 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunxiao Shi
Parameter Hierarchical Optimization for Visible-Infrared Person Re-Identification
Apr 11, 2024
Visible-infrared person re-identification (VI-reID) aims at matching cross-modality pedestrian images captured by disjoint visible or infrared cameras. Existing methods alleviate the cross-modality discrepancies via designing different kinds of network architectures. Different from available methods, in this paper, we propose a novel parameter optimizing paradigm, parameter hierarchical optimization (PHO) method, for the task of VI-ReID. It allows part of parameters to be directly optimized without any training, which narrows the search space of parameters and makes the whole network more easier to be trained. Specifically, we first divide the parameters into different types, and then introduce a self-adaptive alignment strategy (SAS) to automatically align the visible and infrared images through transformation. Considering that features in different dimension have varying importance, we develop an auto-weighted alignment learning (AAL) module that can automatically weight features according to their importance. Importantly, in the alignment process of SAS and AAL, all the parameters are immediately optimized with optimization principles rather than training the whole network, which yields a better parameter training manner. Furthermore, we establish the cross-modality consistent learning (CCL) loss to extract discriminative person representations with translation consistency. We provide both theoretical justification and empirical evidence that our proposed PHO method outperform existing VI-reID approaches.
FutureDepth: Learning to Predict the Future Improves Video Depth Estimation
Mar 19, 2024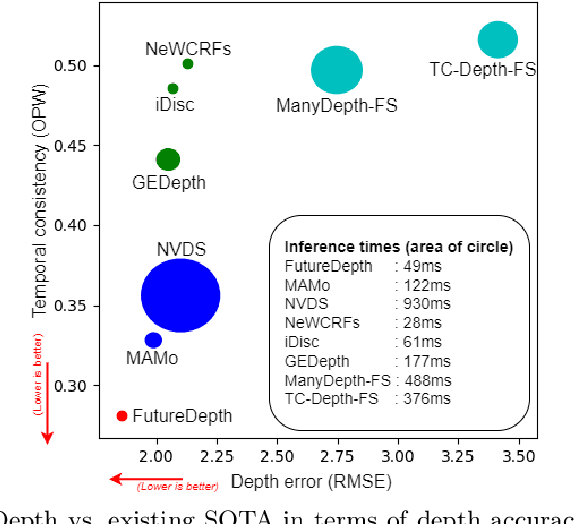
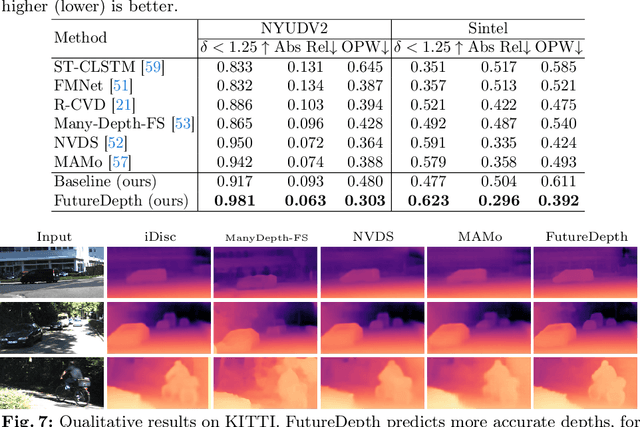
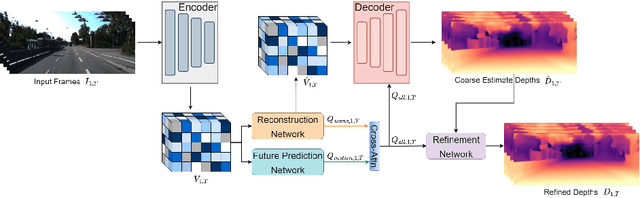
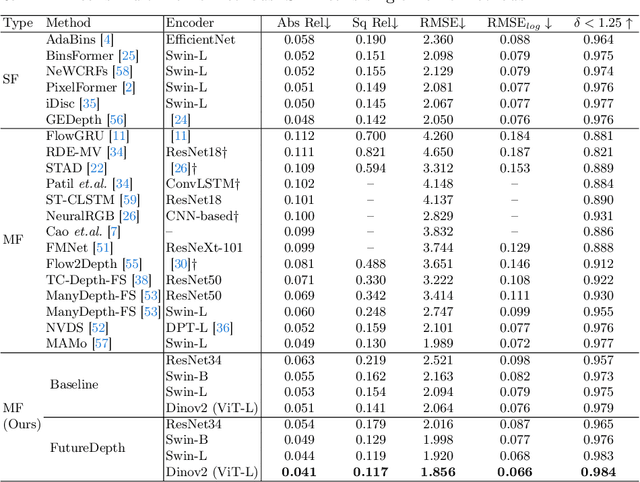
In this paper, we propose a novel video depth estimation approach, FutureDepth, which enables the model to implicitly leverage multi-frame and motion cues to improve depth estimation by making it learn to predict the future at training. More specifically, we propose a future prediction network, F-Net, which takes the features of multiple consecutive frames and is trained to predict multi-frame features one time step ahead iteratively. In this way, F-Net learns the underlying motion and correspondence information, and