 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlex Warstadt
[Call for Papers] The 2nd BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus
Apr 09, 2024
After last year's successful BabyLM Challenge, the competition will be hosted again in 2024/2025. The overarching goals of the challenge remain the same; however, some of the competition rules will be different. The big changes for this year's competition are as follows: First, we replace the loose track with a paper track, which allows (for example) non-model-based submissions, novel cognitively-inspired benchmarks, or analysis techniques. Second, we are relaxing the rules around pretraining data, and will now allow participants to construct their own datasets provided they stay within the 100M-word or 10M-word budget. Third, we introduce a multimodal vision-and-language track, and will release a corpus of 50% text-only and 50% image-text multimodal data as a starting point for LM model training. The purpose of this CfP is to provide rules for this year's challenge, explain these rule changes and their rationale in greater detail, give a timeline of this year's competition, and provide answers to frequently asked questions from last year's challenge.
Automatic Annotation of Grammaticality in Child-Caregiver Conversations
Mar 21, 2024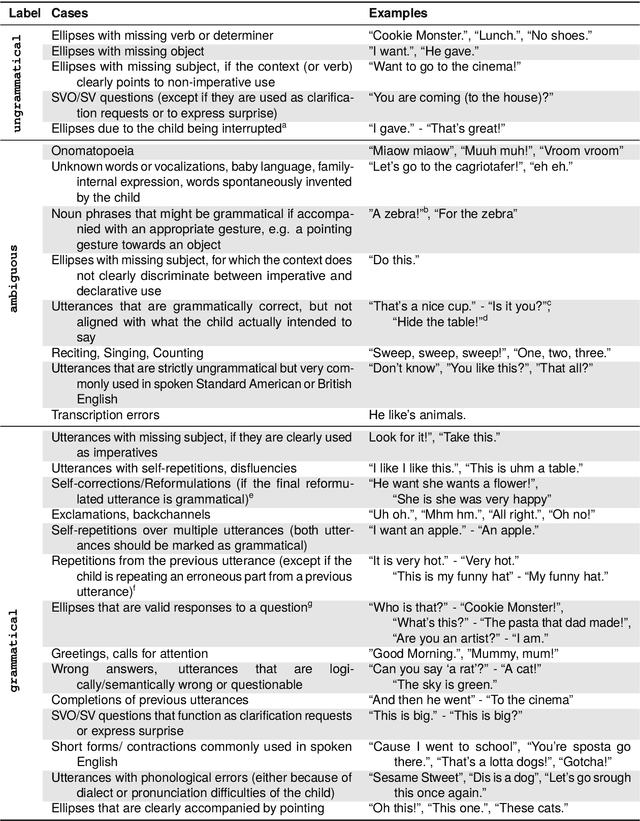
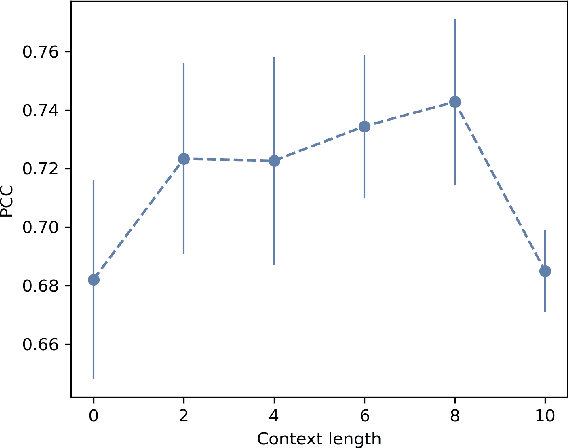
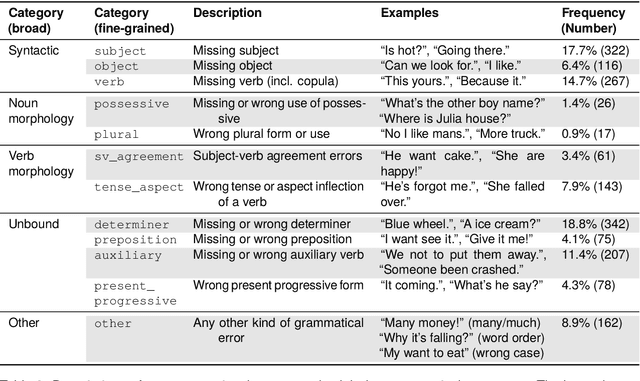
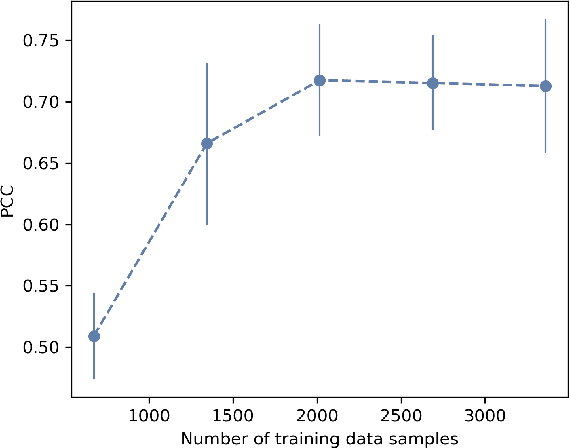
The acquisition of grammar has been a central question to adjudicate between theories of language acquisition. In order to conduct faster, more reproducible, and larger-scale corpus studies on grammaticality in child-caregiver conversations, tools for automatic annotation can offer an effective alternative to tedious manual annotation. We propose a coding scheme for context-dependent grammaticality in child-caregiver conversations and annotate more than 4,000 utterances from a large corpus of transcribed conversations. Based on these annotations, we train and evaluate a range of NLP models. Our results show that fine-tuned Transformer-based models perform best, achieving human inter-annotation agreement levels.As a first application and sanity check of this tool, we use the trained models to annotate a corpus almost two orders of magnitude larger than the manually annotated data and verify that children's grammaticality shows a steady increase with age.This work contributes to the growing literature on applying state-of-the-art NLP methods to help study child language acquisition at scale.
Acquiring Linguistic Knowledge from Multimodal Input
