 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYutong Chen
PriorNet: A Novel Lightweight Network with Multidimensional Interactive Attention for Efficient Image Dehazing
Apr 24, 2024
Hazy images degrade visual quality, and dehazing is a crucial prerequisite for subsequent processing tasks. Most current dehazing methods rely on neural networks and face challenges such as high computational parameter pressure and weak generalization capabilities. This paper introduces PriorNet--a novel, lightweight, and highly applicable dehazing network designed to significantly improve the clarity and visual quality of hazy images while avoiding excessive detail extraction issues. The core of PriorNet is the original Multi-Dimensional Interactive Attention (MIA) mechanism, which effectively captures a wide range of haze characteristics, substantially reducing the computational load and generalization difficulties associated with complex systems. By utilizing a uniform convolutional kernel size and incorporating skip connections, we have streamlined the feature extraction process. Simplifying the number of layers and architecture not only enhances dehazing efficiency but also facilitates easier deployment on edge devices. Extensive testing across multiple datasets has demonstrated PriorNet's exceptional performance in dehazing and clarity restoration, maintaining image detail and color fidelity in single-image dehazing tasks. Notably, with a model size of just 18Kb, PriorNet showcases superior dehazing generalization capabilities compared to other methods. Our research makes a significant contribution to advancing image dehazing technology, providing new perspectives and tools for the field and related domains, particularly emphasizing the importance of improving universality and deployability.
Within the Dynamic Context: Inertia-aware 3D Human Modeling with Pose Sequence
Mar 28, 2024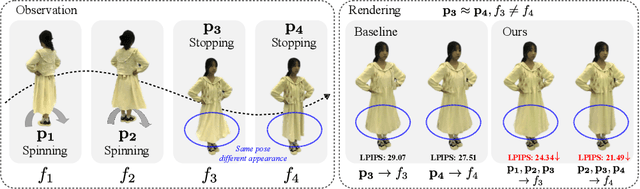

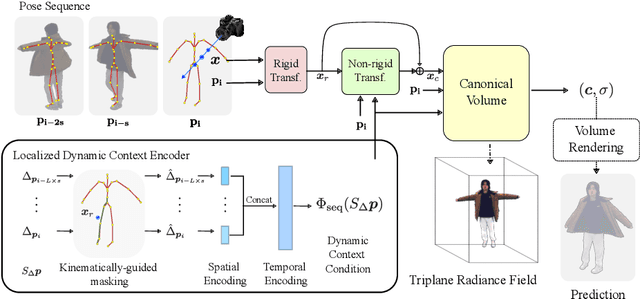
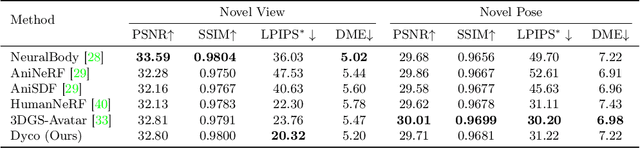
Neural rendering techniques have significantly advanced 3D human body modeling. However, previous approaches often overlook dynamics induced by factors such as motion inertia, leading to challenges in scenarios like abrupt stops after rotation, where the pose remains static while the appearance changes. This limitation arises from reliance on a single pose as conditional input, resulting in ambiguity in mapping one pose to multiple appearances. In this study, we elucidate that variations in human appearance depend not only on the current frame's pose condition but also on past pose states. Therefore, we introduce Dyco, a novel method utilizing the delta pose sequence representation for non-rigid deformations and canonical space to effectively model temporal appearance variations. To prevent a decrease in the model's generalization ability to novel poses, we further propose low-dimensional global context to reduce unnecessary inter-body part dependencies and a quantization operation to mitigate overfitting of the delta pose sequence by the model. To validate the effectiveness of our approach, we collected a novel dataset named I3D-Human, with a focus on capturing temporal changes in clothing appearance under approximate poses. Through extensive experiments on both I3D-Human and existing datasets, our approach demonstrates superior qualitative and quantitative performance. In addition, our inertia-aware 3D human method can unprecedentedly simulate appearance changes caused by inertia at different velocities.
Improving Continuous Sign Language Recognition with Cross-Lingual Signs
Aug 21, 2023



