 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhihong Shao
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Feb 06, 2024
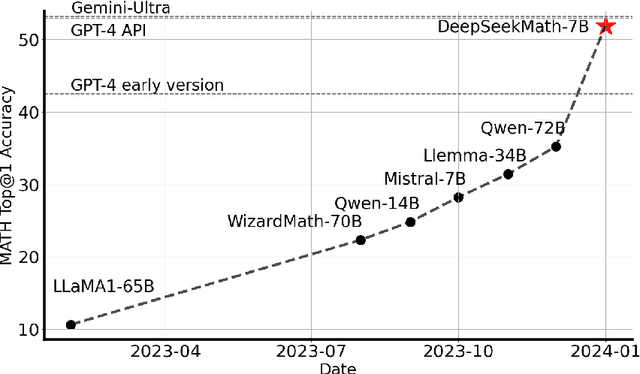
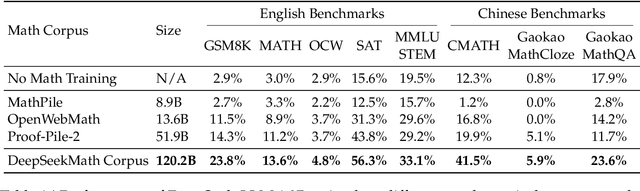
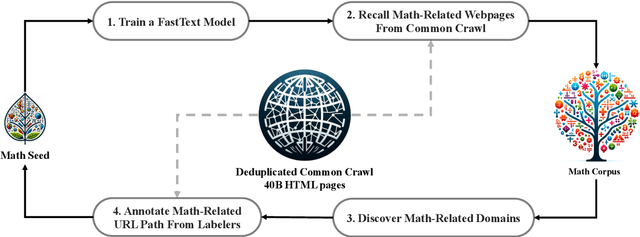
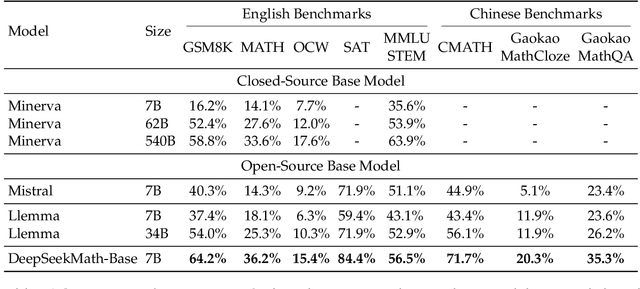
Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. Self-consistency over 64 samples from DeepSeekMath 7B achieves 60.9% on MATH. The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Dec 28, 2023In this paper, we present an innovative process-oriented math process reward model called \textbf{Math-Shepherd}, which assigns a reward score to each step of math problem solutions. The training of Math-Shepherd is achieved using automatically constructed process-wise supervision data, breaking the bottleneck of heavy reliance on manual annotation in existing work. We explore the effectiveness of Math-Shepherd in two scenarios: 1) \textit{Verification}: Math-Shepherd is utilized for reranking multiple outputs generated by Large Language Models (LLMs); 2) \textit{Reinforcement Learning}: Math-Shepherd is employed to reinforce LLMs with step-by-step Proximal Policy Optimization (PPO). With Math-Shepherd, a series of open-source LLMs demonstrates exceptional performance. For instance, the step-by-step PPO with Math-Shepherd significantly improves the accuracy of Mistral-7B (77.9\%$\to$84.1\% on GSM8K and 28.6\%$\to$33.0\% on MATH). The accuracy can be further enhanced to 89.1\% and 43.5\% on GSM8K and MATH with the verification of Math-Shepherd, respectively. We believe that automatic process supervision holds significant potential for the future evolution of LLMs.
