 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXueru Zhang
Counterfactually Fair Representation
Nov 09, 2023
The use of machine learning models in high-stake applications (e.g., healthcare, lending, college admission) has raised growing concerns due to potential biases against protected social groups. Various fairness notions and methods have been proposed to mitigate such biases. In this work, we focus on Counterfactual Fairness (CF), a fairness notion that is dependent on an underlying causal graph and first proposed by Kusner \textit{et al.}~\cite{kusner2017counterfactual}; it requires that the outcome an individual perceives is the same in the real world as it would be in a "counterfactual" world, in which the individual belongs to another social group. Learning fair models satisfying CF can be challenging. It was shown in \cite{kusner2017counterfactual} that a sufficient condition for satisfying CF is to \textbf{not} use features that are descendants of sensitive attributes in the causal graph. This implies a simple method that learns CF models only using non-descendants of sensitive attributes while eliminating all descendants. Although several subsequent works proposed methods that use all features for training CF models, there is no theoretical guarantee that they can satisfy CF. In contrast, this work proposes a new algorithm that trains models using all the available features. We theoretically and empirically show that models trained with this method can satisfy CF\footnote{The code repository for this work can be found in \url{https://github.com/osu-srml/CF_Representation_Learning}}.
Loss Balancing for Fair Supervised Learning
Nov 07, 2023Supervised learning models have been used in various domains such as lending, college admission, face recognition, natural language processing, etc. However, they may inherit pre-existing biases from training data and exhibit discrimination against protected social groups. Various fairness notions have been proposed to address unfairness issues. In this work, we focus on Equalized Loss (EL), a fairness notion that requires the expected loss to be (approximately) equalized across different groups. Imposing EL on the learning process leads to a non-convex optimization problem even if the loss function is convex, and the existing fair learning algorithms cannot properly be adopted to find the fair predictor under the EL constraint. This paper introduces an algorithm that can leverage off-the-shelf