we incorporate its features into the depth decoding process. Additionally, to enrich the learning of multiframe correspondence cues, we further leverage a reconstruction network, R-Net, which is trained via adaptively masked auto-encoding of multiframe feature volumes. At inference time, both F-Net and R-Net are used to produce queries to work with the depth decoder, as well as a final refinement network. Through extensive experiments on several benchmarks, i.e., NYUDv2, KITTI, DDAD, and Sintel, which cover indoor, driving, and open-domain scenarios, we show that FutureDepth significantly improves upon baseline models, outperforms existing video depth estimation methods, and sets new state-of-the-art (SOTA) accuracy. Furthermore, FutureDepth is more efficient than existing SOTA video depth estimation models and has similar latencies when comparing to monocular models
DeCoTR: Enhancing Depth Completion with 2D and 3D Attentions
Mar 18, 2024
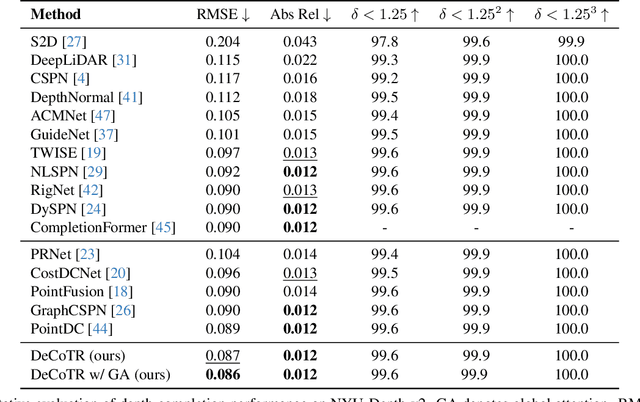
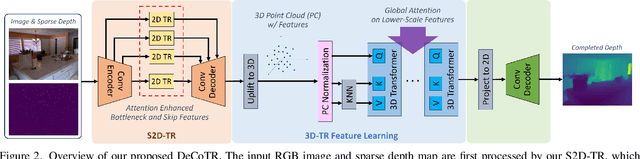
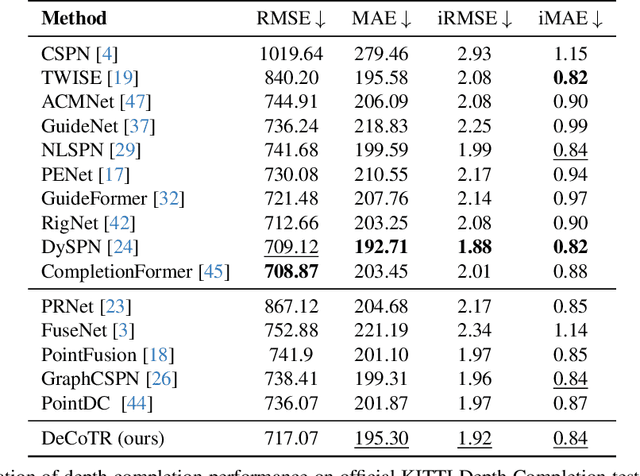
In this paper, we introduce a novel approach that harnesses both 2D and 3D attentions to enable highly accurate depth completion without requiring iterative spatial propagations. Specifically, we first enhance a baseline convolutional depth completion model by applying attention to 2D features in the bottleneck and skip connections. This effectively improves the performance of this simple network and sets it on par with the latest, complex transformer-based models. Leveraging the initial depths and features from this network, we uplift the 2D features to form a 3D point cloud and construct a 3D point transformer to process it, allowing the model to explicitly learn and exploit 3D geometric features. In addition, we propose normalization techniques to process the point cloud, which improves learning and leads to better accuracy than directly using point transformers off the shelf. Furthermore, we incorporate global attention on downsampled point cloud features, which enables long-range context while still being computationally feasible. We evaluate our method, DeCoTR, on established depth completion benchmarks, including NYU Depth V2 and KITTI, showcasing that it sets new state-of-the-art performance. We further conduct zero-shot evaluations on ScanNet and DDAD benchmarks and demonstrate that DeCoTR has superior generalizability compared to existing approaches.