ToRA: A Tool-Integrated Reasoning Agent for Mathematical Problem Solving
Oct 04, 2023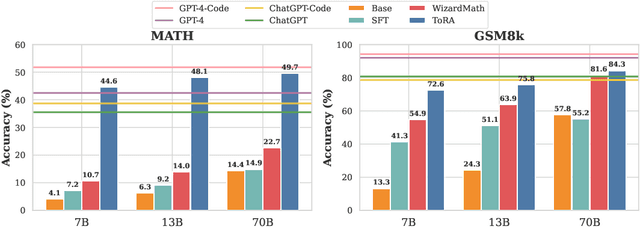

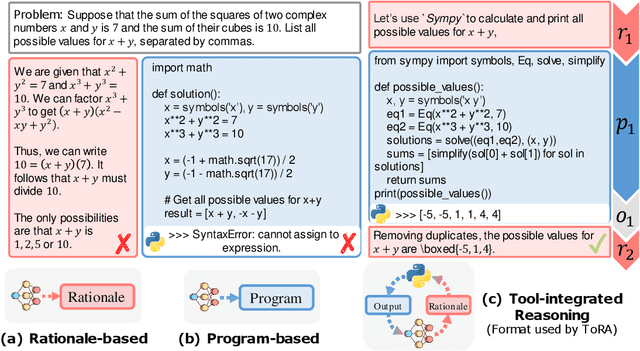
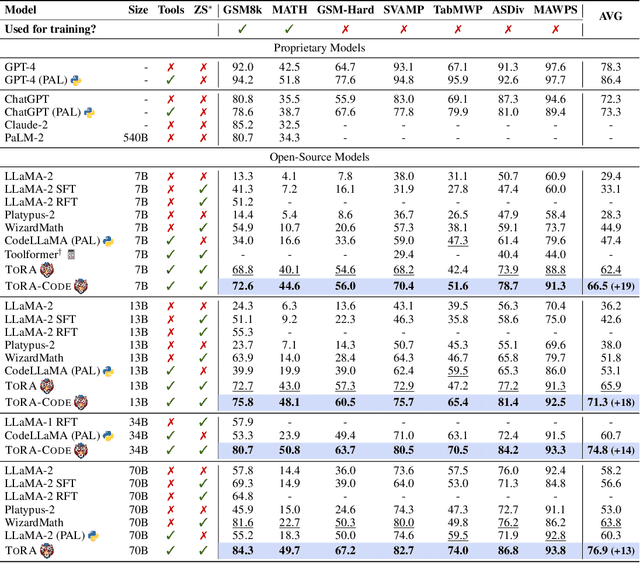
Large language models have made significant progress in various language tasks, yet they still struggle with complex mathematics. In this paper, we propose ToRA a series of Tool-integrated Reasoning Agents designed to solve challenging mathematical problems by seamlessly integrating natural language reasoning with the utilization of external tools (e.g., computation libraries and symbolic solvers), thereby amalgamating the analytical prowess of language and the computational efficiency of tools. To train ToRA, we curate interactive tool-use trajectories on mathematical datasets, apply imitation learning on the annotations, and propose output space shaping to further refine models' reasoning behavior. As a result, ToRA models significantly outperform open-source models on 10 mathematical reasoning datasets across all scales with 13%-19% absolute improvements on average. Notably, ToRA-7B reaches 44.6% on the competition-level dataset MATH, surpassing the best open-source model WizardMath-70B by 22% absolute. ToRA-Code-34B is also the first open-source model that achieves an accuracy exceeding 50% on MATH, which significantly outperforms GPT-4's CoT result, and is competitive with GPT-4 solving problems with programs. Additionally, we conduct a comprehensive analysis of the benefits and remaining challenges of tool interaction for mathematical reasoning, providing valuable insights for future research.
Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy
May 24, 2023
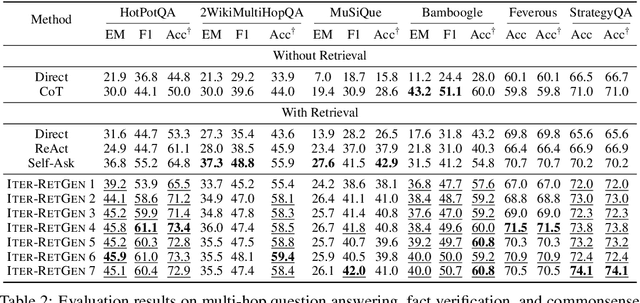


Large language models are powerful text processors and reasoners, but are still subject to limitations including outdated knowledge and hallucinations, which necessitates connecting them to the world. Retrieval-augmented large language models have raised extensive attention for grounding model generation on external knowledge. However, retrievers struggle to capture relevance, especially for queries with complex information needs. Recent work has proposed to improve relevance modeling by having large language models actively involved in retrieval, i.e., to improve retrieval with generation. In this paper, we show that strong performance can be achieved by a method we call Iter-RetGen, which synergizes retrieval and generation in an iterative manner. A model output shows what might be needed to finish a task, and thus provides an informative context for retrieving more relevant knowledge which in turn helps generate a better output in the next iteration. Compared with recent work which interleaves retrieval with generation when producing an output, Iter-RetGen processes all retrieved knowledge as a whole and largely preserves the flexibility in generation without structural constraints. We evaluate Iter-RetGen on multi-hop question answering, fact verification, and commonsense reasoning, and show that it can flexibly leverage parametric knowledge and non-parametric knowledge, and is superior to or competitive with state-of-the-art retrieval-augmented baselines while causing fewer overheads of retrieval and generation. We can further improve performance via generation-augmented retrieval adaptation.
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
May 19, 2023

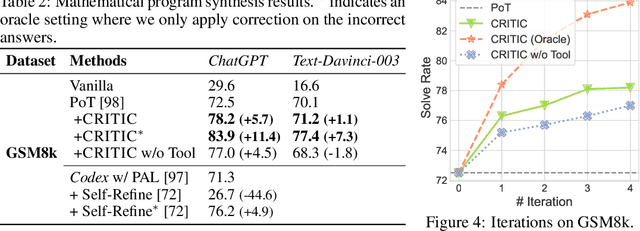
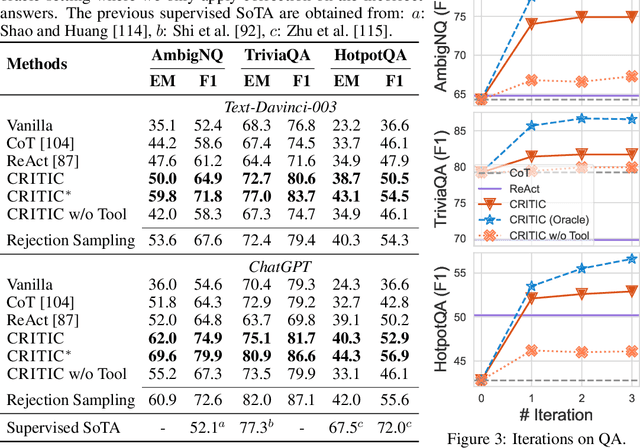
Recent developments in large language models (LLMs) have been impressive. However, these models sometimes show inconsistencies and problematic behavior, such as hallucinating facts, generating flawed code, or creating offensive and toxic content. Unlike these models, humans typically utilize external tools to cross-check and refine their initial content, like using a search engine for fact-checking, or a code interpreter for debugging. Inspired by this observation, we introduce a framework called CRITIC that allows LLMs, which are essentially "black boxes" to validate and progressively amend their own outputs in a manner similar to human interaction with tools. More specifically, starting with an initial output, CRITIC interacts with appropriate tools to evaluate certain aspects of the text, and then revises the output based on the feedback obtained during this validation process. Comprehensive evaluations involving free-form question answering, mathematical program synthesis, and toxicity reduction demonstrate that CRITIC consistently enhances the performance of LLMs. Meanwhile, our research highlights the crucial importance of external feedback in promoting the ongoing self-improvement of LLMs.