This work dedicates to continuous sign language recognition (CSLR), which is a weakly supervised task dealing with the recognition of continuous signs from videos, without any prior knowledge about the temporal boundaries between consecutive signs. Data scarcity heavily impedes the progress of CSLR. Existing approaches typically train CSLR models on a monolingual corpus, which is orders of magnitude smaller than that of speech recognition. In this work, we explore the feasibility of utilizing multilingual sign language corpora to facilitate monolingual CSLR. Our work is built upon the observation of cross-lingual signs, which originate from different sign languages but have similar visual signals (e.g., hand shape and motion). The underlying idea of our approach is to identify the cross-lingual signs in one sign language and properly leverage them as auxiliary training data to improve the recognition capability of another. To achieve the goal, we first build two sign language dictionaries containing isolated signs that appear in two datasets. Then we identify the sign-to-sign mappings between two sign languages via a well-optimized isolated sign language recognition model. At last, we train a CSLR model on the combination of the target data with original labels and the auxiliary data with mapped labels. Experimentally, our approach achieves state-of-the-art performance on two widely-used CSLR datasets: Phoenix-2014 and Phoenix-2014T.
Efficient Cross-Lingual Transfer for Chinese Stable Diffusion with Images as Pivots
May 19, 2023



Diffusion models have made impressive progress in text-to-image synthesis. However, training such large-scale models (e.g. Stable Diffusion), from scratch requires high computational costs and massive high-quality text-image pairs, which becomes unaffordable in other languages. To handle this challenge, we propose IAP, a simple but effective method to transfer English Stable Diffusion into Chinese. IAP optimizes only a separate Chinese text encoder with all other parameters fixed to align Chinese semantics space to the English one in CLIP. To achieve this, we innovatively treat images as pivots and minimize the distance of attentive features produced from cross-attention between images and each language respectively. In this way, IAP establishes connections of Chinese, English and visual semantics in CLIP's embedding space efficiently, advancing the quality of the generated image with direct Chinese prompts. Experimental results show that our method outperforms several strong Chinese diffusion models with only 5%~10% training data.
Expressive Speech-driven Facial Animation with controllable emotions
Jan 05, 2023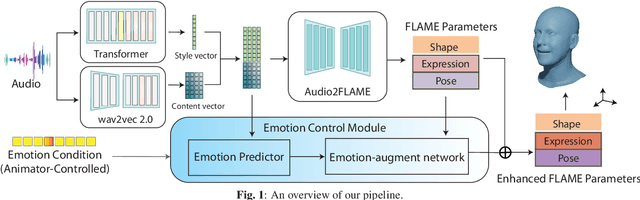

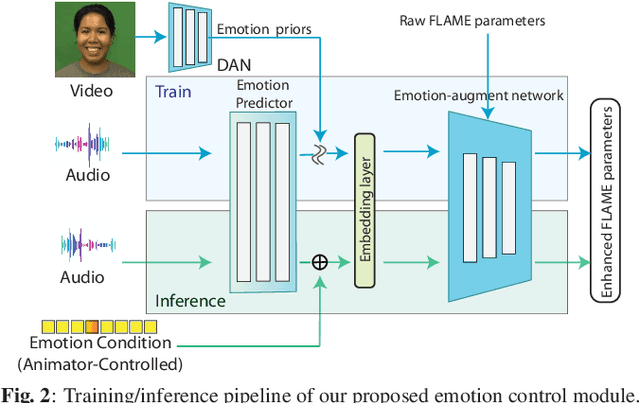
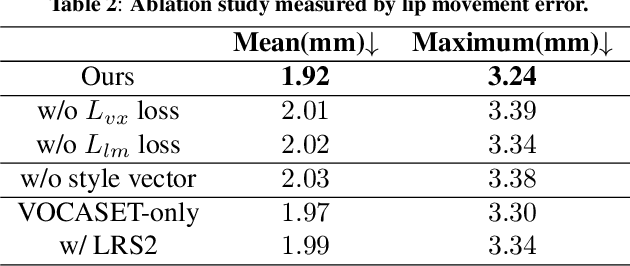
It is in high demand to generate facial animation with high realism, but it remains a challenging task. Existing approaches of speech-driven facial animation can produce satisfactory mouth movement and lip synchronization, but show weakness in dramatic emotional expressions and flexibility in emotion control. This paper presents a novel deep learning-based approach for expressive facial animation generation from speech that can exhibit wide-spectrum facial expressions with controllable emotion type and intensity. We propose an emotion controller module to learn the relationship between the emotion variations (e.g., types and intensity) and the corresponding facial expression parameters. It enables emotion-controllable facial animation, where the target expression can be continuously adjusted as desired. The qualitative and quantitative evaluations show that the animation generated by our method is rich in facial emotional expressiveness while retaining accurate lip movement, outperforming other state-of-the-art methods.
Two-Stream Network for Sign Language Recognition and Translation
Nov 02, 2022