convex programming tools (e.g., CVXPY) to efficiently find the global optimum of this non-convex optimization. In particular, we propose the ELminimizer algorithm, which finds the optimal fair predictor under EL by reducing the non-convex optimization to a sequence of convex optimization problems. We theoretically prove that our algorithm finds the global optimal solution under certain conditions. Then, we support our theoretical results through several empirical studies.
Federated Learning with Reduced Information Leakage and Computation
Oct 10, 2023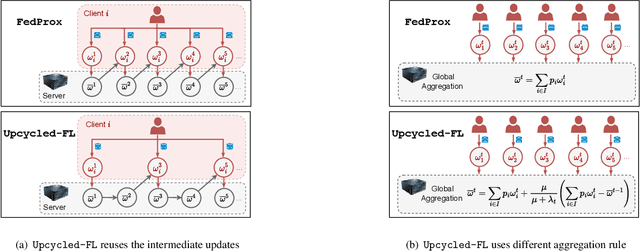
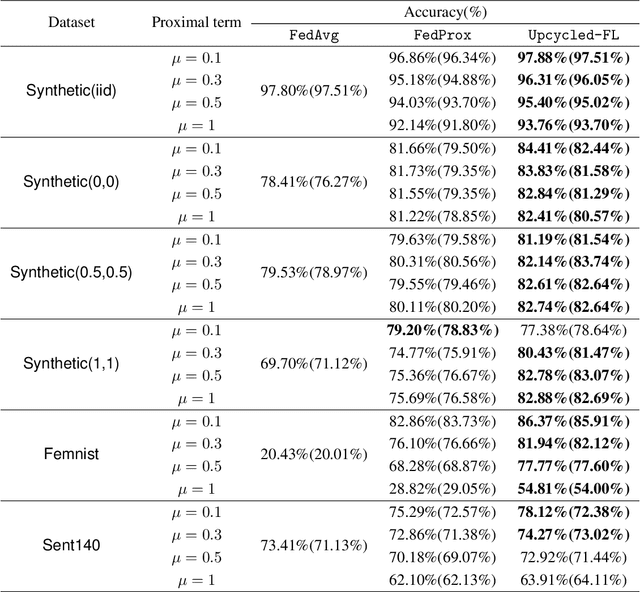
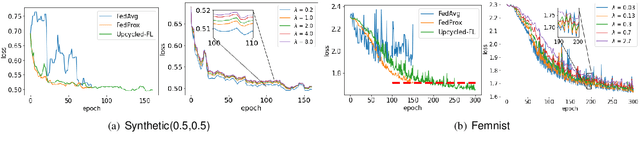
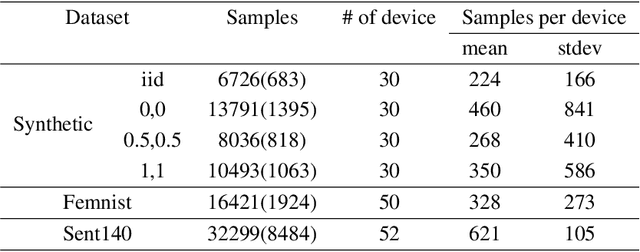
Federated learning (FL) is a distributed learning paradigm that allows multiple decentralized clients to collaboratively learn a common model without sharing local data. Although local data is not exposed directly, privacy concerns nonetheless exist as clients' sensitive information can be inferred from intermediate computations. Moreover, such information leakage accumulates substantially over time as the same data is repeatedly used during the iterative learning process. As a result, it can be particularly difficult to balance the privacy-accuracy trade-off when designing privacy-preserving FL algorithms. In this paper, we introduce Upcycled-FL, a novel federated learning framework with first-order approximation applied at every even iteration. Under this framework, half of the FL updates incur no information leakage and require much less computation. We first conduct the theoretical analysis on the convergence (rate) of Upcycled-FL, and then apply perturbation mechanisms to preserve privacy. Experiments on real-world data show that Upcycled-FL consistently outperforms existing methods over heterogeneous data, and significantly improves privacy-accuracy trade-off while reducing 48% of the training time on average.
Performative Federated Learning: A Solution to Model-Dependent and Heterogeneous Distribution Shifts
May 08, 2023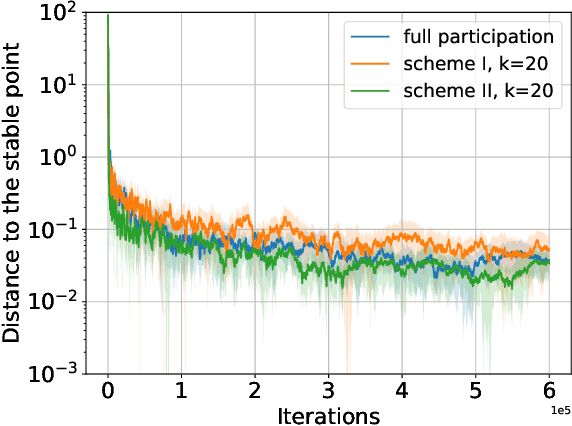
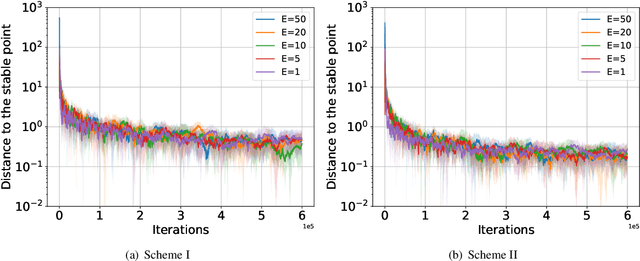
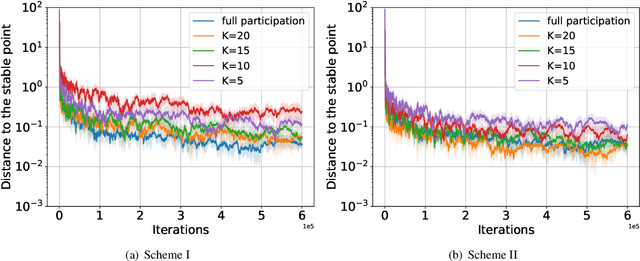
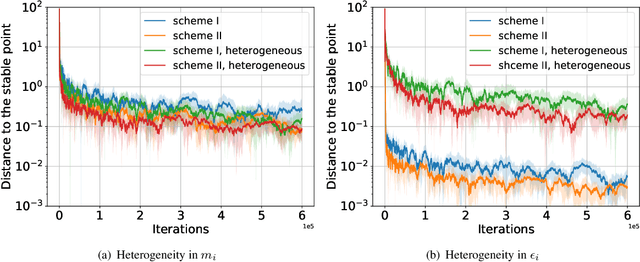
