 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiyue Wang
Explainable Interface for Human-Autonomy Teaming: A Survey
May 04, 2024
Nowadays, large-scale foundation models are being increasingly integrated into numerous safety-critical applications, including human-autonomy teaming (HAT) within transportation, medical, and defence domains. Consequently, the inherent 'black-box' nature of these sophisticated deep neural networks heightens the significance of fostering mutual understanding and trust between humans and autonomous systems. To tackle the transparency challenges in HAT, this paper conducts a thoughtful study on the underexplored domain of Explainable Interface (EI) in HAT systems from a human-centric perspective, thereby enriching the existing body of research in Explainable Artificial Intelligence (XAI). We explore the design, development, and evaluation of EI within XAI-enhanced HAT systems. To do so, we first clarify the distinctions between these concepts: EI, explanations and model explainability, aiming to provide researchers and practitioners with a structured understanding. Second, we contribute to a novel framework for EI, addressing the unique challenges in HAT. Last, our summarized evaluation framework for ongoing EI offers a holistic perspective, encompassing model performance, human-centered factors, and group task objectives. Based on extensive surveys across XAI, HAT, psychology, and Human-Computer Interaction (HCI), this review offers multiple novel insights into incorporating XAI into HAT systems and outlines future directions.
DAWN: Domain-Adaptive Weakly Supervised Nuclei Segmentation via Cross-Task Interactions
Apr 24, 2024Weakly supervised segmentation methods have gained significant attention due to their ability to reduce the reliance on costly pixel-level annotations during model training. However, the current weakly supervised nuclei segmentation approaches typically follow a two-stage pseudo-label generation and network training process. The performance of the nuclei segmentation heavily relies on the quality of the generated pseudo-labels, thereby limiting its effectiveness. This paper introduces a novel domain-adaptive weakly supervised nuclei segmentation framework using cross-task interaction strategies to overcome the challenge of pseudo-label generation. Specifically, we utilize weakly annotated data to train an auxiliary detection task, which assists the domain adaptation of the segmentation network. To enhance the efficiency of domain adaptation, we design a consistent feature constraint module integrating prior knowledge from the source domain. Furthermore, we develop pseudo-label optimization and interactive training methods to improve the domain transfer capability. To validate the effectiveness of our proposed method, we conduct extensive comparative and ablation experiments on six datasets. The results demonstrate the superiority of our approach over existing weakly supervised approaches. Remarkably, our method achieves comparable or even better performance than fully supervised methods. Our code will be released in https://github.com/zhangye-zoe/DAWN.
CODIS: Benchmarking Context-Dependent Visual Comprehension for Multimodal Large Language Models
Feb 21, 2024Multimodal large language models (MLLMs) have demonstrated promising results in a variety of tasks that combine vision and language. As these models become more integral to research and applications, conducting comprehensive evaluations of their capabilities has grown increasingly important. However, most existing benchmarks fail to consider that, in certain situations, images need to be interpreted within a broader context. In this work, we introduce a new benchmark, named as CODIS, designed to assess the ability of models to use context provided in free-form text to enhance visual comprehension. Our findings indicate that MLLMs consistently fall short of human performance on this benchmark. Further analysis confirms that these models struggle to effectively extract and utilize contextual information to improve their understanding of images. This underscores the pressing need to enhance the ability of MLLMs to comprehend visuals in a context-dependent manner. View our project website at https://thunlp-mt.github.io/CODIS.
