 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZe Yang
LightSim: Neural Lighting Simulation for Urban Scenes
Dec 11, 2023


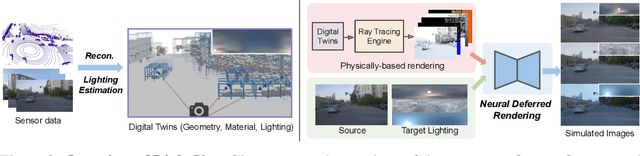
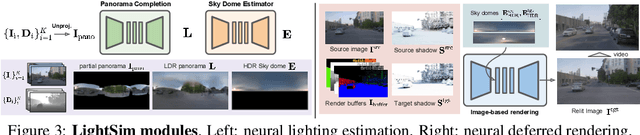
Different outdoor illumination conditions drastically alter the appearance of urban scenes, and they can harm the performance of image-based robot perception systems if not seen during training. Camera simulation provides a cost-effective solution to create a large dataset of images captured under different lighting conditions. Towards this goal, we propose LightSim, a neural lighting camera simulation system that enables diverse, realistic, and controllable data generation. LightSim automatically builds lighting-aware digital twins at scale from collected raw sensor data and decomposes the scene into dynamic actors and static background with accurate geometry, appearance, and estimated scene lighting. These digital twins enable actor insertion, modification, removal, and rendering from a new viewpoint, all in a lighting-aware manner. LightSim then combines physically-based and learnable deferred rendering to perform realistic relighting of modified scenes, such as altering the sun location and modifying the shadows or changing the sun brightness, producing spatially- and temporally-consistent camera videos. Our experiments show that LightSim generates more realistic relighting results than prior work. Importantly, training perception models on data generated by LightSim can significantly improve their performance.
Real-Time Neural Rasterization for Large Scenes
Nov 09, 2023We propose a new method for realistic real-time novel-view synthesis (NVS) of large scenes. Existing neural rendering methods generate realistic results, but primarily work for small scale scenes (<50 square meters) and have difficulty at large scale (>10000 square meters). Traditional graphics-based rasterization rendering is fast for large scenes but lacks realism and requires expensive manually created assets. Our approach combines the best of both worlds by taking a moderate-quality scaffold mesh as input and learning a neural texture field and shader to model view-dependant effects to enhance realism, while still using the standard graphics pipeline for real-time rendering. Our method outperforms existing neural rendering methods, providing at least 30x faster rendering with comparable or better realism for large self-driving and drone scenes. Our work is the first to enable real-time rendering of large real-world scenes.
Reconstructing Objects in-the-wild for Realistic Sensor Simulation
Nov 09, 2023Reconstructing objects from real world data and rendering them at novel views is critical to bringing realism, diversity and scale to simulation for robotics training and testing. In this work, we present NeuSim, a novel approach that estimates accurate geometry and realistic appearance from sparse in-the-wild data captured at distance and at limited viewpoints. Towards this goal, we represent the object surface as a neural signed distance function and leverage both LiDAR and camera sensor data to reconstruct smooth and accurate geometry and normals. We model the object appearance with a robust physics-inspired reflectance representation effective for in-the-wild data. Our experiments show that NeuSim has strong view synthesis performance on challenging scenarios with sparse training views. Furthermore, we showcase composing NeuSim assets into a virtual world and generating realistic multi-sensor data for evaluating self-driving perception models.
CADSim: Robust and Scalable in-the-wild 3D Reconstruction for Controllable Sensor Simulation
Nov 02, 2023Realistic simulation is key to enabling safe and scalable development of % self-driving vehicles. A core component is simulating the sensors so that the entire autonomy system can be tested in simulation. Sensor simulation involves modeling traffic participants, such as vehicles, with high quality appearance and articulated geometry, and rendering them in real time. The self-driving industry has typically employed artists to build these assets. However, this is expensive, slow, and may not reflect reality. Instead, reconstructing assets automatically from sensor data collected in the wild would provide a better path to generating a diverse and large set with good real-world coverage. Nevertheless, current reconstruction approaches struggle on in-the-wild sensor data, due to its sparsity and noise. To tackle these issues, we present CADSim, which combines part-aware object-class priors via a small set of CAD models with differentiable rendering to automatically reconstruct vehicle geometry, including articulated wheels, with high-quality appearance. Our experiments show our method recovers more accurate shapes from sparse data compared to existing approaches. Importantly, it also trains and renders efficiently. We demonstrate our reconstructed vehicles in several applications, including accurate testing of autonomy perception systems.
Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
Nov 02, 2023Learning world models can teach an agent how the world works in an unsupervised manner. Even though it can be viewed as a special case of sequence modeling, progress for scaling world models on robotic applications such as autonomous driving has been somewhat less rapid than scaling language models with Generative Pre-trained Transformers (GPT). We identify two reasons as major bottlenecks: dealing with complex and unstructured observation space, and having a scalable generative model. Consequently, we propose a novel world modeling approach that first tokenizes sensor observations with VQVAE, then predicts the future via discrete diffusion. To efficiently decode and denoise tokens in parallel, we recast Masked Generative Image Transformer into the discrete diffusion framework with a few simple changes, resulting in notable improvement. When applied to learning world models on point cloud observations, our model reduces prior SOTA Chamfer distance by more than 65% for 1s prediction, and more than 50% for 3s prediction, across NuScenes, KITTI Odometry, and Argoverse2 datasets. Our results demonstrate that discrete diffusion on tokenized agent experience can unlock the power of GPT-like unsupervised learning for robotic agents.
Open-Structure: a Structural Benchmark Dataset for SLAM Algorithms
Oct 17, 2023This paper introduces a new benchmark dataset, Open-Structure, for evaluating visual odometry and SLAM methods, which directly equips point and line measurements, correspondences, structural associations, and co-visibility factor graphs instead of providing raw images. Based on the proposed benchmark dataset, these 2D or 3D data can be directly input to different stages of SLAM pipelines to avoid the impact of the data preprocessing modules in ablation experiments. First, we propose a dataset generator for real-world and simulated scenarios. In real-world scenes, it maintains the same observations and occlusions as actual feature extraction results. Those generated simulation sequences enhance the dataset's diversity by introducing various carefully designed trajectories and observations. Second, a SLAM baseline is proposed using our dataset to evaluate widely used modules in camera pose tracking, parametrization, and optimization modules. By evaluating these state-of-the-art algorithms across different scenarios, we discern each module's strengths and weaknesses within the camera tracking and optimization process. Our dataset and baseline are available at \url{https://github.com/yanyan-li/Open-Structure}.