We consider a federated learning (FL) system consisting of multiple clients and a server, where the clients aim to collaboratively learn a common decision model from their distributed data. Unlike the conventional FL framework that assumes the client's data is static, we consider scenarios where the clients' data distributions may be reshaped by the deployed decision model. In this work, we leverage the idea of distribution shift mappings in performative prediction to formalize this model-dependent data distribution shift and propose a performative federated learning framework. We first introduce necessary and sufficient conditions for the existence of a unique performative stable solution and characterize its distance to the performative optimal solution. Then we propose the performative FedAvg algorithm and show that it converges to the performative stable solution at a rate of O(1/T) under both full and partial participation schemes. In particular, we use novel proof techniques and show how the clients' heterogeneity influences the convergence. Numerical results validate our analysis and provide valuable insights into real-world applications.
Fairness and Accuracy under Domain Generalization
Jan 30, 2023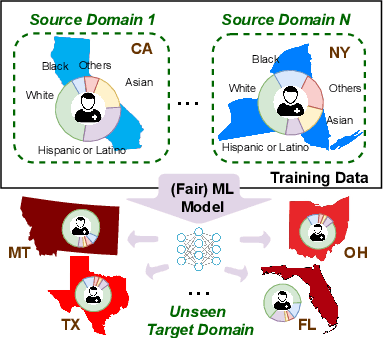
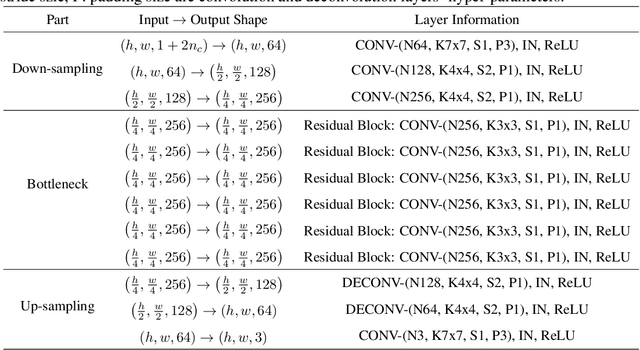
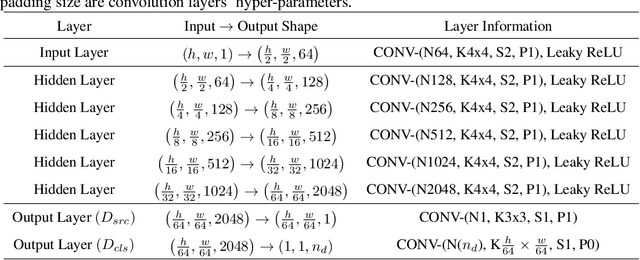
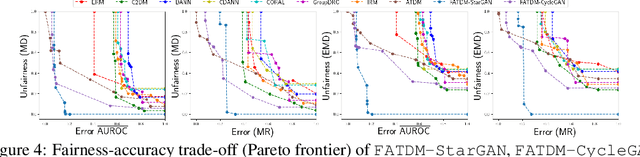
As machine learning (ML) algorithms are increasingly used in high-stakes applications, concerns have arisen that they may be biased against certain social groups. Although many approaches have been proposed to make ML models fair, they typically rely on the assumption that data distributions in training and deployment are identical. Unfortunately, this is commonly violated in practice and a model that is fair during training may lead to an unexpected outcome during its deployment. Although the problem of designing robust ML models under dataset shifts has been widely studied, most existing works focus only on the transfer of accuracy. In this paper, we study the transfer of both fairness and accuracy under domain generalization where the data at test time may be sampled from never-before-seen domains. We first develop theoretical bounds on the unfairness and expected loss at deployment, and then derive sufficient conditions under which fairness and accuracy can be perfectly transferred via invariant representation learning. Guided by this, we design a learning algorithm such that fair ML models learned with training data still have high fairness and accuracy when deployment environments change. Experiments on real-world data validate the proposed algorithm. Model implementation is available at https://github.com/pth1993/FATDM.