Model Composition for Multimodal Large Language Models
Feb 20, 2024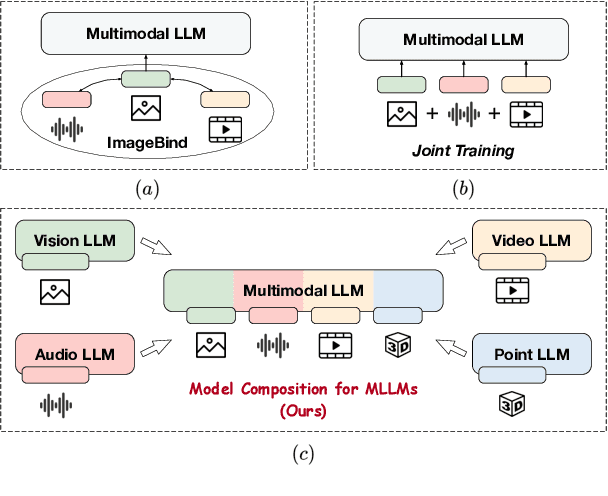
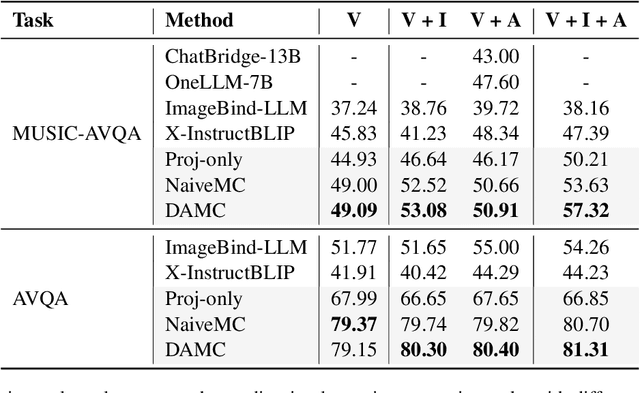
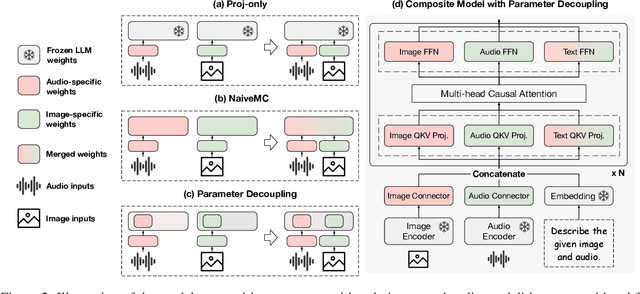
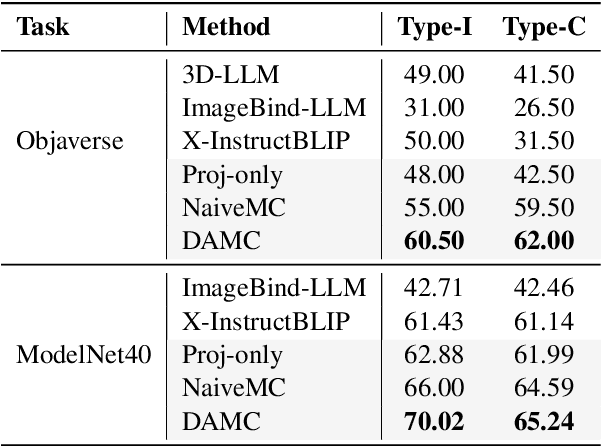
Recent developments in Multimodal Large Language Models (MLLMs) have shown rapid progress, moving towards the goal of creating versatile MLLMs that understand inputs from various modalities. However, existing methods typically rely on joint training with paired multimodal instruction data, which is resource-intensive and challenging to extend to new modalities. In this paper, we propose a new paradigm through the model composition of existing MLLMs to create a new model that retains the modal understanding capabilities of each original model. Our basic implementation, NaiveMC, demonstrates the effectiveness of this paradigm by reusing modality encoders and merging LLM parameters. Furthermore, we introduce DAMC to address parameter interference and mismatch issues during the merging process, thereby enhancing the model performance. To facilitate research in this area, we propose MCUB, a benchmark for assessing ability of MLLMs to understand inputs from diverse modalities. Experiments on this benchmark and four other multimodal understanding tasks show significant improvements over baselines, proving that model composition can create a versatile model capable of processing inputs from multiple modalities.