UniSim: A Neural Closed-Loop Sensor Simulator
Aug 03, 2023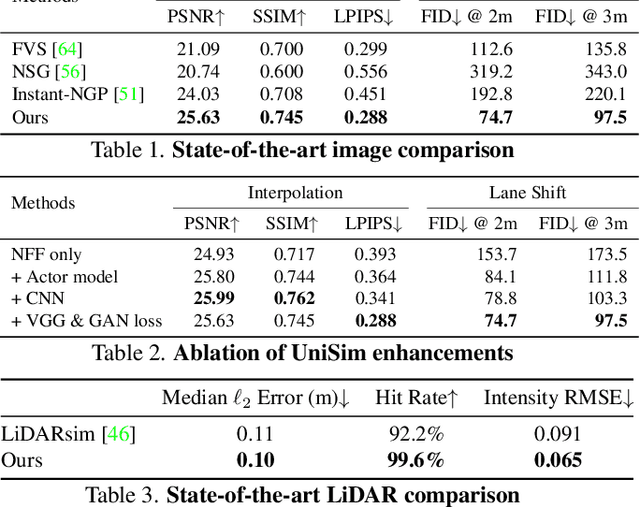
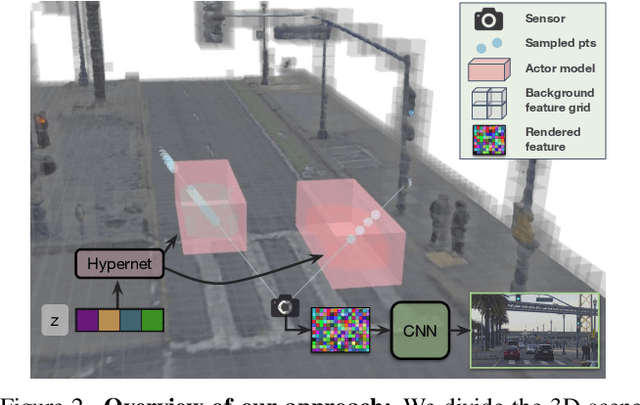


Rigorously testing autonomy systems is essential for making safe self-driving vehicles (SDV) a reality. It requires one to generate safety critical scenarios beyond what can be collected safely in the world, as many scenarios happen rarely on public roads. To accurately evaluate performance, we need to test the SDV on these scenarios in closed-loop, where the SDV and other actors interact with each other at each timestep. Previously recorded driving logs provide a rich resource to build these new scenarios from, but for closed loop evaluation, we need to modify the sensor data based on the new scene configuration and the SDV's decisions, as actors might be added or removed and the trajectories of existing actors and the SDV will differ from the original log. In this paper, we present UniSim, a neural sensor simulator that takes a single recorded log captured by a sensor-equipped vehicle and converts it into a realistic closed-loop multi-sensor simulation. UniSim builds neural feature grids to reconstruct both the static background and dynamic actors in the scene, and composites them together to simulate LiDAR and camera data at new viewpoints, with actors added or removed and at new placements. To better handle extrapolated views, we incorporate learnable priors for dynamic objects, and leverage a convolutional network to complete unseen regions. Our experiments show UniSim can simulate realistic sensor data with small domain gap on downstream tasks. With UniSim, we demonstrate closed-loop evaluation of an autonomy system on safety-critical scenarios as if it were in the real world.
TANet: Thread-Aware Pretraining for Abstractive Conversational Summarization
Apr 09, 2022
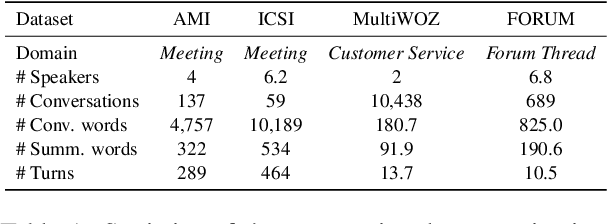
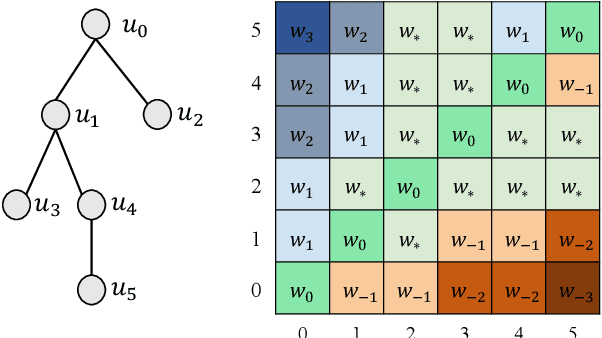
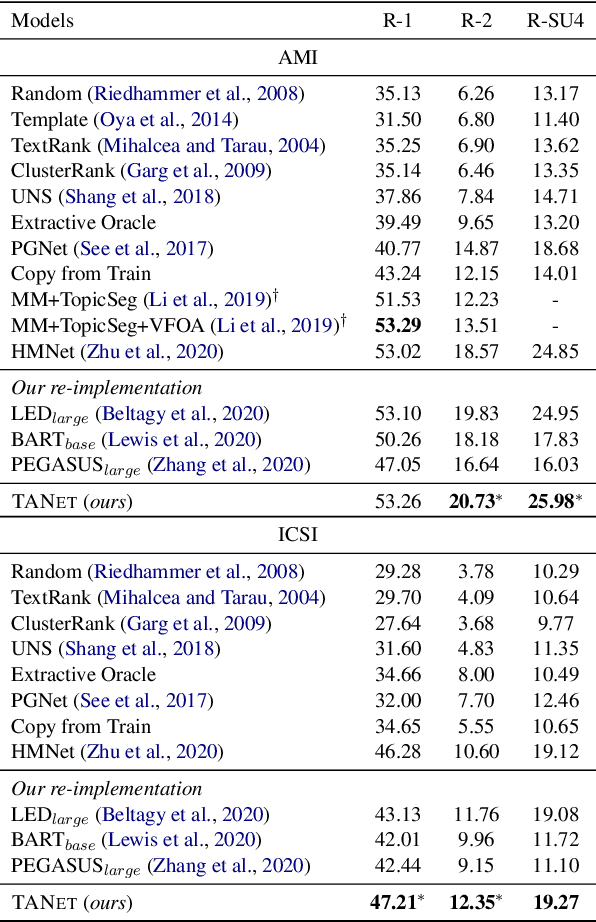
Although pre-trained language models (PLMs) have achieved great success and become a milestone in NLP, abstractive conversational summarization remains a challenging but less studied task. The difficulty lies in two aspects. One is the lack of large-scale conversational summary data. Another is that applying the existing pre-trained models to this task is tricky because of the structural dependence within the conversation and its