Sign languages are visual languages using manual articulations and non-manual elements to convey information. For sign language recognition and translation, the majority of existing approaches directly encode RGB videos into hidden representations. RGB videos, however, are raw signals with substantial visual redundancy, leading the encoder to overlook the key information for sign language understanding. To mitigate this problem and better incorporate domain knowledge, such as handshape and body movement, we introduce a dual visual encoder containing two separate streams to model both the raw videos and the keypoint sequences generated by an off-the-shelf keypoint estimator. To make the two streams interact with each other, we explore a variety of techniques, including bidirectional lateral connection, sign pyramid network with auxiliary supervision, and frame-level self-distillation. The resulting model is called TwoStream-SLR, which is competent for sign language recognition (SLR). TwoStream-SLR is extended to a sign language translation (SLT) model, TwoStream-SLT, by simply attaching an extra translation network. Experimentally, our TwoStream-SLR and TwoStream-SLT achieve state-of-the-art performance on SLR and SLT tasks across a series of datasets including Phoenix-2014, Phoenix-2014T, and CSL-Daily.
A Simple Multi-Modality Transfer Learning Baseline for Sign Language Translation
Mar 08, 2022



This paper proposes a simple transfer learning baseline for sign language translation. Existing sign language datasets (e.g. PHOENIX-2014T, CSL-Daily) contain only about 10K-20K pairs of sign videos, gloss annotations and texts, which are an order of magnitude smaller than typical parallel data for training spoken language translation models. Data is thus a bottleneck for training effective sign language translation models. To mitigate this problem, we propose to progressively pretrain the model from general-domain datasets that include a large amount of external supervision to within-domain datasets. Concretely, we pretrain the sign-to-gloss visual network on the general domain of human actions and the within-domain of a sign-to-gloss dataset, and pretrain the gloss-to-text translation network on the general domain of a multilingual corpus and the within-domain of a gloss-to-text corpus. The joint model is fine-tuned with an additional module named the visual-language mapper that connects the two networks. This simple baseline surpasses the previous state-of-the-art results on two sign language translation benchmarks, demonstrating the effectiveness of transfer learning. With its simplicity and strong performance, this approach can serve as a solid baseline for future research.
AI-based Reconstruction for Fast MRI -- A Systematic Review and Meta-analysis
Dec 23, 2021
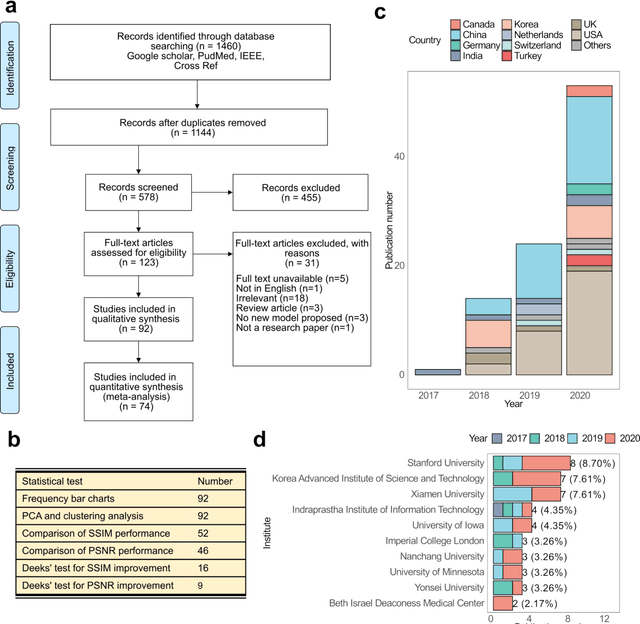
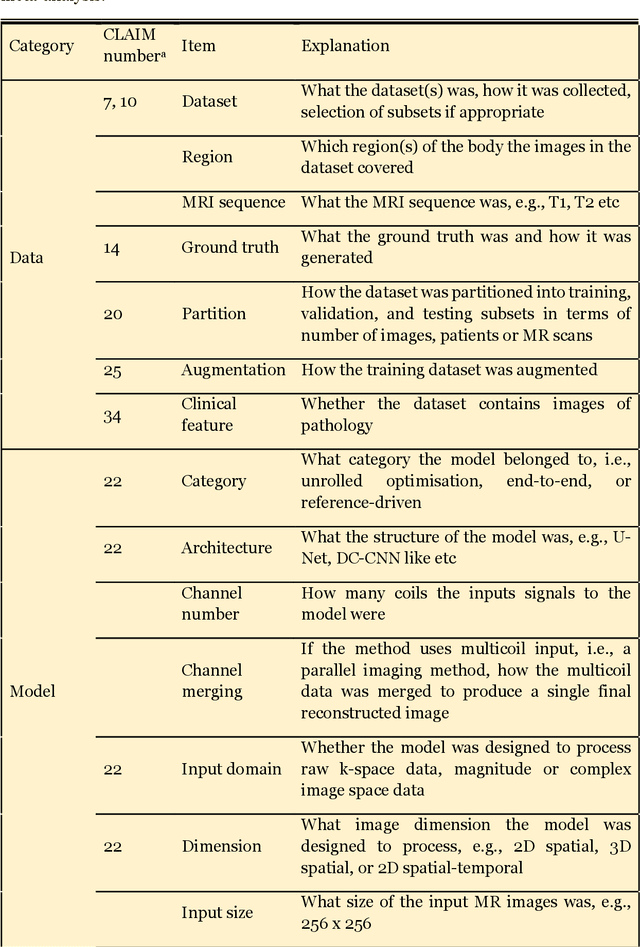
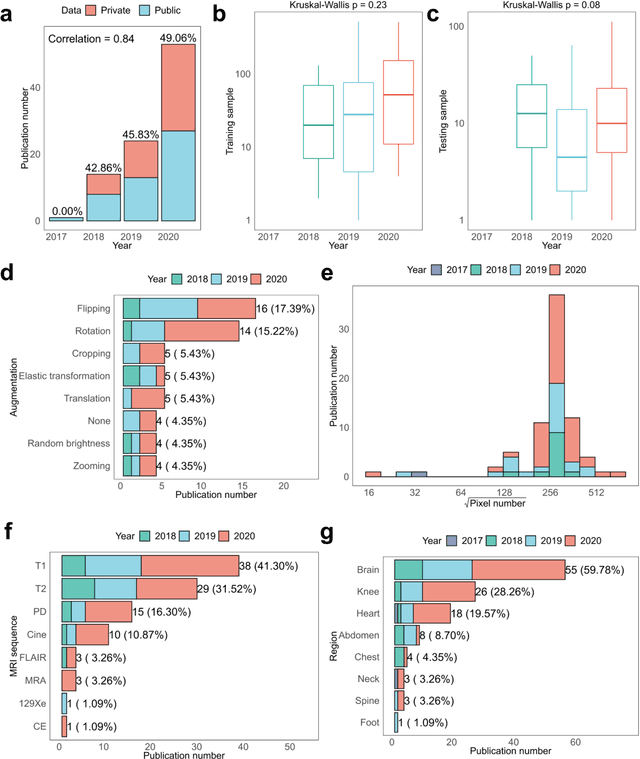
Compressed sensing (CS) has been playing a key role in accelerating the magnetic resonance imaging (MRI) acquisition process. With the resurgence of artificial intelligence, deep neural networks and CS algorithms are being integrated to redefine the state of the art of fast MRI. The past several years have witnessed substantial growth in the complexity, diversity, and performance of deep learning-based CS techniques that are dedicated to fast MRI. In this meta-analysis, we systematically review the deep learning-based CS techniques for fast MRI, describe key model designs, highlight breakthroughs, and discuss promising directions. We have also introduced a comprehensive analysis framework and a classification system to assess the pivotal role of deep learning in CS-based acceleration for MRI.
Generative Adversarial Networks (GAN) Powered Fast Magnetic Resonance Imaging -- Mini Review, Comparison and Perspectives
May 04, 2021