Browse and Concentrate: Comprehending Multimodal Content via prior-LLM Context Fusion
Feb 19, 2024
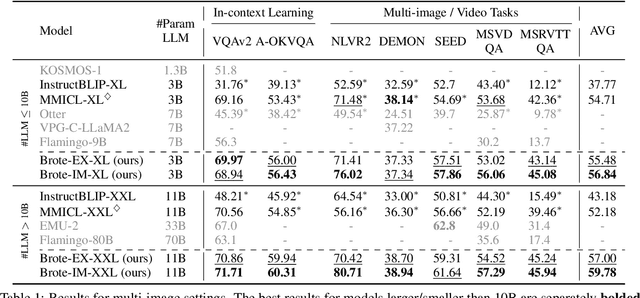
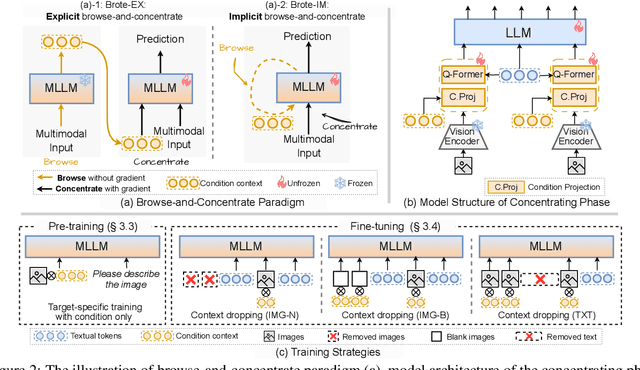
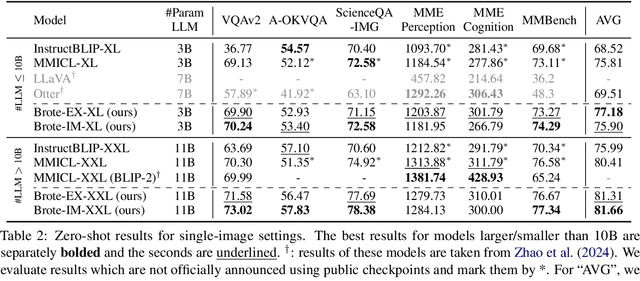
With the bloom of Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) that incorporate LLMs with pre-trained vision models have recently demonstrated impressive performance across diverse vision-language tasks. However, they fall short to comprehend context involving multiple images. A primary reason for this shortcoming is that the visual features for each images are encoded individually by frozen encoders before feeding into the LLM backbone, lacking awareness of other images and the multimodal instructions. We term this issue as prior-LLM modality isolation and propose a two phase paradigm, browse-and-concentrate, to enable in-depth multimodal context fusion prior to feeding the features into LLMs. This paradigm initially "browses" through the inputs for essential insights, and then revisits the inputs to "concentrate" on crucial details, guided by these insights, to achieve a more comprehensive understanding of the multimodal inputs. Additionally, we develop training strategies specifically to enhance the understanding of multi-image inputs. Our method markedly boosts the performance on 7 multi-image scenarios, contributing to increments on average accuracy by 2.13% and 7.60% against strong MLLMs baselines with 3B and 11B LLMs, respectively.
Boundary-aware Contrastive Learning for Semi-supervised Nuclei Instance Segmentation
Feb 07, 2024Semi-supervised segmentation methods have demonstrated promising results in natural scenarios, providing a solution to reduce dependency on manual annotation. However, these methods face significant challenges when directly applied to pathological images due to the subtle color differences between nuclei and tissues, as well as the significant morphological variations among nuclei. Consequently, the generated pseudo-labels often contain much noise, especially at the nuclei boundaries. To address the above problem, this paper proposes a boundary-aware contrastive learning network to denoise the boundary noise in a semi-supervised nuclei segmentation task. The model has two key designs: a low-resolution denoising (LRD) module and a cross-RoI contrastive learning (CRC) module. The LRD improves the smoothness of the nuclei boundary by pseudo-labels denoising, and the CRC enhances the discrimination between foreground and background by boundary feature contrastive learning. We conduct extensive experiments to demonstrate the superiority of our proposed method over existing semi-supervised instance segmentation methods.
