. By exploiting it along with the two-timescale and sparsity properties of channels and applying the manifold optimization method, we propose an efficient channel estimation scheme to reduce the training overhead in the BIOS-assisted system. Moreover, we investigate the joint optimization of base station digital beamforming and BIOS passive analog beamforming. Simulation results show that the proposed estimation scheme can significantly reduce the training overhead with competitive estimation quality, and thus keeps the performance advantage of BIOS over IRS and IOS with imperfect channel state information.
Channel Estimation for IRS-Assisted Millimeter-Wave MIMO Systems: Sparsity-Inspired Approaches
Jul 24, 2021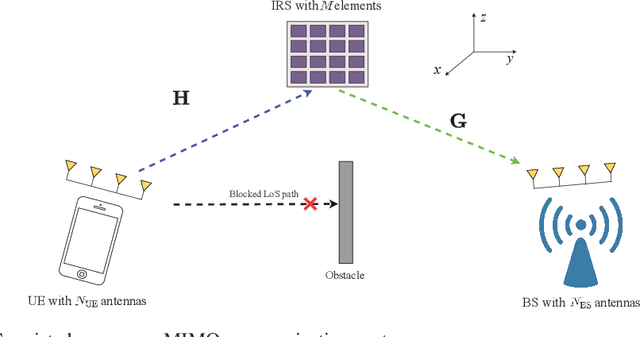
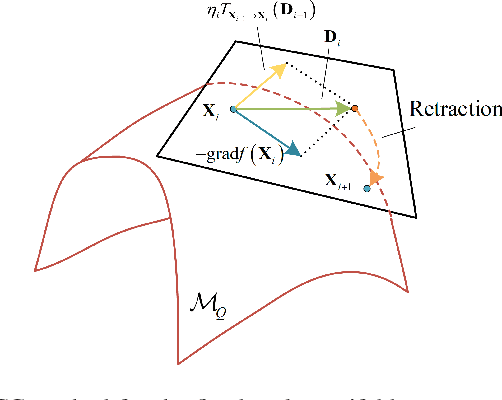
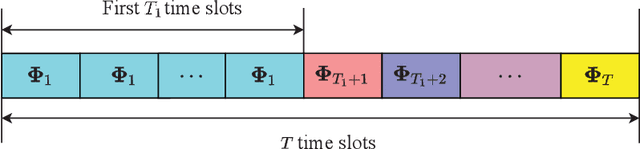

Due to their ability to create favorable line-of-sight (LoS) propagation environments, intelligent reflecting surfaces (IRSs) are regarded as promising enablers for future millimeter-wave (mm-wave) wireless communication. In this paper, we investigate channel estimation for IRS-assisted mm-wave multiple-input multiple-output (MIMO) {\color{black}wireles}s systems. By leveraging the sparsity of mm-wave channels in the angular domain, we formulate the channel estimation problem as an $\ell_1$-norm regularized optimization problem with fixed-rank constraints. To tackle the non-convexity of the formulated problem, an efficient algorithm is proposed by capitalizing on alternating minimization and manifold optimization (MO), which yields a locally optimal solution. To further reduce the computational complexity of the estimation algorithm, we propose a compressive sensing- (CS-) based channel estimation approach. In particular, a three-stage estimation protocol is put forward where the subproblem in each stage can be solved via low-complexity CS methods. Furthermore, based on the acquired channel state information (CSI) of the cascaded channel, we design a passive beamforming algorithm for maximization of the spectral efficiency. Simulation results reveal that the proposed MO-based estimation (MO-EST) and beamforming algorithms significantly outperform two benchmark schemes while the CS-based estimation (CS-EST) algorithm strikes a balance between performance and complexity. In addition, we demonstrate the robustness of the MO-EST algorithm with respect to imperfect knowledge of the sparsity level of the channels, which is crucial for practical implementations.