Synthetic Prompting: Generating Chain-of-Thought Demonstrations for Large Language Models
Feb 01, 2023

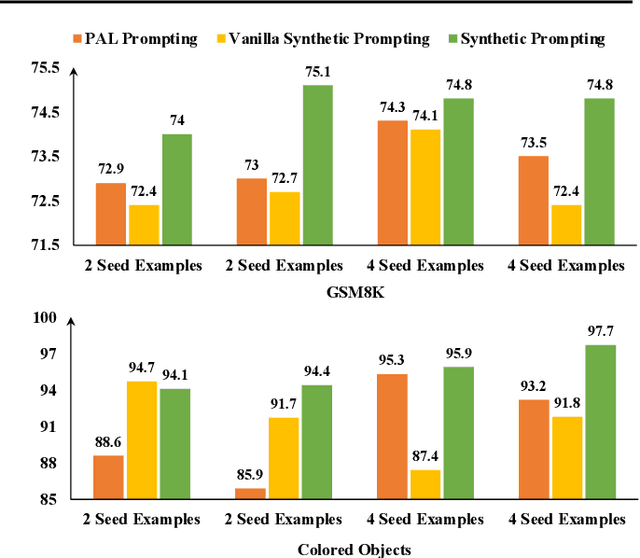
Large language models can perform various reasoning tasks by using chain-of-thought prompting, which guides them to find answers through step-by-step demonstrations. However, the quality of the prompts depends on the demonstrations given to the models, and creating many of them by hand is costly. We introduce Synthetic prompting, a method that leverages a few handcrafted examples to prompt the model to generate more examples by itself, and selects effective demonstrations to elicit better reasoning. Our method alternates between a backward and forward process to generate new examples. The backward process generates a question that match a sampled reasoning chain, so that the question is solvable and clear. The forward process produces a more detailed reasoning chain for the question, improving the quality of the example. We evaluate our method on numerical, symbolic, and algorithmic reasoning tasks, and show that it outperforms existing prompting techniques.
Chaining Simultaneous Thoughts for Numerical Reasoning
Nov 29, 2022

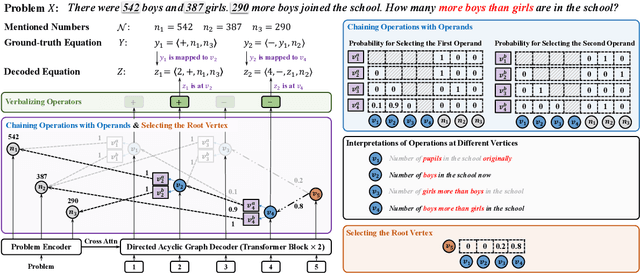
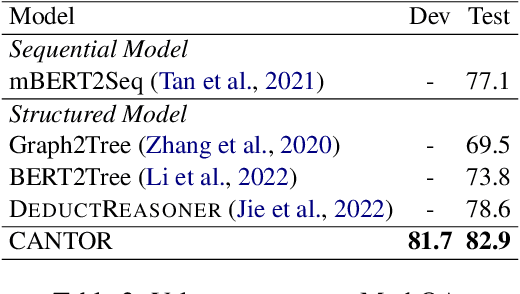
Given that rich information is hidden behind ubiquitous numbers in text, numerical reasoning over text should be an essential skill of AI systems. To derive precise equations to solve numerical reasoning problems, previous work focused on modeling the structures of equations, and has proposed various structured decoders. Though structure modeling proves to be effective, these structured decoders construct a single equation in a pre-defined autoregressive order, potentially placing an unnecessary restriction on how a model should grasp the reasoning process. Intuitively, humans may have numerous pieces of thoughts popping up in no pre-defined order; thoughts are not limited to the problem at hand, and can even be concerned with other related problems. By comparing diverse thoughts and chaining relevant pieces, humans are less prone to errors. In this paper, we take this inspiration and propose CANTOR, a numerical reasoner that models reasoning steps using a directed acyclic graph where we produce diverse reasoning steps simultaneously without pre-defined decoding dependencies, and compare and chain relevant ones to reach a solution. Extensive experiments demonstrated the effectiveness of CANTOR under both fully-supervised and weakly-supervised settings.