Fair Sequential Selection Using Supervised Learning Models
Oct 26, 2021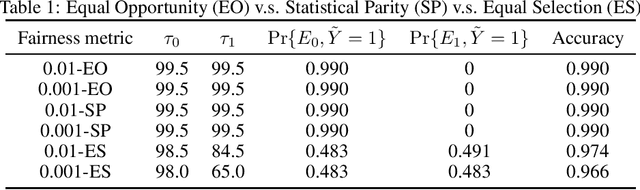
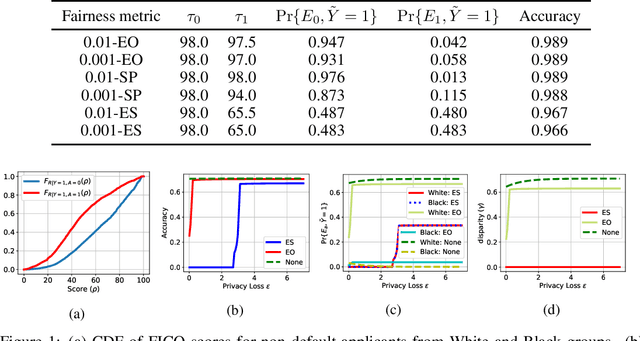
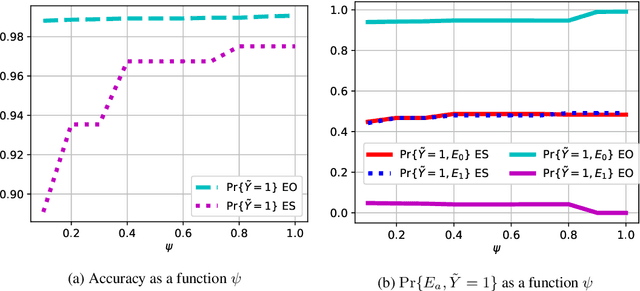
We consider a selection problem where sequentially arrived applicants apply for a limited number of positions/jobs. At each time step, a decision maker accepts or rejects the given applicant using a pre-trained supervised learning model until all the vacant positions are filled. In this paper, we discuss whether the fairness notions (e.g., equal opportunity, statistical parity, etc.) that are commonly used in classification problems are suitable for the sequential selection problems. In particular, we show that even with a pre-trained model that satisfies the common fairness notions, the selection outcomes may still be biased against certain demographic groups. This observation implies that the fairness notions used in classification problems are not suitable for a selection problem where the applicants compete for a limited number of positions. We introduce a new fairness notion, ``Equal Selection (ES),'' suitable for sequential selection problems and propose a post-processing approach to satisfy the ES fairness notion. We also consider a setting where the applicants have privacy concerns, and the decision maker only has access to the noisy version of sensitive attributes. In this setting, we can show that the perfect ES fairness can still be attained under certain conditions.