SEINE: Structure Encoding and Interaction Network for Nuclei Instance Segmentation
Jan 18, 2024Nuclei instance segmentation in histopathological images is of great importance for biological analysis and cancer diagnosis but remains challenging for two reasons. (1) Similar visual presentation of intranuclear and extranuclear regions of chromophobe nuclei often causes under-segmentation, and (2) current methods lack the exploration of nuclei structure, resulting in fragmented instance predictions. To address these problems, this paper proposes a structure encoding and interaction network, termed SEINE, which develops the structure modeling scheme of nuclei and exploits the structure similarity between nuclei to improve the integrality of each segmented instance. Concretely, SEINE introduces a contour-based structure encoding (SE) that considers the correlation between nuclei structure and semantics, realizing a reasonable representation of the nuclei structure. Based on the encoding, we propose a structure-guided attention (SGA) that takes the clear nuclei as prototypes to enhance the structure learning for the fuzzy nuclei. To strengthen the structural learning ability, a semantic feature fusion (SFF) is presented to boost the semantic consistency of semantic and structure branches. Furthermore, a position enhancement (PE) method is applied to suppress incorrect nuclei boundary predictions. Extensive experiments demonstrate the superiority of our approaches, and SEINE achieves state-of-the-art (SOTA) performance on four datasets. The code is available at \href{https://github.com/zhangye-zoe/SEINE}{https://github.com/zhangye-zoe/SEINE}.
Covariance-Based Activity Detection in Cooperative Multi-Cell Massive MIMO: Scaling Law and Efficient Algorithms
Nov 26, 2023This paper focuses on the covariance-based activity detection problem in a multi-cell massive multiple-input multiple-output (MIMO) system. In this system, active devices transmit their signature sequences to multiple base stations (BSs), and the BSs cooperatively detect the active devices based on the received signals. While the scaling law for the covariance-based activity detection in the single-cell scenario has been extensively analyzed in the literature, this paper aims to analyze the scaling law for the covariance-based activity detection in the multi-cell massive MIMO system. Specifically, this paper demonstrates a quadratic scaling law in the multi-cell system, under the assumption that the exponent in the classical path-loss model is greater than 2. This finding shows that, in the multi-cell MIMO system, the maximum number of active devices that can be detected correctly in each cell increases quadratically with the length of the signature sequence and decreases logarithmically with the number of cells (as the number of antennas tends to infinity). Moreover, in addition to analyzing the scaling law for the signature sequences randomly and uniformly distributed on a sphere, the paper also establishes the scaling law for signature sequences generated from a finite alphabet, which are easier to generate and store. Moreover, this paper proposes two efficient accelerated coordinate descent (CD) algorithms with a convergence guarantee for solving the device activity detection problem. The first algorithm reduces the complexity of CD by using an inexact coordinate update strategy. The second algorithm avoids unnecessary computations of CD by using an active set selection strategy. Simulation results show that the proposed algorithms exhibit excellent performance in terms of computational efficiency and detection error probability.
