 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Da": models, code, and papers
Fuxi-DA: A Generalized Deep Learning Data Assimilation Framework for Assimilating Satellite Observations
Apr 12, 2024
Data assimilation (DA), as an indispensable component within contemporary Numerical Weather Prediction (NWP) systems, plays a crucial role in generating the analysis that significantly impacts forecast performance. Nevertheless, the development of an efficient DA system poses significant challenges, particularly in establishing intricate relationships between the background data and the vast amount of multi-source observation data within limited time windows in operational settings. To address these challenges, researchers design complex pre-processing methods for each observation type, leveraging approximate modeling and the power of super-computing clusters to expedite solutions. The emergence of deep learning (DL) models has been a game-changer, offering unified multi-modal modeling, enhanced nonlinear representation capabilities, and superior parallelization. These advantages have spurred efforts to integrate DL models into various domains of weather modeling. Remarkably, DL models have shown promise in matching, even surpassing, the forecast accuracy of leading operational NWP models worldwide. This success motivates the exploration of DL-based DA frameworks tailored for weather forecasting models. In this study, we introduces FuxiDA, a generalized DL-based DA framework for assimilating satellite observations. By assimilating data from Advanced Geosynchronous Radiation Imager (AGRI) aboard Fengyun-4B, FuXi-DA consistently mitigates analysis errors and significantly improves forecast performance. Furthermore, through a series of single-observation experiments, Fuxi-DA has been validated against established atmospheric physics, demonstrating its consistency and reliability.
A Realistic Surgical Simulator for Non-Rigid and Contact-Rich Manipulation in Surgeries with the da Vinci Research Kit
Apr 08, 2024Realistic real-time surgical simulators play an increasingly important role in surgical robotics research, such as surgical robot learning and automation, and surgical skills assessment. Although there are a number of existing surgical simulators for research, they generally lack the ability to simulate the diverse types of objects and contact-rich manipulation tasks typically present in surgeries, such as tissue cutting and blood suction. In this work, we introduce CRESSim, a realistic surgical simulator based on PhysX 5 for the da Vinci Research Kit (dVRK) that enables simulating various contact-rich surgical tasks involving different surgical instruments, soft tissue, and body fluids. The real-world dVRK console and the master tool manipulator (MTM) robots are incorporated into the system to allow for teleoperation through virtual reality (VR). To showcase the advantages and potentials of the simulator, we present three examples of surgical tasks, including tissue grasping and deformation, blood suction, and tissue cutting. These tasks are performed using the simulated surgical instruments, including the large needle driver, suction irrigator, and curved scissor, through VR-based teleoperation.
Decoding AI: The inside story of data analysis in ChatGPT
Apr 12, 2024As a result of recent advancements in generative AI, the field of Data Science is prone to various changes. This review critically examines the Data Analysis (DA) capabilities of ChatGPT assessing its performance across a wide range of tasks. While DA provides researchers and practitioners with unprecedented analytical capabilities, it is far from being perfect, and it is important to recognize and address its limitations.