Cardiac Complication Risk Profiling for Cancer Survivors via Multi-View Multi-Task Learning
Sep 25, 2021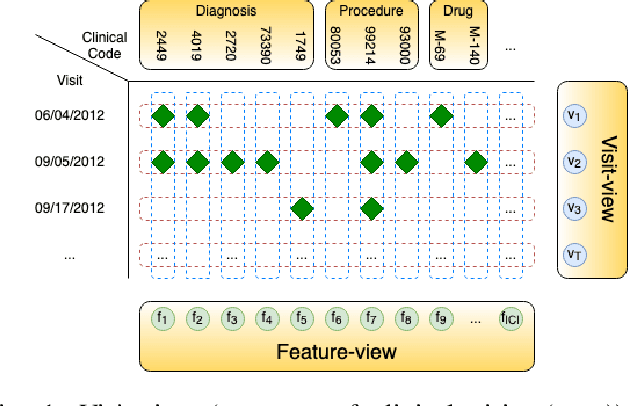
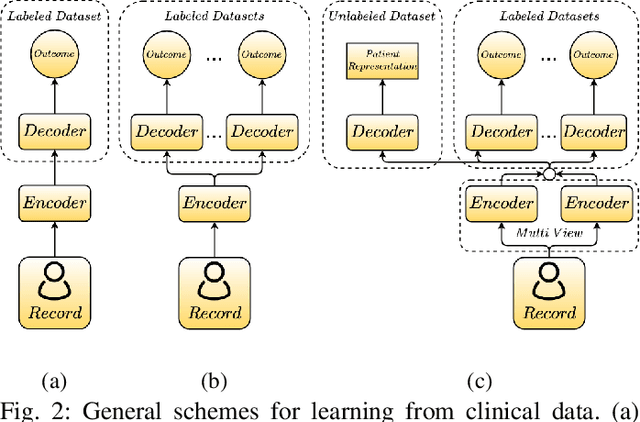
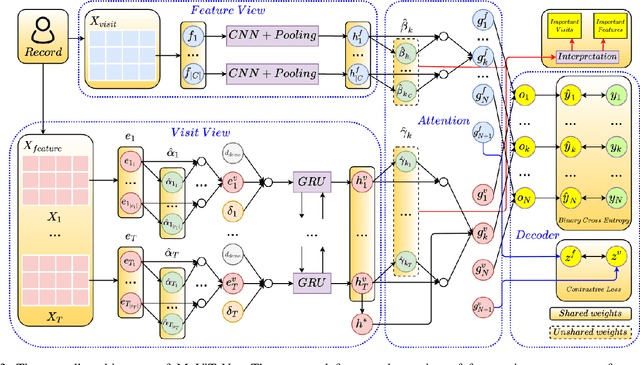
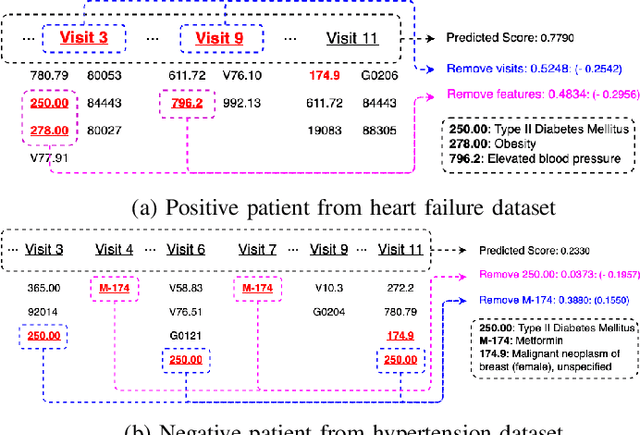
Complication risk profiling is a key challenge in the healthcare domain due to the complex interaction between heterogeneous entities (e.g., visit, disease, medication) in clinical data. With the availability of real-world clinical data such as electronic health records and insurance claims, many deep learning methods are proposed for complication risk profiling. However, these existing methods face two open challenges. First, data heterogeneity relates to those methods leveraging clinical data from a single view only while the data can be considered from multiple views (e.g., sequence of clinical visits, set of clinical features). Second, generalized prediction relates to most of those methods focusing on single-task learning, whereas each complication onset is predicted independently, leading to suboptimal models. We propose a multi-view multi-task network (MuViTaNet) for predicting the onset of multiple complications to tackle these issues. In particular, MuViTaNet complements patient representation by using a multi-view encoder to effectively extract information by considering clinical data as both sequences of clinical visits and sets of clinical features. In addition, it leverages additional information from both related labeled and unlabeled datasets to generate more generalized representations by using a new multi-task learning scheme for making more accurate predictions. The experimental results show that MuViTaNet outperforms existing methods for profiling the development of cardiac complications in breast cancer survivors. Furthermore, thanks to its multi-view multi-task architecture, MuViTaNet also provides an effective mechanism for interpreting its predictions in multiple perspectives, thereby helping clinicians discover the underlying mechanism triggering the onset and for making better clinical treatments in real-world scenarios.