Neural Logic Machines
Apr 26, 2019
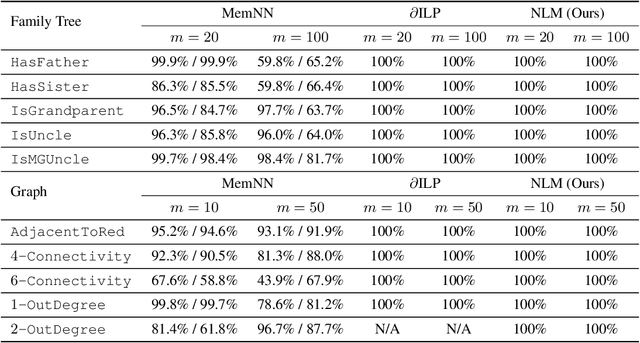
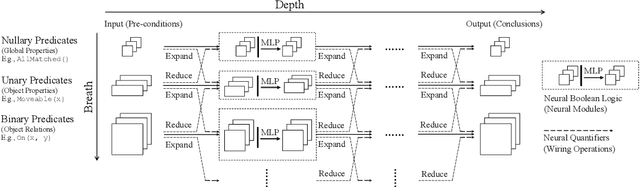
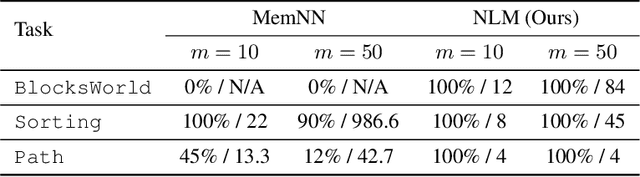
We propose the Neural Logic Machine (NLM), a neural-symbolic architecture for both inductive learning and logic reasoning. NLMs exploit the power of both neural networks---as function approximators, and logic programming---as a symbolic processor for objects with properties, relations, logic connectives, and quantifiers. After being trained on small-scale tasks (such as sorting short arrays), NLMs can recover lifted rules, and generalize to large-scale tasks (such as sorting longer arrays). In our experiments, NLMs achieve perfect generalization in a number of tasks, from relational reasoning tasks on the family tree and general graphs, to decision making tasks including sorting arrays, finding shortest paths, and playing the blocks world. Most of these tasks are hard to accomplish for neural networks or inductive logic programming alone.
Doubly Sparse: Sparse Mixture of Sparse Experts for Efficient Softmax Inference
Jan 30, 2019
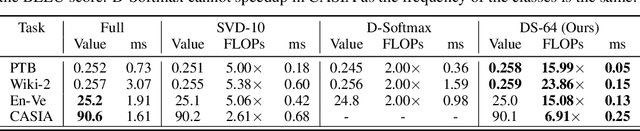
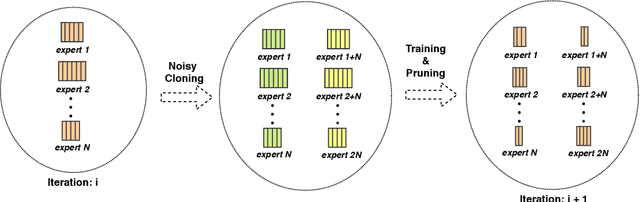
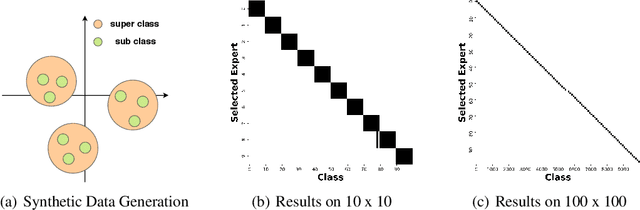
Computations for the softmax function are significantly expensive when the number of output classes is large. In this paper, we present a novel softmax inference speedup method, Doubly Sparse Softmax (DS-Softmax), that leverages sparse mixture of sparse experts to efficiently retrieve top-k classes. Different from most existing methods that require and approximate a fixed softmax, our method is learning-based and can adapt softmax weights for a better approximation. In particular, our method learns a two-level hierarchy which divides entire output class space into several partially overlapping experts. Each expert is sparse and only contains a subset of output classes. To find top-k classes, a sparse mixture enables us to find the most probable expert quickly, and the sparse expert enables us to search within a small-scale softmax. We empirically conduct evaluation on several real-world tasks (including neural machine translation, language modeling and image classification) and demonstrate that significant computation reductions can be achieved without loss of performance.