informal expression, etc. In this work, we first build a large-scale (11M) pretraining dataset called RCS, based on the multi-person discussions in the Reddit community. We then present TANet, a thread-aware Transformer-based network. Unlike the existing pre-trained models that treat a conversation as a sequence of sentences, we argue that the inherent contextual dependency among the utterances plays an essential role in understanding the entire conversation and thus propose two new techniques to incorporate the structural information into our model. The first is thread-aware attention which is computed by taking into account the contextual dependency within utterances. Second, we apply thread prediction loss to predict the relations between utterances. We evaluate our model on four datasets of real conversations, covering types of meeting transcripts, customer-service records, and forum threads. Experimental results demonstrate that TANET achieves a new state-of-the-art in terms of both automatic evaluation and human judgment.
RBGNet: Ray-based Grouping for 3D Object Detection
Apr 05, 2022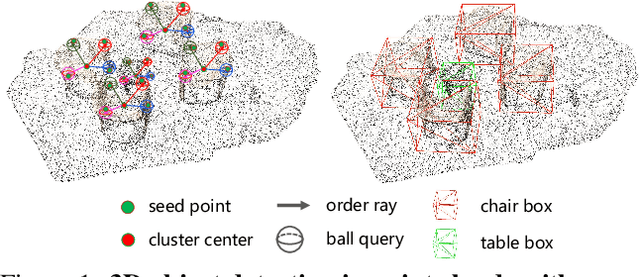

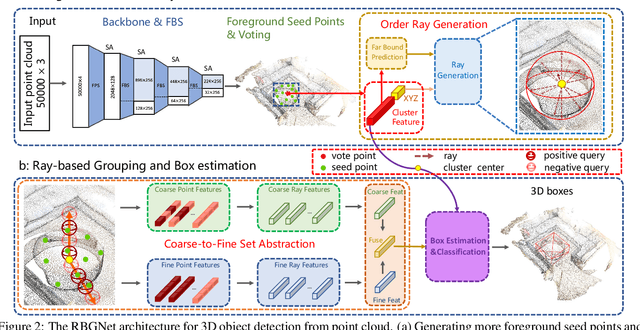
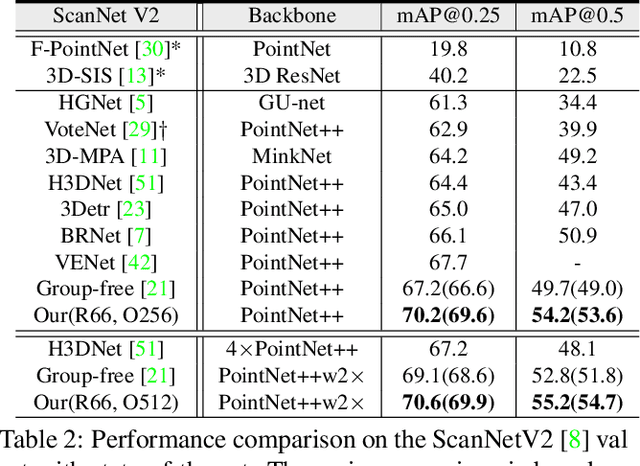
As a fundamental problem in computer vision, 3D object detection is experiencing rapid growth. To extract the point-wise features from the irregularly and sparsely distributed points, previous methods usually take a feature grouping module to aggregate the point features to an object candidate. However, these methods have not yet leveraged the surface geometry of foreground objects to enhance grouping and 3D box generation. In this paper, we propose the RBGNet framework, a voting-based 3D detector for accurate 3D object detection from point clouds. In order to learn better representations of object shape to enhance cluster features for predicting 3D boxes, we propose a ray-based feature grouping module, which aggregates the point-wise features on object surfaces using a group of determined rays uniformly emitted from cluster centers. Considering the fact that foreground points are more meaningful for box estimation, we design a novel foreground biased sampling strategy in downsample process to sample more points on object surfaces and further boost the detection performance. Our model achieves state-of-the-art 3D detection performance on ScanNet V2 and SUN RGB-D with remarkable performance gains. Code will be available at https://github.com/Haiyang-W/RBGNet.
