 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"magic": models, code, and papers
Magic-Boost: Boost 3D Generation with Mutli-View Conditioned Diffusion
Apr 09, 2024
Benefiting from the rapid development of 2D diffusion models, 3D content creation has made significant progress recently. One promising solution involves the fine-tuning of pre-trained 2D diffusion models to harness their capacity for producing multi-view images, which are then lifted into accurate 3D models via methods like fast-NeRFs or large reconstruction models. However, as inconsistency still exists and limited generated resolution, the generation results of such methods still lack intricate textures and complex geometries. To solve this problem, we propose Magic-Boost, a multi-view conditioned diffusion model that significantly refines coarse generative results through a brief period of SDS optimization ($\sim15$min). Compared to the previous text or single image based diffusion models, Magic-Boost exhibits a robust capability to generate images with high consistency from pseudo synthesized multi-view images. It provides precise SDS guidance that well aligns with the identity of the input images, enriching the local detail in both geometry and texture of the initial generative results. Extensive experiments show Magic-Boost greatly enhances the coarse inputs and generates high-quality 3D assets with rich geometric and textural details. (Project Page: https://magic-research.github.io/magic-boost/)
Magic Clothing: Controllable Garment-Driven Image Synthesis
Apr 15, 2024We propose Magic Clothing, a latent diffusion model (LDM)-based network architecture for an unexplored garment-driven image synthesis task. Aiming at generating customized characters wearing the target garments with diverse text prompts, the image controllability is the most critical issue, i.e., to preserve the garment details and maintain faithfulness to the text prompts. To this end, we introduce a garment extractor to capture the detailed garment features, and employ self-attention fusion to incorporate them into the pretrained LDMs, ensuring that the garment details remain unchanged on the target character. Then, we leverage the joint classifier-free guidance to balance the control of garment features and text prompts over the generated results. Meanwhile, the proposed garment extractor is a plug-in module applicable to various finetuned LDMs, and it can be combined with other extensions like ControlNet and IP-Adapter to enhance the diversity and controllability of the generated characters. Furthermore, we design Matched-Points-LPIPS (MP-LPIPS), a robust metric for evaluating the consistency of the target image to the source garment. Extensive experiments demonstrate that our Magic Clothing achieves state-of-the-art results under various conditional controls for garment-driven image synthesis. Our source code is available at https://github.com/ShineChen1024/MagicClothing.
(Un)making AI Magic: a Design Taxonomy
Mar 22, 2024This paper examines the role that enchantment plays in the design of AI things by constructing a taxonomy of design approaches that increase or decrease the perception of magic and enchantment. We start from the design discourse surrounding recent developments in AI technologies, highlighting specific interaction qualities such as algorithmic uncertainties and errors and articulating relations to the rhetoric of magic and supernatural thinking. Through analyzing and reflecting upon 52 students' design projects from two editions of a Master course in design and AI, we identify seven design principles and unpack the effects of each in terms of enchantment and disenchantment. We conclude by articulating ways in which this taxonomy can be approached and appropriated by design/HCI practitioners, especially to support exploration and reflexivity.
Magic for the Age of Quantized DNNs
Mar 22, 2024Recently, the number of parameters in DNNs has explosively increased, as exemplified by LLMs (Large Language Models), making inference on small-scale computers more difficult. Model compression technology is, therefore, essential for integration into products. In this paper, we propose a method of quantization-aware training. We introduce a novel normalization (Layer-Batch Normalization) that is independent of the mini-batch size and does not require any additional computation cost during inference. Then, we quantize the weights by the scaled round-clip function with the weight standardization. We also quantize activation functions using the same function and apply surrogate gradients to train the model with both quantized weights and the quantized activation functions. We call this method Magic for the age of Quantised DNNs (MaQD). Experimental results show that our quantization method can be achieved with minimal accuracy degradation.