Causal Disentanglement for Regulating Social Influence Bias in Social Recommendation
Mar 06, 2024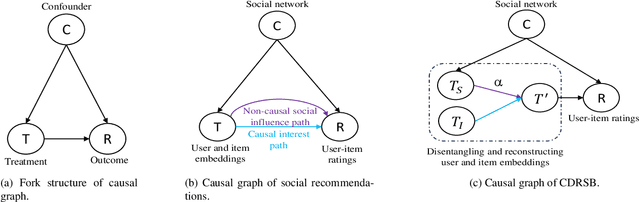

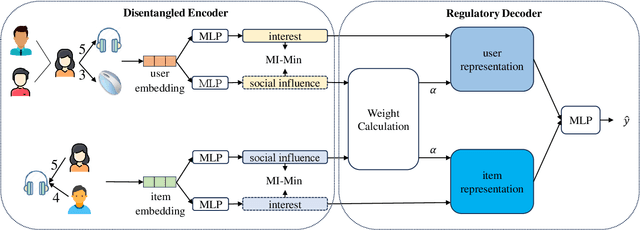
Social recommendation systems face the problem of social influence bias, which can lead to an overemphasis on recommending items that friends have interacted with. Addressing this problem is crucial, and existing methods often rely on techniques such as weight adjustment or leveraging unbiased data to eliminate this bias. However, we argue that not all biases are detrimental, i.e., some items recommended by friends may align with the user's interests. Blindly eliminating such biases could undermine these positive effects, potentially diminishing recommendation accuracy. In this paper, we propose a Causal Disentanglement-based framework for Regulating Social influence Bias in social recommendation, named CDRSB, to improve recommendation performance. From the perspective of causal inference, we find that the user social network could be regarded as a confounder between the user and item embeddings (treatment) and ratings (outcome). Due to the presence of this social network confounder, two paths exist from user and item embeddings to ratings: a non-causal social influence path and a causal interest path. Building upon this insight, we propose a disentangled encoder that focuses on disentangling user and item embeddings into interest and social influence embeddings. Mutual information-based objectives are designed to enhance the distinctiveness of these disentangled embeddings, eliminating redundant information. Additionally, a regulatory decoder that employs a weight calculation module to dynamically learn the weights of social influence embeddings for effectively regulating social influence bias has been designed. Experimental results on four large-scale real-world datasets Ciao, Epinions, Dianping, and Douban book demonstrate the effectiveness of CDRSB compared to state-of-the-art baselines.