Efficient Few-Shot Object Detection via Knowledge Inheritance
Mar 23, 2022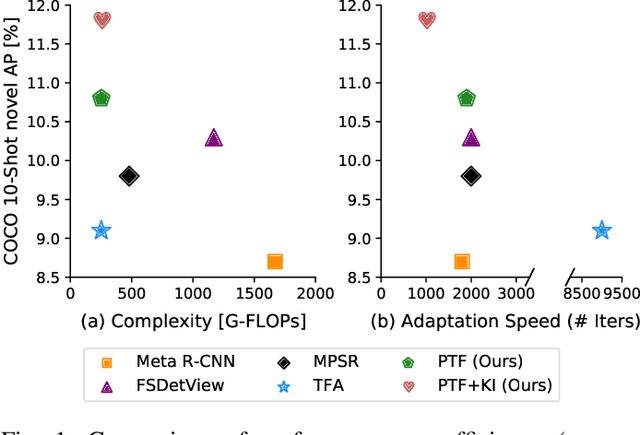
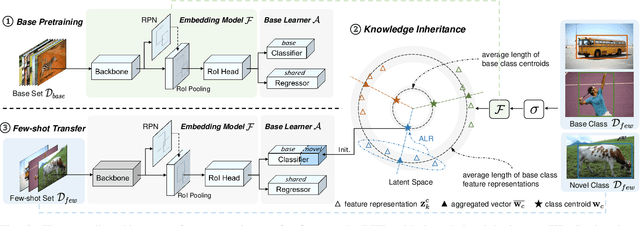

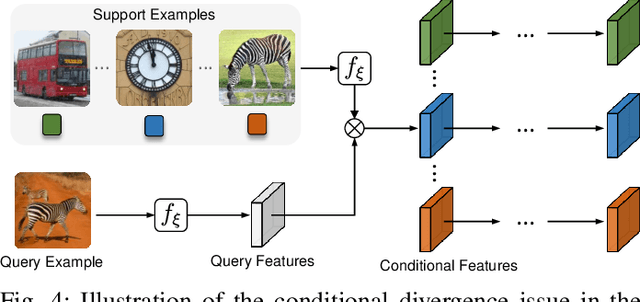
Few-shot object detection (FSOD), which aims at learning a generic detector that can adapt to unseen tasks with scarce training samples, has witnessed consistent improvement recently. However, most existing methods ignore the efficiency issues, e.g., high computational complexity and slow adaptation speed. Notably, efficiency has become an increasingly important evaluation metric for few-shot techniques due to an emerging trend toward embedded AI. To this end, we present an efficient pretrain-transfer framework (PTF) baseline with no computational increment, which achieves comparable results with previous state-of-the-art (SOTA) methods. Upon this baseline, we devise an initializer named knowledge inheritance (KI) to reliably initialize the novel weights for the box classifier, which effectively facilitates the knowledge transfer process and boosts the adaptation speed. Within the KI initializer, we propose an adaptive length re-scaling (ALR) strategy to alleviate the vector length inconsistency between the predicted novel weights and the pretrained base weights. Finally, our approach not only achieves the SOTA results across three public benchmarks, i.e., PASCAL VOC, COCO and LVIS, but also exhibits high efficiency with 1.8-9.0x faster adaptation speed against the other methods on COCO/LVIS benchmark during few-shot transfer. To our best knowledge, this is the first work to consider the efficiency problem in FSOD. We hope to motivate a trend toward powerful yet efficient few-shot technique development. The codes are publicly available at https://github.com/Ze-Yang/Efficient-FSOD.