DA-PFL: Dynamic Affinity Aggregation for Personalized Federated Learning
Mar 14, 2024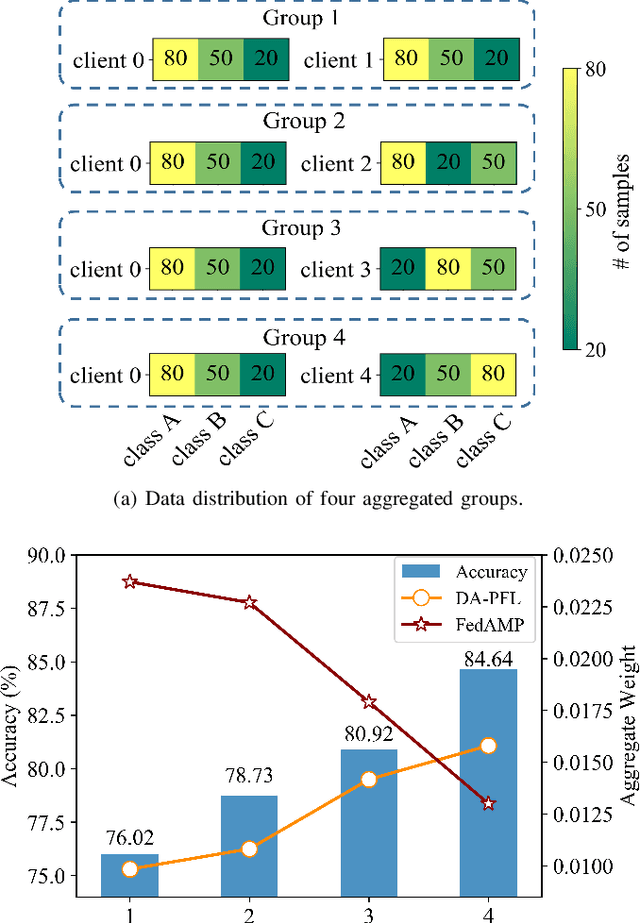
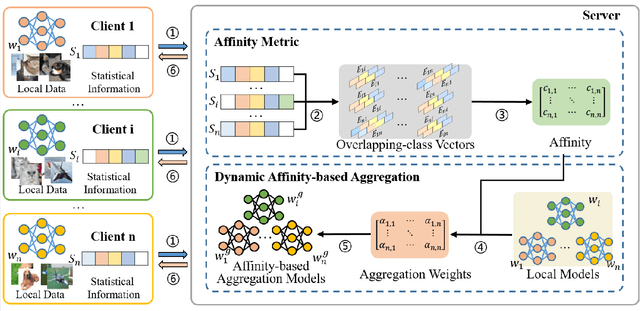
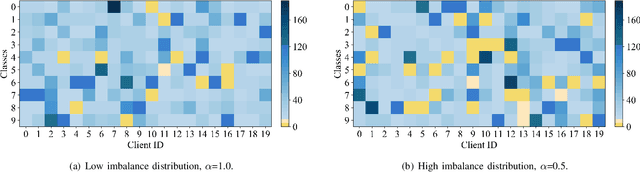
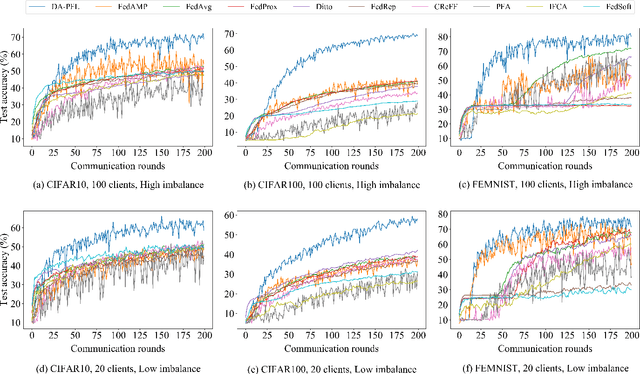
Personalized federated learning becomes a hot research topic that can learn a personalized learning model for each client. Existing personalized federated learning models prefer to aggregate similar clients with similar data distribution to improve the performance of learning models. However, similaritybased personalized federated learning methods may exacerbate the class imbalanced problem. In this paper, we propose a novel Dynamic Affinity-based Personalized Federated Learning model (DA-PFL) to alleviate the class imbalanced problem during federated learning. Specifically, we build an affinity metric from a complementary perspective to guide which clients should be aggregated. Then we design a dynamic aggregation strategy to dynamically aggregate clients based on the affinity metric in each round to reduce the class imbalanced risk. Extensive experiments show that the proposed DA-PFL model can significantly improve the accuracy of each client in three real-world datasets with state-of-the-art comparison methods.