FastSpell: the LangId Magic Spell
Apr 12, 2024Language identification is a crucial component in the automated production of language resources, particularly in multilingual and big data contexts. However, commonly used language identifiers struggle to differentiate between similar or closely-related languages. This paper introduces FastSpell, a language identifier that combines fastText (a pre-trained language identifier tool) and Hunspell (a spell checker) with the aim of having a refined second-opinion before deciding which language should be assigned to a text. We provide a description of the FastSpell algorithm along with an explanation on how to use and configure it. To that end, we motivate the need of such a tool and present a benchmark including some popular language identifiers evaluated during the development of FastSpell. We show how FastSpell is useful not only to improve identification of similar languages, but also to identify new ones ignored by other tools.
MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators
Apr 07, 2024Recent advances in Text-to-Video generation (T2V) have achieved remarkable success in synthesizing high-quality general videos from textual descriptions. A largely overlooked problem in T2V is that existing models have not adequately encoded physical knowledge of the real world, thus generated videos tend to have limited motion and poor variations. In this paper, we propose \textbf{MagicTime}, a metamorphic time-lapse video generation model, which learns real-world physics knowledge from time-lapse videos and implements metamorphic generation. First, we design a MagicAdapter scheme to decouple spatial and temporal training, encode more physical knowledge from metamorphic videos, and transform pre-trained T2V models to generate metamorphic videos. Second, we introduce a Dynamic Frames Extraction strategy to adapt to metamorphic time-lapse videos, which have a wider variation range and cover dramatic object metamorphic processes, thus embodying more physical knowledge than general videos. Finally, we introduce a Magic Text-Encoder to improve the understanding of metamorphic video prompts. Furthermore, we create a time-lapse video-text dataset called \textbf{ChronoMagic}, specifically curated to unlock the metamorphic video generation ability. Extensive experiments demonstrate the superiority and effectiveness of MagicTime for generating high-quality and dynamic metamorphic videos, suggesting time-lapse video generation is a promising path toward building metamorphic simulators of the physical world.
Magic-Me: Identity-Specific Video Customized Diffusion
Feb 14, 2024Creating content for a specific identity (ID) has shown significant interest in the field of generative models. In the field of text-to-image generation (T2I), subject-driven content generation has achieved great progress with the ID in the images controllable. However, extending it to video generation is not well explored. In this work, we propose a simple yet effective subject identity controllable video generation framework, termed Video Custom Diffusion (VCD). With a specified subject ID defined by a few images, VCD reinforces the identity information extraction and injects frame-wise correlation at the initialization stage for stable video outputs with identity preserved to a large extent. To achieve this, we propose three novel components that are essential for high-quality ID preservation: 1) an ID module trained with the cropped identity by prompt-to-segmentation to disentangle the ID information and the background noise for more accurate ID token learning; 2) a text-to-video (T2V) VCD module with 3D Gaussian Noise Prior for better inter-frame consistency and 3) video-to-video (V2V) Face VCD and Tiled VCD modules to deblur the face and upscale the video for higher resolution. Despite its simplicity, we conducted extensive experiments to verify that VCD is able to generate stable and high-quality videos with better ID over the selected strong baselines. Besides, due to the transferability of the ID module, VCD is also working well with finetuned text-to-image models available publically, further improving its usability. The codes are available at https://github.com/Zhen-Dong/Magic-Me.
Magic Fixup: Streamlining Photo Editing by Watching Dynamic Videos
Mar 19, 2024
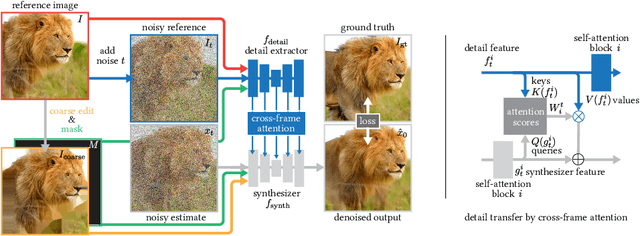


We propose a generative model that, given a coarsely edited image, synthesizes a photorealistic output that follows the prescribed layout. Our method transfers fine details from the original image and preserves the identity of its parts. Yet, it adapts it to the lighting and context defined by the new layout. Our key insight is that videos are a powerful source of supervision for this task: objects and camera motions provide many observations of how the world changes with viewpoint, lighting, and physical interactions. We construct an image dataset in which each sample is a pair of source and target frames extracted from the same video at randomly chosen time intervals. We warp the source frame toward the target using two motion models that mimic the expected test-time user edits. We supervise our model to translate the warped image into the ground truth, starting from a pretrained diffusion model. Our model design explicitly enables fine detail transfer from the source frame to the generated image, while closely following the user-specified layout. We show that by using simple segmentations and coarse 2D manipulations, we can synthesize a photorealistic edit faithful to the user's input while addressing second-order effects like harmonizing the lighting and physical interactions between edited objects.