Improving Fairness and Privacy in Selection Problems
Dec 07, 2020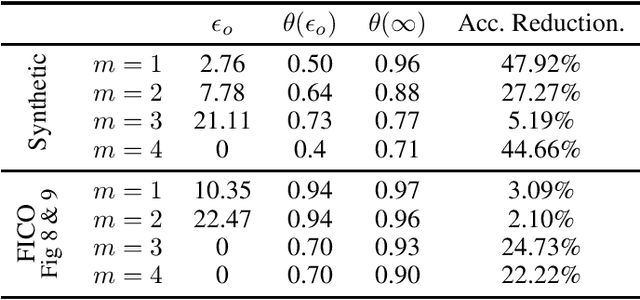
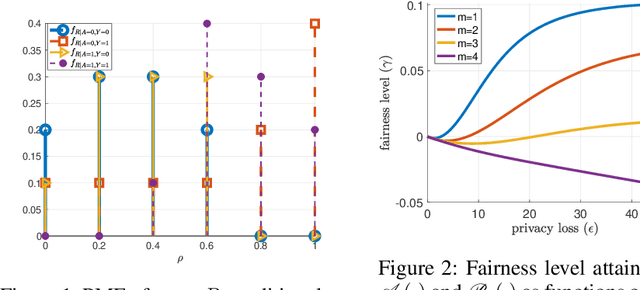

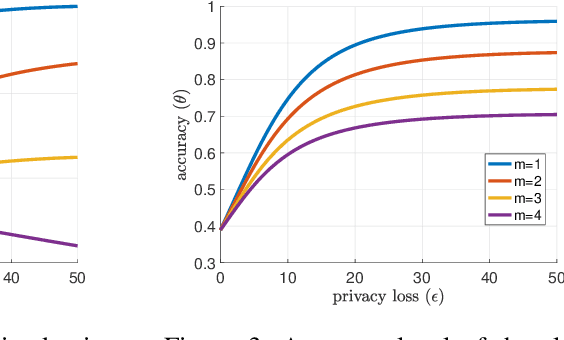
Supervised learning models have been increasingly used for making decisions about individuals in applications such as hiring, lending, and college admission. These models may inherit pre-existing biases from training datasets and discriminate against protected attributes (e.g., race or gender). In addition to unfairness, privacy concerns also arise when the use of models reveals sensitive personal information. Among various privacy notions, differential privacy has become popular in recent years. In this work, we study the possibility of using a differentially private exponential mechanism as a post-processing step to improve both fairness and privacy of supervised learning models. Unlike many existing works, we consider a scenario where a supervised model is used to select a limited number of applicants as the number of available positions is limited. This assumption is well-suited for various scenarios, such as job application and college admission. We use ``equal opportunity'' as the fairness notion and show that the exponential mechanisms can make the decision-making process perfectly fair. Moreover, the experiments on real-world datasets show that the exponential mechanism can improve both privacy and fairness, with a slight decrease in accuracy compared to the model without post-processing.
How Do Fair Decisions Fare in Long-term Qualification?