MAMo: Leveraging Memory and Attention for Monocular Video Depth Estimation
Jul 26, 2023
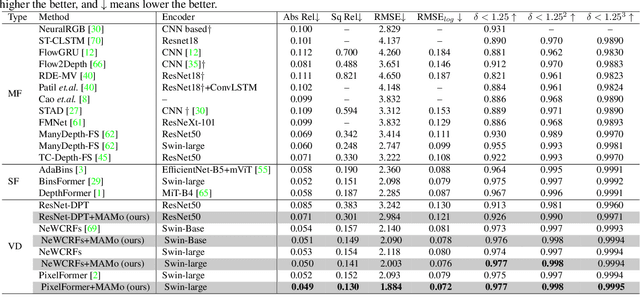
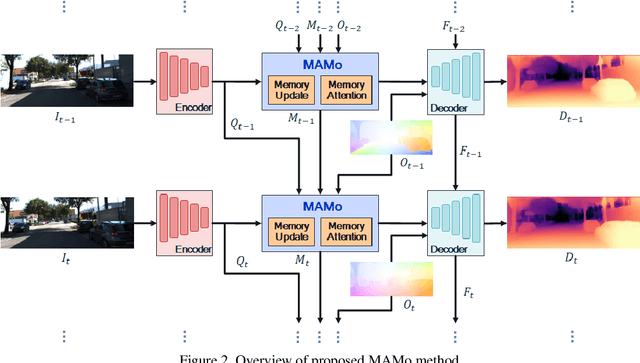
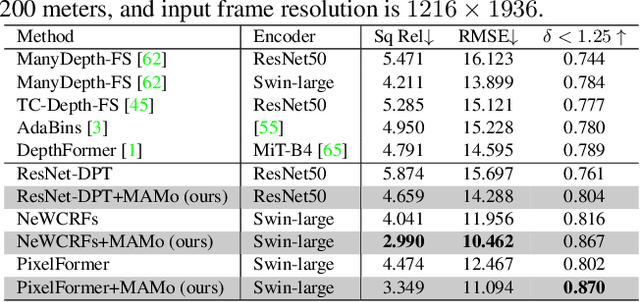
We propose MAMo, a novel memory and attention frame-work for monocular video depth estimation. MAMo can augment and improve any single-image depth estimation networks into video depth estimation models, enabling them to take advantage of the temporal information to predict more accurate depth. In MAMo, we augment model with memory which aids the depth prediction as the model streams through the video. Specifically, the memory stores learned visual and displacement tokens of the previous time instances. This allows the depth network to cross-reference relevant features from the past when predicting depth on the current frame. We introduce a novel scheme to continuously update the memory, optimizing it to keep tokens that correspond with both the past and the present visual information. We adopt attention-based approach to process memory features where we first learn the spatio-temporal relation among the resultant visual and displacement memory tokens using self-attention module. Further, the output features of self-attention are aggregated with the current visual features through cross-attention. The cross-attended features are finally given to a decoder to predict depth on the current frame. Through extensive experiments on several benchmarks, including KITTI, NYU-Depth V2, and DDAD, we show that MAMo consistently improves monocular depth estimation networks and sets new state-of-the-art (SOTA) accuracy. Notably, our MAMo video depth estimation provides higher accuracy with lower latency, when omparing to SOTA cost-volume-based video depth models.
EGA-Depth: Efficient Guided Attention for Self-Supervised Multi-Camera Depth Estimation
Apr 06, 2023
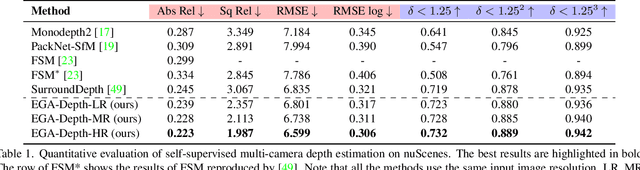

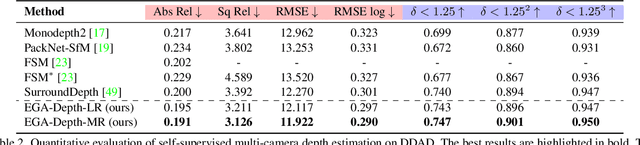
The ubiquitous multi-camera setup on modern autonomous vehicles provides an opportunity to construct surround-view depth. Existing methods, however, either perform independent monocular depth estimations on each camera or rely on computationally heavy self attention mechanisms. In this paper, we propose a novel guided attention architecture, EGA-Depth, which can improve both the efficiency and accuracy of self-supervised multi-camera depth estimation. More specifically, for each camera, we use its perspective view as the query to cross-reference its neighboring views to derive informative features for this camera view. This allows the model to perform attention only across views with considerable overlaps and avoid the costly computations of standard self-attention. Given its efficiency, EGA-Depth enables us to exploit higher-resolution visual features, leading to improved accuracy. Furthermore, EGA-Depth can incorporate more frames from previous time steps as it scales linearly w.r.t. the number of views and frames. Extensive experiments on two challenging autonomous driving benchmarks nuScenes and DDAD demonstrate the efficacy of our proposed EGA-Depth and show that it achieves the new state-of-the-art in self-supervised multi-camera depth estimation.