Robust Influence Maximization
Jun 12, 2016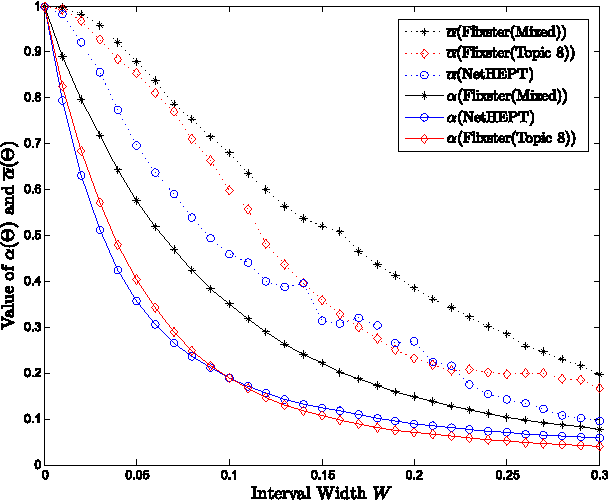
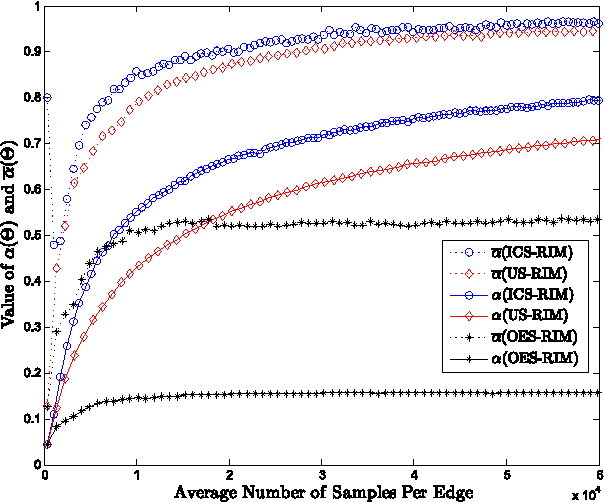
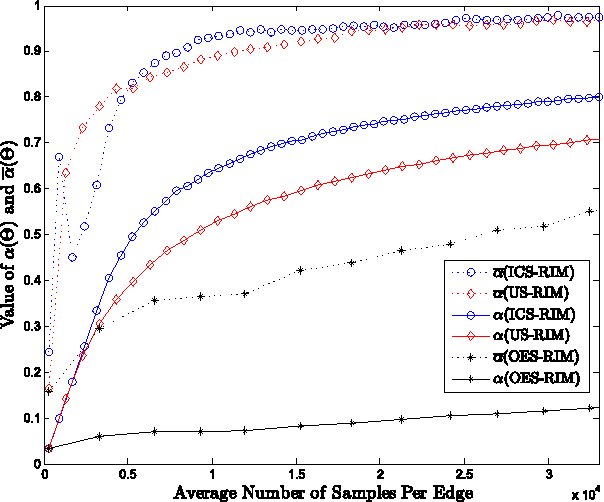
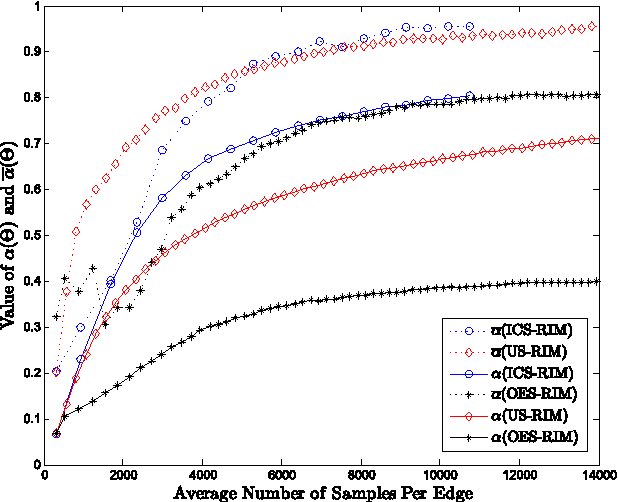
In this paper, we address the important issue of uncertainty in the edge influence probability estimates for the well studied influence maximization problem --- the task of finding $k$ seed nodes in a social network to maximize the influence spread. We propose the problem of robust influence maximization, which maximizes the worst-case ratio between the influence spread of the chosen seed set and the optimal seed set, given the uncertainty of the parameter input. We design an algorithm that solves this problem with a solution-dependent bound. We further study uniform sampling and adaptive sampling methods to effectively reduce the uncertainty on parameters and improve the robustness of the influence maximization task. Our empirical results show that parameter uncertainty may greatly affect influence maximization performance and prior studies that learned influence probabilities could lead to poor performance in robust influence maximization due to relatively large uncertainty in parameter estimates, and information cascade based adaptive sampling method may be an effective way to improve the robustness of influence maximization.