Oct 21, 2020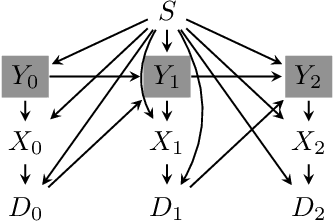
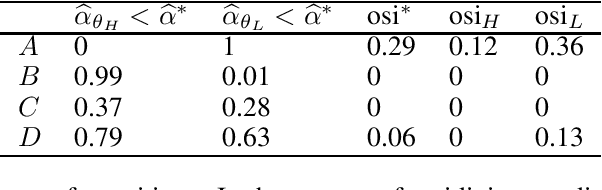
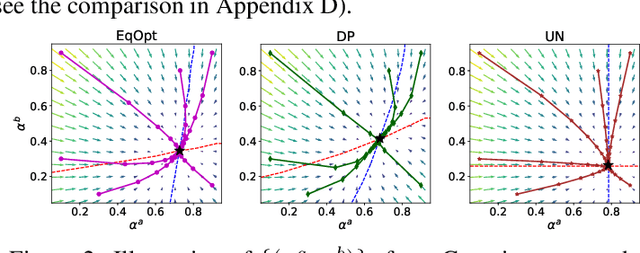

Although many fairness criteria have been proposed for decision making, their long-term impact on the well-being of a population remains unclear. In this work, we study the dynamics of population qualification and algorithmic decisions under a partially observed Markov decision problem setting. By characterizing the equilibrium of such dynamics, we analyze the long-term impact of static fairness constraints on the equality and improvement of group well-being. Our results show that static fairness constraints can either promote equality or exacerbate disparity depending on the driving factor of qualification transitions and the effect of sensitive attributes on feature distributions. We also consider possible interventions that can effectively improve group qualification or promote equality of group qualification. Our theoretical results and experiments on static real-world datasets with simulated dynamics show that our framework can be used to facilitate social science studies.
Fairness in Learning-Based Sequential Decision Algorithms: A Survey
Jan 14, 2020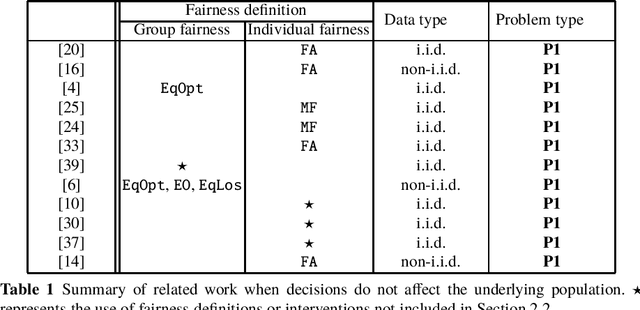
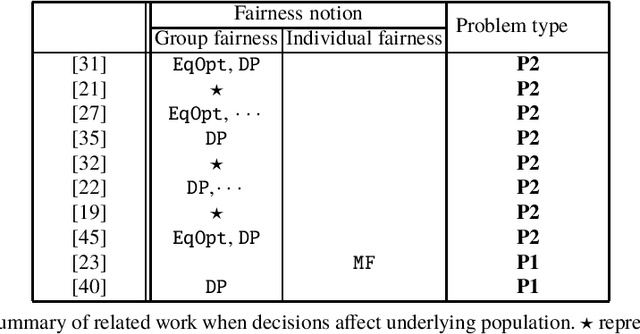
Algorithmic fairness in decision-making has been studied extensively in static settings where one-shot decisions are made on tasks such as classification. However, in practice most decision-making processes are of a sequential nature, where decisions made in the past may have an impact on future data. This is particularly the case when decisions affect the individuals or users generating the data used for future decisions. In this survey, we review existing literature on the fairness of data-driven sequential decision-making. We will focus on two types of sequential decisions: (1) past decisions have no impact on the underlying user population and thus no impact on future data; (2) past decisions have an impact on the underlying user population and therefore the future data, which can then impact future decisions. In each case the impact of various fairness interventions on the underlying population is examined.