Magic Tokens: Select Diverse Tokens for Multi-modal Object Re-Identification
Mar 15, 2024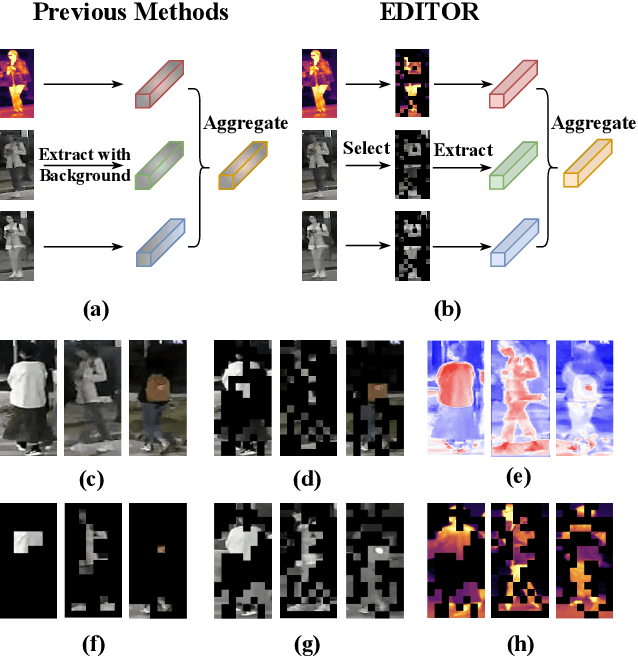
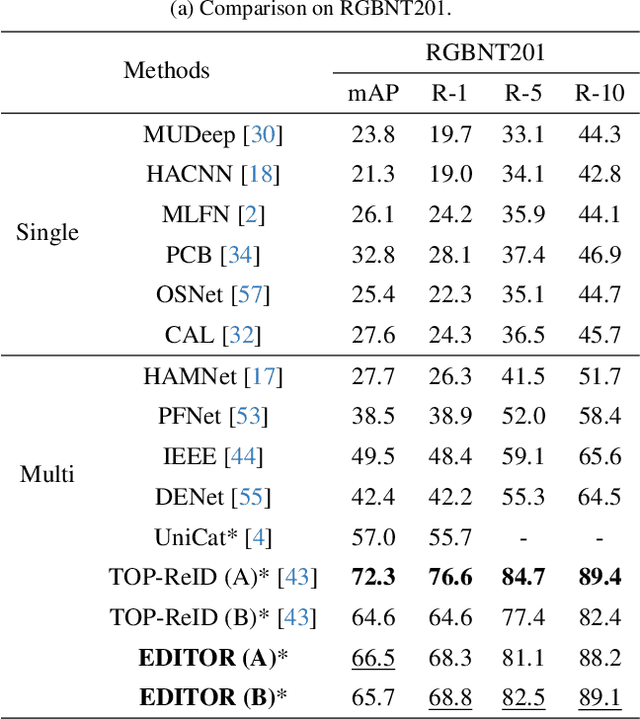
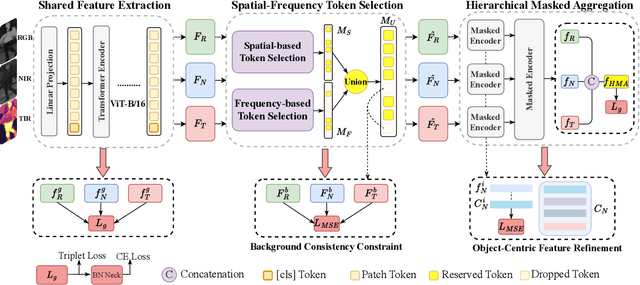
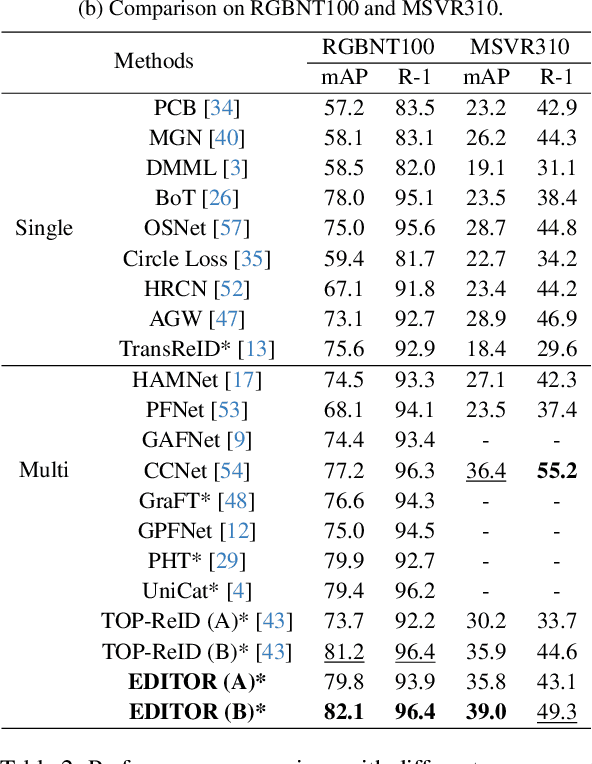
Single-modal object re-identification (ReID) faces great challenges in maintaining robustness within complex visual scenarios. In contrast, multi-modal object ReID utilizes complementary information from diverse modalities, showing great potentials for practical applications. However, previous methods may be easily affected by irrelevant backgrounds and usually ignore the modality gaps. To address above issues, we propose a novel learning framework named \textbf{EDITOR} to select diverse tokens from vision Transformers for multi-modal object ReID. We begin with a shared vision Transformer to extract tokenized features from different input modalities. Then, we introduce a Spatial-Frequency Token Selection (SFTS) module to adaptively select object-centric tokens with both spatial and frequency information. Afterwards, we employ a Hierarchical Masked Aggregation (HMA) module to facilitate feature interactions within and across modalities. Finally, to further reduce the effect of backgrounds, we propose a Background Consistency Constraint (BCC) and an Object-Centric Feature Refinement (OCFR). They are formulated as two new loss functions, which improve the feature discrimination with background suppression. As a result, our framework can generate more discriminative features for multi-modal object ReID. Extensive experiments on three multi-modal ReID benchmarks verify the effectiveness of our methods. The code is available at https://github.com/924973292/EDITOR.
Magic Markup: Maintaining Document-External Markup with an LLM
Mar 06, 2024

Text documents, including programs, typically have human-readable semantic structure. Historically, programmatic access to these semantics has required explicit in-document tagging. Especially in systems where the text has an execution semantics, this means it is an opt-in feature that is hard to support properly. Today, language models offer a new method: metadata can be bound to entities in changing text using a model's human-like understanding of semantics, with no requirements on the document structure. This method expands the applications of document annotation, a fundamental operation in program writing, debugging, maintenance, and presentation. We contribute a system that employs an intelligent agent to re-tag modified programs, enabling rich annotations to automatically follow code as it evolves. We also contribute a formal problem definition, an empirical synthetic benchmark suite, and our benchmark generator. Our system achieves an accuracy of 90% on our benchmarks and can replace a document's tags in parallel at a rate of 5 seconds per tag. While there remains significant room for improvement, we find performance reliable enough to justify further exploration of applications.