Filling the Image Information Gap for VQA: Prompting Large Language Models to Proactively Ask Questions
Nov 20, 2023

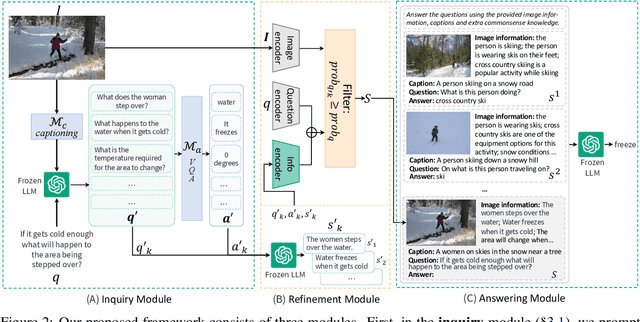
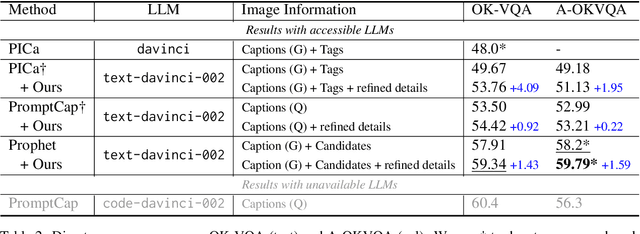
Large Language Models (LLMs) demonstrate impressive reasoning ability and the maintenance of world knowledge not only in natural language tasks, but also in some vision-language tasks such as open-domain knowledge-based visual question answering (OK-VQA). As images are invisible to LLMs, researchers convert images to text to engage LLMs into the visual question reasoning procedure. This leads to discrepancies between images and their textual representations presented to LLMs, which consequently impedes final reasoning performance. To fill the information gap and better leverage the reasoning capability, we design a framework that enables LLMs to proactively ask relevant questions to unveil more details in the image, along with filters for refining the generated information. We validate our idea on OK-VQA and A-OKVQA. Our method continuously boosts the performance of baselines methods by an average gain of 2.15% on OK-VQA, and achieves consistent improvements across different LLMs.
Octopus: Embodied Vision-Language Programmer from Environmental Feedback
Oct 12, 2023

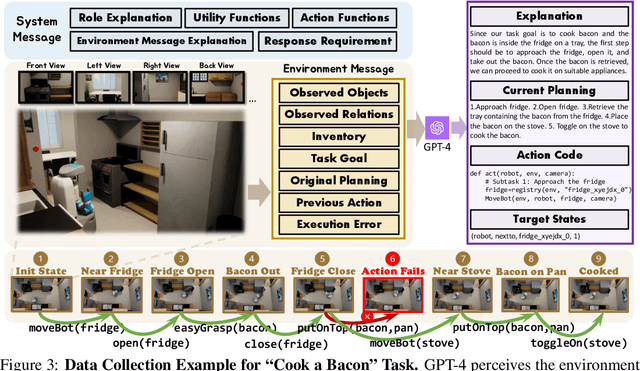
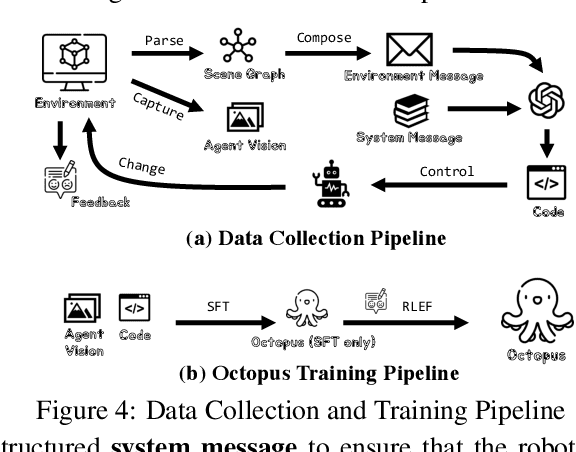
Large vision-language models (VLMs) have achieved substantial progress in multimodal perception and reasoning. Furthermore, when seamlessly integrated into an embodied agent, it signifies a crucial stride towards the creation of autonomous and context-aware systems capable of formulating plans and executing commands with precision. In this paper, we introduce Octopus, a novel VLM designed to proficiently decipher an agent's vision and textual task objectives and to formulate intricate action sequences and generate executable code. Our design allows the agent to adeptly handle a wide spectrum of tasks, ranging from mundane daily chores in simulators to sophisticated interactions in complex video games. Octopus is trained by leveraging GPT-4 to control an explorative agent to generate training data, i.e., action blueprints and the corresponding executable code, within our experimental environment called OctoVerse. We also collect the feedback that allows the enhanced training scheme of Reinforcement Learning with Environmental Feedback (RLEF). Through a series of experiments, we illuminate Octopus's functionality and present compelling results, and the proposed RLEF turns out to refine the agent's decision-making. By open-sourcing our model architecture, simulator, and dataset, we aspire to ignite further innovation and foster collaborative applications within the broader embodied AI community.