CGNSDE: Conditional Gaussian Neural Stochastic Differential Equation for Modeling Complex Systems and Data Assimilation
Apr 10, 2024A new knowledge-based and machine learning hybrid modeling approach, called conditional Gaussian neural stochastic differential equation (CGNSDE), is developed to facilitate modeling complex dynamical systems and implementing analytic formulae of the associated data assimilation (DA). In contrast to the standard neural network predictive models, the CGNSDE is designed to effectively tackle both forward prediction tasks and inverse state estimation problems. The CGNSDE starts by exploiting a systematic causal inference via information theory to build a simple knowledge-based nonlinear model that nevertheless captures as much explainable physics as possible. Then, neural networks are supplemented to the knowledge-based model in a specific way, which not only characterizes the remaining features that are challenging to model with simple forms but also advances the use of analytic formulae to efficiently compute the nonlinear DA solution. These analytic formulae are used as an additional computationally affordable loss to train the neural networks that directly improve the DA accuracy. This DA loss function promotes the CGNSDE to capture the interactions between state variables and thus advances its modeling skills. With the DA loss, the CGNSDE is more capable of estimating extreme events and quantifying the associated uncertainty. Furthermore, crucial physical properties in many complex systems, such as the translate-invariant local dependence of state variables, can significantly simplify the neural network structures and facilitate the CGNSDE to be applied to high-dimensional systems. Numerical experiments based on chaotic systems with intermittency and strong non-Gaussian features indicate that the CGNSDE outperforms knowledge-based regression models, and the DA loss further enhances the modeling skills of the CGNSDE.
Control-DAG: Constrained Decoding for Non-Autoregressive Directed Acyclic T5 using Weighted Finite State Automata
Apr 10, 2024The Directed Acyclic Transformer is a fast non-autoregressive (NAR) model that performs well in Neural Machine Translation. Two issues prevent its application to general Natural Language Generation (NLG) tasks: frequent Out-Of-Vocabulary (OOV) errors and the inability to faithfully generate entity names. We introduce Control-DAG, a constrained decoding algorithm for our Directed Acyclic T5 (DA-T5) model which offers lexical, vocabulary and length control. We show that Control-DAG significantly enhances DA-T5 on the Schema Guided Dialogue and the DART datasets, establishing strong NAR results for Task-Oriented Dialogue and Data-to-Text NLG.
A Modified da Vinci Surgical Instrument for OCE based Elasticity Estimation with Deep Learning
Mar 14, 2024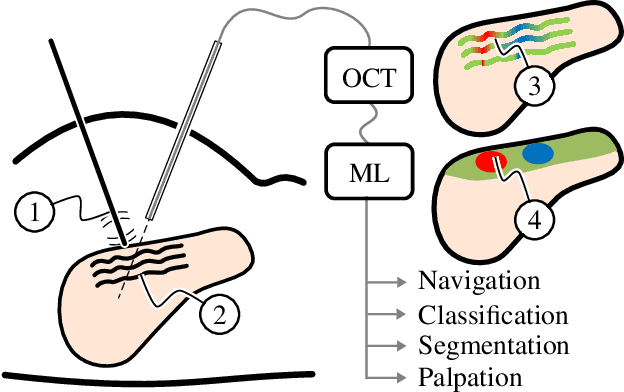
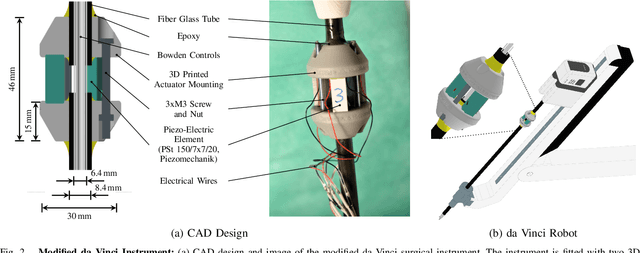
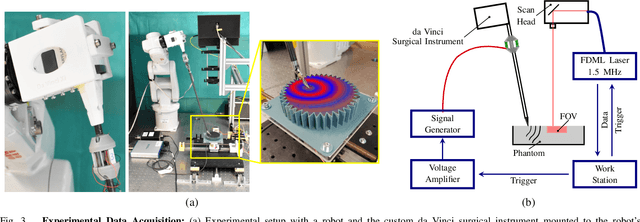