Feb 27, 2024In contrast to children, language models (LMs) exhibit considerably inferior data efficiency when acquiring language. In this submission to the BabyLM Challenge (Warstadt et al., 2023), we test the hypothesis that this data efficiency gap is partly caused by a lack of multimodal input and grounding in the learning environment of typical language models. Although previous work looking into this question found that multimodal training can even harm language-only performance, we speculate that these findings can be attributed to catastrophic forgetting of complex language due to fine-tuning on captions data. To test our hypothesis, we perform an ablation study on FLAVA (Singh et al., 2022), a multimodal vision-and-language model, independently varying the volume of text and vision input to quantify how much text data (if any) can be offset by vision at different data scales. We aim to limit catastrophic forgetting through a multitask pretraining regime that includes unimodal text-only tasks and data sampled from WiT, the relatively diverse Wikipedia-based dataset (Srinivasan et al., 2021). Our results are largely negative: Multimodal pretraining does not harm our models' language performance but does not consistently help either. That said, our conclusions are limited by our having been able to conduct only a small number of runs. While we must leave open the possibility that multimodal input explains some of the gap in data efficiency between LMs and humans, positive evidence for this hypothesis will require better architectures and techniques for multimodal training.
WhisBERT: Multimodal Text-Audio Language Modeling on 100M Words
Dec 07, 2023Training on multiple modalities of input can augment the capabilities of a language model. Here, we ask whether such a training regime can improve the quality and efficiency of these systems as well. We focus on text--audio and introduce Whisbert, which is inspired by the text--image approach of FLAVA (Singh et al., 2022). In accordance with Babylm guidelines (Warstadt et al., 2023), we pretrain Whisbert on a dataset comprising only 100 million words plus their corresponding speech from the word-aligned version of the People's Speech dataset (Galvez et al., 2021). To assess the impact of multimodality, we compare versions of the model that are trained on text only and on both audio and text simultaneously. We find that while Whisbert is able to perform well on multimodal masked modeling and surpasses the Babylm baselines in most benchmark tasks, it struggles to optimize its complex objective and outperform its text-only Whisbert baseline.