Self-Supervised Learning of Depth and Ego-motion with Differentiable Bundle Adjustment
Sep 28, 2019
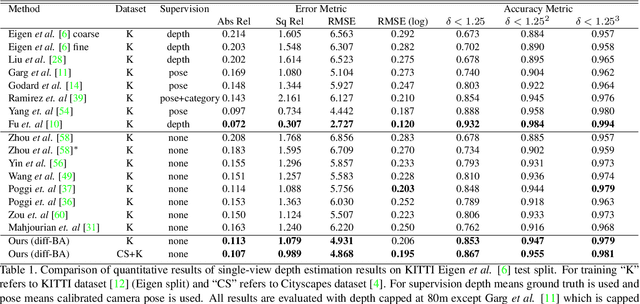
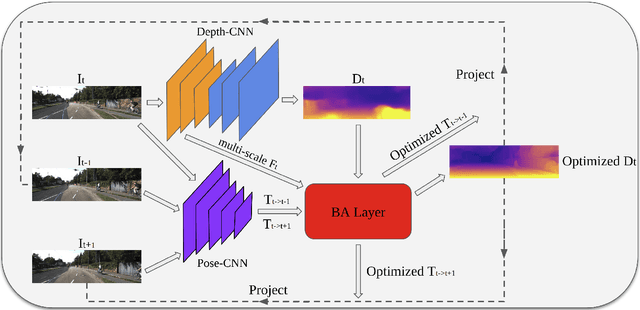
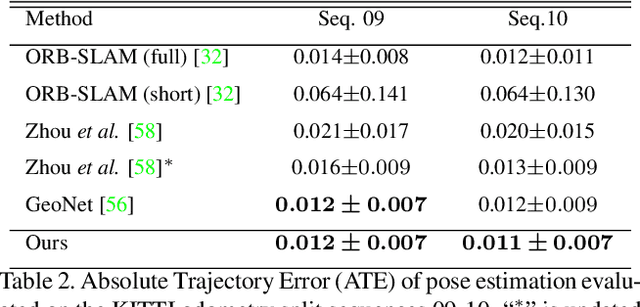
Learning to predict scene depth and camera motion from RGB inputs only is a challenging task. Most existing learning based methods deal with this task in a supervised manner which require ground-truth data that is expensive to acquire. More recent approaches explore the possibility of estimating scene depth and camera pose in a self-supervised learning framework. Despite encouraging results are shown, current methods either learn from monocular videos for depth and pose and typically do so without enforcing multi-view geometry constraints between scene structure and camera motion, or require stereo sequences as input where the ground-truth between-frame motion parameters need to be known. In this paper we propose to jointly optimize the scene depth and camera motion via incorporating differentiable Bundle Adjustment (BA) layer by minimizing the feature-metric error, and then form the photometric consistency loss with view synthesis as the final supervisory signal. The proposed approach only needs unlabeled monocular videos as input, and extensive experiments on the KITTI and Cityscapes dataset show that our method achieves state-of-the-art results in self-supervised approaches using monocular videos as input, and even gains advantage to the line of methods that learns from calibrated stereo sequences (i.e. with pose supervision).