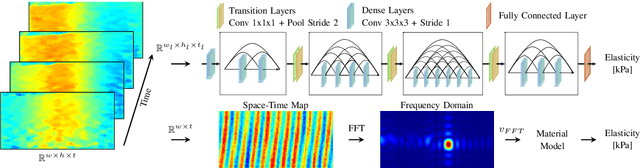
Robot-assisted surgery has advantages compared to conventional laparoscopic procedures, e.g., precise movement of the surgical instruments, improved dexterity, and high-resolution visualization of the surgical field. However, mechanical tissue properties may provide additional information, e.g., on the location of lesions or vessels. While elastographic imaging has been proposed, it is not readily available as an online modality during robot-assisted surgery. We propose modifying a da~Vinci surgical instrument to realize optical coherence elastography (OCE) for quantitative elasticity estimation. The modified da~Vinci instrument is equipped with piezoelectric elements for shear wave excitation and we employ fast optical coherence tomography (OCT) imaging to track propagating wave fields, which are directly related to biomechanical tissue properties. All high-voltage components are mounted at the proximal end outside the patient. We demonstrate that external excitation at the instrument shaft can effectively stimulate shear waves, even when considering damping. Comparing conventional and deep learning-based signal processing, resulting in mean absolute errors of 19.27 kPa and 6.29 kPa, respectively. These results illustrate that precise quantitative elasticity estimates can be obtained. We also demonstrate quantitative elasticity estimation on ex-vivo tissue samples of heart, liver and stomach, and show that the measurements can be used to distinguish soft and stiff tissue types.
MoCap-to-Visual Domain Adaptation for Efficient Human Mesh Estimation from 2D Keypoints
Apr 10, 2024This paper presents Key2Mesh, a model that takes a set of 2D human pose keypoints as input and estimates the corresponding body mesh. Since this process does not involve any visual (i.e. RGB image) data, the model can be trained on large-scale motion capture (MoCap) datasets, thereby overcoming the scarcity of image datasets with 3D labels. To enable the model's application on RGB images, we first run an off-the-shelf 2D pose estimator to obtain the 2D keypoints, and then feed these 2D keypoints to Key2Mesh. To improve the performance of our model on RGB images, we apply an adversarial domain adaptation (DA) method to bridge the gap between the MoCap and visual domains. Crucially, our DA method does not require 3D labels for visual data, which enables adaptation to target sets without the need for costly labels. We evaluate Key2Mesh for the task of estimating 3D human meshes from 2D keypoints, in the absence of RGB and mesh label pairs. Our results on widely used H3.6M and 3DPW datasets show that Key2Mesh sets the new state-of-the-art by outperforming other models in PA-MPJPE for both datasets, and in MPJPE and PVE for the 3DPW dataset. Thanks to our model's simple architecture, it operates at least 12x faster than the prior state-of-the-art model, LGD. Additional qualitative samples and code are available on the project website: https://key2mesh.github.io/.
iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection
Apr 08, 2024Recent progress has shown great potential of visual prompt tuning (VPT) when adapting pre-trained vision transformers to various downstream tasks. However, most existing solutions independently optimize prompts at each layer, thereby neglecting the usage of task-relevant information encoded in prompt tokens across layers. Additionally, existing prompt structures are prone to interference from task-irrelevant noise in input images, which can do harm to the sharing of task-relevant information. In this paper, we propose a novel VPT approach, \textbf{iVPT}. It innovatively incorporates a cross-layer dynamic connection (CDC) for input prompt tokens from adjacent layers, enabling effective sharing of task-relevant information. Furthermore, we design a dynamic aggregation (DA) module that facilitates selective sharing of information between layers. The combination of CDC and DA enhances the flexibility of the attention process within the VPT framework. Building upon these foundations, iVPT introduces an attentive reinforcement (AR) mechanism, by automatically identifying salient image tokens, which are further enhanced by prompt tokens in an additive manner. Extensive experiments on 24 image classification and semantic segmentation benchmarks clearly demonstrate the advantage of the proposed iVPT, compared to the state-of-the-art counterparts.
SF(DA)$^2$: Source-free Domain Adaptation Through the Lens of Data Augmentation
Mar 16, 2024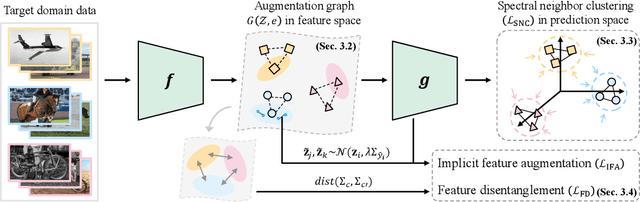
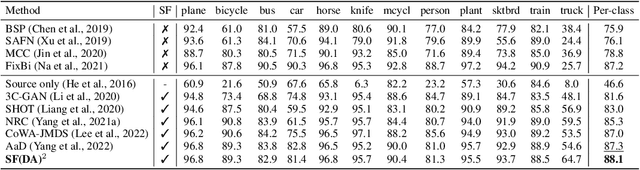
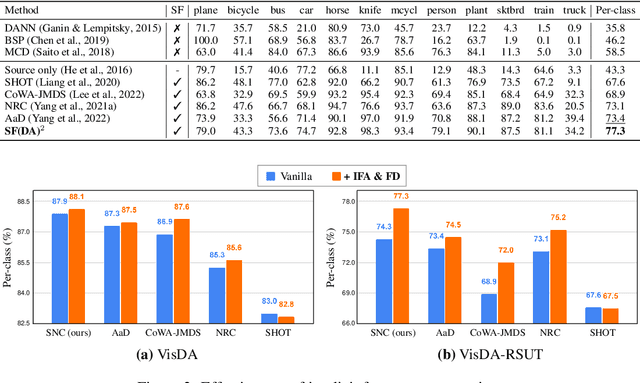
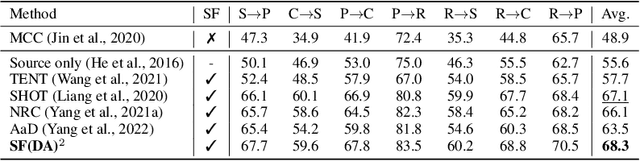
In the face of the deep learning model's vulnerability to domain shift, source-free domain adaptation (SFDA) methods have been proposed to adapt models to new, unseen target domains without requiring access to source domain data. Although the potential benefits of applying data augmentation to SFDA are attractive, several challenges arise such as the dependence on prior knowledge of class-preserving transformations and the increase in memory and computational requirements. In this paper, we propose Source-free Domain Adaptation Through the Lens of Data Augmentation (SF(DA)$^2$), a novel approach that leverages the benefits of data augmentation without suffering from these challenges. We construct an augmentation graph in the feature space of the pretrained model using the neighbor relationships between target features and propose spectral neighborhood clustering to identify partitions in the prediction space. Furthermore, we propose implicit feature augmentation and feature disentanglement as regularization loss functions that effectively utilize class semantic information within the feature space. These regularizers simulate the inclusion of an unlimited number of augmented target features into the augmentation graph while minimizing computational and memory demands. Our method shows superior adaptation performance in SFDA scenarios, including 2D image and 3D point cloud datasets and a highly imbalanced dataset.