Quantifying the redundancy between prosody and text
Nov 28, 2023Prosody -- the suprasegmental component of speech, including pitch, loudness, and tempo -- carries critical aspects of meaning. However, the relationship between the information conveyed by prosody vs. by the words themselves remains poorly understood. We use large language models (LLMs) to estimate how much information is redundant between prosody and the words themselves. Using a large spoken corpus of English audiobooks, we extract prosodic features aligned to individual words and test how well they can be predicted from LLM embeddings, compared to non-contextual word embeddings. We find a high degree of redundancy between the information carried by the words and prosodic information across several prosodic features, including intensity, duration, pauses, and pitch contours. Furthermore, a word's prosodic information is redundant with both the word itself and the context preceding as well as following it. Still, we observe that prosodic features can not be fully predicted from text, suggesting that prosody carries information above and beyond the words. Along with this paper, we release a general-purpose data processing pipeline for quantifying the relationship between linguistic information and extra-linguistic features.
Call for Papers -- The BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus
Jan 27, 2023
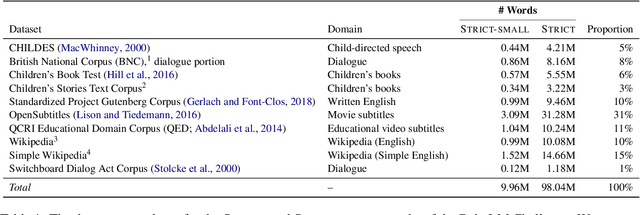
We present the call for papers for the BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus. This shared task is intended for participants with an interest in small scale language modeling, human language acquisition, low-resource NLP, and cognitive modeling. In partnership with CoNLL and CMCL, we provide a platform for approaches to pretraining with a limited-size corpus sourced from data inspired by the input to children. The task has three tracks, two of which restrict the training data to pre-released datasets of 10M and 100M words and are dedicated to explorations of approaches such as architectural variations, self-supervised objectives, or curriculum learning. The final track only restricts the amount of text used, allowing innovation in the choice of the data, its domain, and even its modality (i.e., data from sources other than text is welcome). We will release a shared evaluation pipeline which scores models on a variety of benchmarks and tasks, including targeted syntactic evaluations and natural language understanding.
Reconstruction Probing
Dec 21, 2022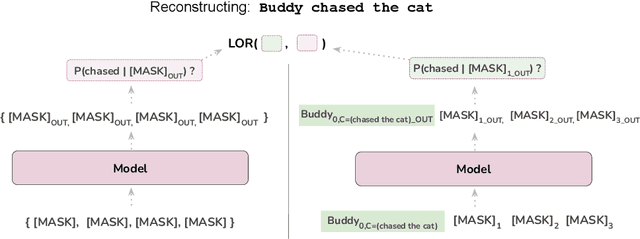

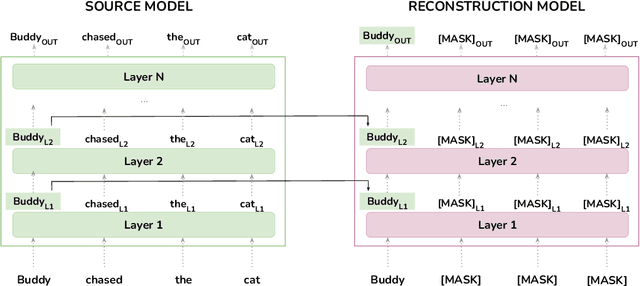

We propose reconstruction probing, a new analysis method for contextualized representations based on reconstruction probabilities in masked language models (MLMs). This method relies on comparing the reconstruction probabilities of tokens in a given sequence when conditioned on the representation of a single token that has been fully contextualized and when conditioned on only the decontextualized lexical prior of the model. This comparison can be understood as quantifying the contribution of contextualization towards reconstruction -- the difference in the reconstruction probabilities can only be attributed to the representational change of the single token induced by contextualization. We apply this analysis to three MLMs and find that contextualization boosts reconstructability of tokens that are close to the token being reconstructed in terms of linear and syntactic distance. Furthermore, we extend our analysis to finer-grained decomposition of contextualized representations, and we find that these boosts are largely attributable to static and positional embeddings at the input layer.