Tackling Multi-Answer Open-Domain Questions via a Recall-then-Verify Framework
Oct 16, 2021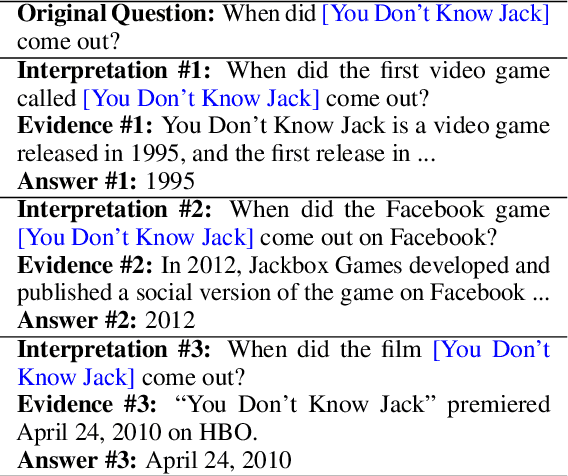
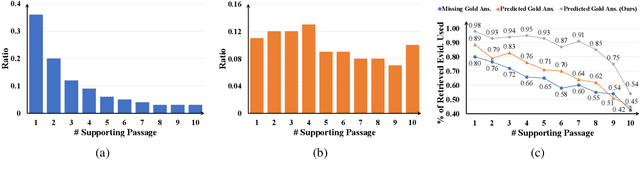


Open domain questions are likely to be open-ended and ambiguous, leading to multiple valid answers. Existing approaches typically adopt the rerank-then-read framework, where a reader reads top-ranking evidence to predict answers. According to our empirical analyses, this framework is faced with three problems: to leverage the power of a large reader, the reranker is forced to select only a few relevant passages that cover diverse answers, which is non-trivial due to unknown effect on the reader's performance; the small reading budget also prevents the reader from making use of valuable retrieved evidence filtered out by the reranker; besides, as the reader generates predictions all at once based on all selected evidence, it may learn pathological dependencies among answers, i.e., whether to predict an answer may also depend on evidence of the other answers. To avoid these problems, we propose to tackle multi-answer open-domain questions with a recall-then-verify framework, which separates the reasoning process of each answer so that we can make better use of retrieved evidence while also leveraging the power of large models under the same memory constraint. Our framework achieves new state-of-the-art results on two multi-answer datasets, and predicts significantly more gold answers than a rerank-then-read system with an oracle reranker.
A Mutual Information Maximization Approach for the Spurious Solution Problem in Weakly Supervised Question Answering
Jun 14, 2021


Weakly supervised question answering usually has only the final answers as supervision signals while the correct solutions to derive the answers are not provided. This setting gives rise to the spurious solution problem: there may exist many spurious solutions that coincidentally derive the correct answer, but training on such solutions can hurt model performance (e.g., producing wrong solutions or answers). For example, for discrete reasoning tasks as on DROP, there may exist many equations to derive a numeric answer, and typically only one of them is correct. Previous learning methods mostly filter out spurious solutions with heuristics or using model confidence, but do not explicitly exploit the semantic correlations between a question and its solution. In this paper, to alleviate the spurious solution problem, we propose to explicitly exploit such semantic correlations by maximizing the mutual information between question-answer pairs and predicted solutions. Extensive experiments on four question answering datasets show that our method significantly outperforms previous learning methods in terms of task performance and is more effective in training models to produce correct solutions.