Magnetic Resonance Imaging (MRI) is a vital component of medical imaging. When compared to other image modalities, it has advantages such as the absence of radiation, superior soft tissue contrast, and complementary multiple sequence information. However, one drawback of MRI is its comparatively slow scanning and reconstruction compared to other image modalities, limiting its usage in some clinical applications when imaging time is critical. Traditional compressive sensing based MRI (CS-MRI) reconstruction can speed up MRI acquisition, but suffers from a long iterative process and noise-induced artefacts. Recently, Deep Neural Networks (DNNs) have been used in sparse MRI reconstruction models to recreate relatively high-quality images from heavily undersampled k-space data, allowing for much faster MRI scanning. However, there are still some hurdles to tackle. For example, directly training DNNs based on L1/L2 distance to the target fully sampled images could result in blurry reconstruction because L1/L2 loss can only enforce overall image or patch similarity and does not take into account local information such as anatomical sharpness. It is also hard to preserve fine image details while maintaining a natural appearance. More recently, Generative Adversarial Networks (GAN) based methods are proposed to solve fast MRI with enhanced image perceptual quality. The encoder obtains a latent space for the undersampling image, and the image is reconstructed by the decoder using the GAN loss. In this chapter, we review the GAN powered fast MRI methods with a comparative study on various anatomical datasets to demonstrate the generalisability and robustness of this kind of fast MRI while providing future perspectives.
Learning to Manipulate Individual Objects in an Image
Apr 11, 2020



We describe a method to train a generative model with latent factors that are (approximately) independent and localized. This means that perturbing the latent variables affects only local regions of the synthesized image, corresponding to objects. Unlike other unsupervised generative models, ours enables object-centric manipulation, without requiring object-level annotations, or any form of annotation for that matter. The key to our method is the combination of spatial disentanglement, enforced by a Contextual Information Separation loss, and perceptual cycle-consistency, enforced by a loss that penalizes changes in the image partition in response to perturbations of the latent factors. We test our method's ability to allow independent control of spatial and semantic factors of variability on existing datasets and also introduce two new ones that highlight the limitations of current methods.