Structure-Attentioned Memory Network for Monocular Depth Estimation
Sep 10, 2019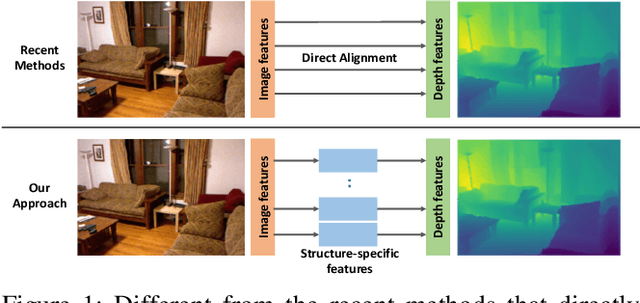
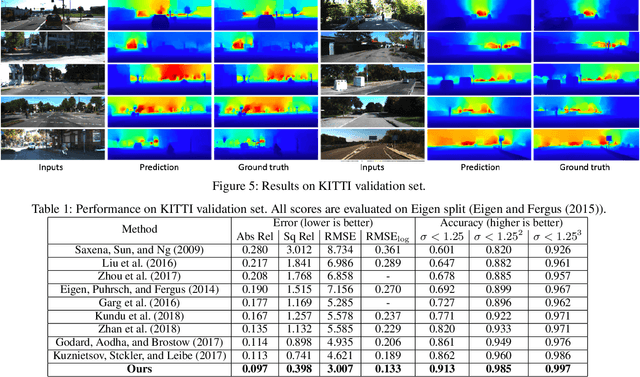
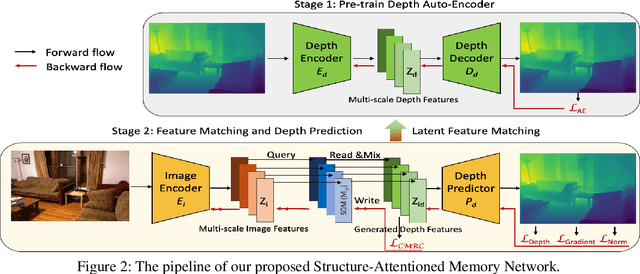
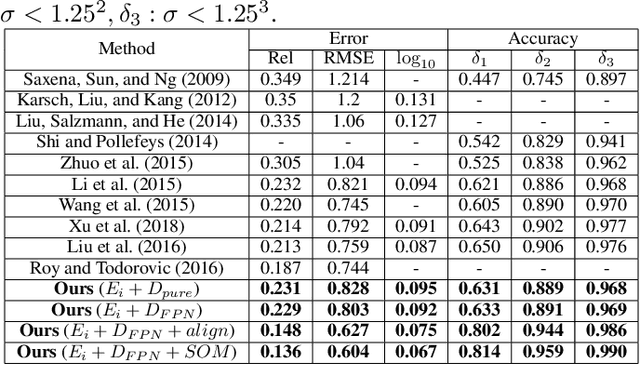
Monocular depth estimation is a challenging task that aims to predict a corresponding depth map from a given single RGB image. Recent deep learning models have been proposed to predict the depth from the image by learning the alignment of deep features between the RGB image and the depth domains. In this paper, we present a novel approach, named Structure-Attentioned Memory Network, to more effectively transfer domain features for monocular depth estimation by taking into account the common structure regularities (e.g., repetitive structure patterns, planar surfaces, symmetries) in domain adaptation. To this end, we introduce a new Structure-Oriented Memory (SOM) module to learn and memorize the structure-specific information between RGB image domain and the depth domain. More specifically, in the SOM module, we develop a Memorable Bank of Filters (MBF) unit to learn a set of filters that memorize the structure-aware image-depth residual pattern, and also an Attention Guided Controller (AGC) unit to control the filter selection in the MBF given image features queries. Given the query image feature, the trained SOM module is able to adaptively select the best customized filters for cross-domain feature transferring with an optimal structural disparity between image and depth. In summary, we focus on addressing this structure-specific domain adaption challenge by proposing a novel end-to-end multi-scale memorable network for monocular depth estimation. The experiments show that our proposed model demonstrates the superior performance compared to the existing supervised monocular depth estimation approaches on the challenging KITTI and NYU Depth V2 benchmarks.