Real-time Topic-aware Influence Maximization Using Preprocessing
Nov 21, 2014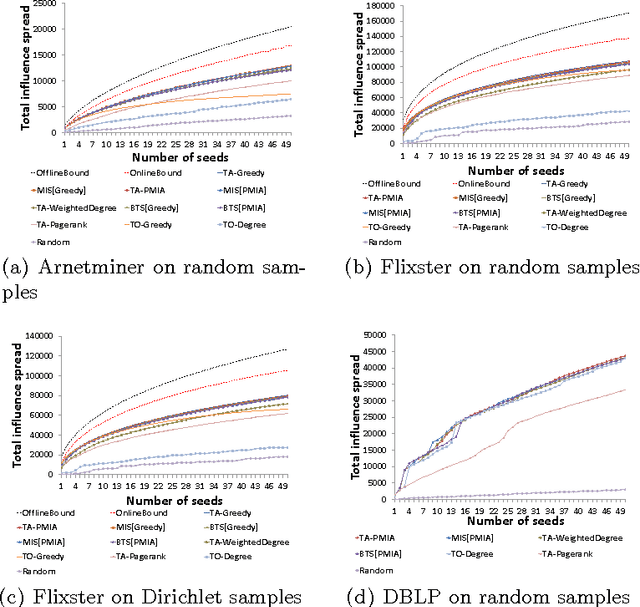
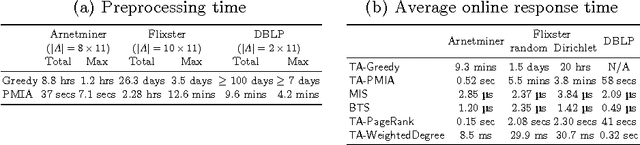
Influence maximization is the task of finding a set of seed nodes in a social network such that the influence spread of these seed nodes based on certain influence diffusion model is maximized. Topic-aware influence diffusion models have been recently proposed to address the issue that influence between a pair of users are often topic-dependent and information, ideas, innovations etc. being propagated in networks (referred collectively as items in this paper) are typically mixtures of topics. In this paper, we focus on the topic-aware influence maximization task. In particular, we study preprocessing methods for these topics to avoid redoing influence maximization for each item from scratch. We explore two preprocessing algorithms with theoretical justifications. Our empirical results on data obtained in a couple of existing studies demonstrate that one of our algorithms stands out as a strong candidate providing microsecond online response time and competitive influence spread, with reasonable preprocessing effort.