Entailment Semantics Can Be Extracted from an Ideal Language Model
Sep 26, 2022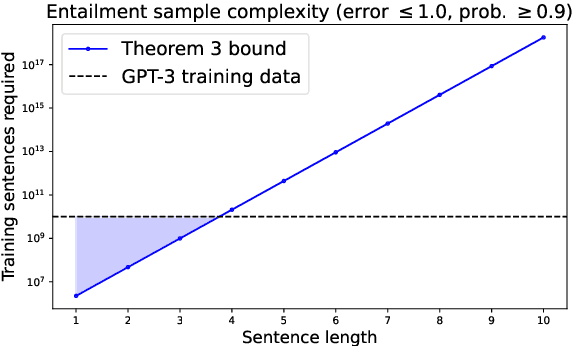
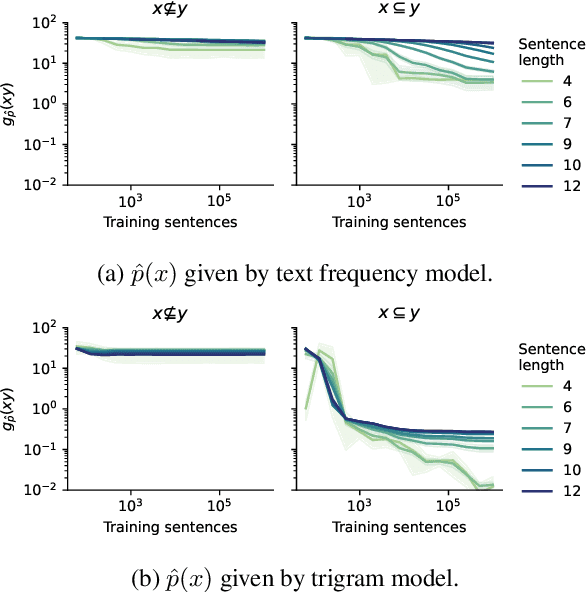

Language models are often trained on text alone, without additional grounding. There is debate as to how much of natural language semantics can be inferred from such a procedure. We prove that entailment judgments between sentences can be extracted from an ideal language model that has perfectly learned its target distribution, assuming the training sentences are generated by Gricean agents, i.e., agents who follow fundamental principles of communication from the linguistic theory of pragmatics. We also show entailment judgments can be decoded from the predictions of a language model trained on such Gricean data. Our results reveal a pathway for understanding the semantic information encoded in unlabeled linguistic data and a potential framework for extracting semantics from language models.
What Artificial Neural Networks Can Tell Us About Human Language Acquisition
Aug 17, 2022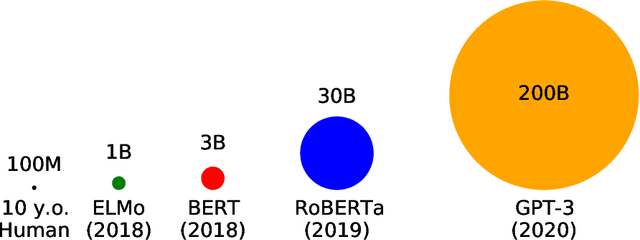
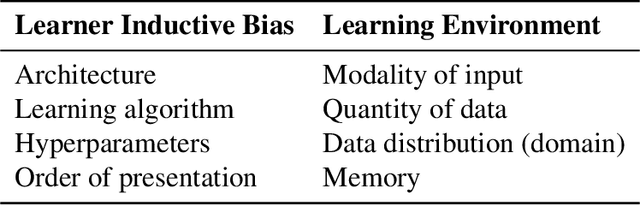

Rapid progress in machine learning for natural language processing has the potential to transform debates about how humans learn language. However, the learning environments and biases of current artificial learners and humans diverge in ways that weaken the impact of the evidence obtained from learning simulations. For example, today's most effective neural language models are trained on roughly one thousand times the amount of linguistic data available to a typical child. To increase the relevance of learnability results from computational models, we need to train model learners without significant advantages over humans. If an appropriate model successfully acquires some target linguistic knowledge, it can provide a proof of concept that the target is learnable in a hypothesized human learning scenario. Plausible model learners will enable us to carry out experimental manipulations to make causal inferences about variables in the learning environment, and to rigorously test poverty-of-the-stimulus-style claims arguing for innate linguistic knowledge in humans on the basis of speculations about learnability. Comparable experiments will never be possible with human subjects due to practical and ethical considerations, making model learners an indispensable resource. So far, attempts to deprive current models of unfair advantages obtain sub-human results for key grammatical behaviors such as acceptability judgments. But before we can justifiably conclude that language learning requires more prior domain-specific knowledge than current models possess, we must first explore non-linguistic inputs in the form of multimodal stimuli and multi-agent interaction as ways to make our learners more efficient at learning from limited linguistic input.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.