 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenghui Zhang
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Dec 03, 2023
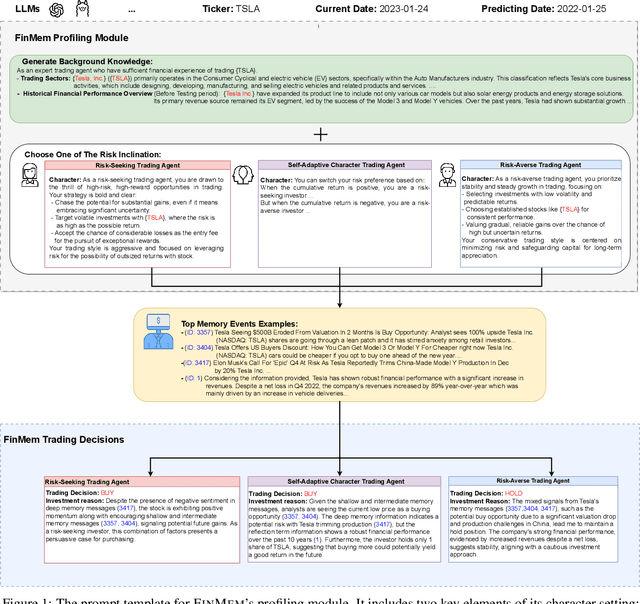
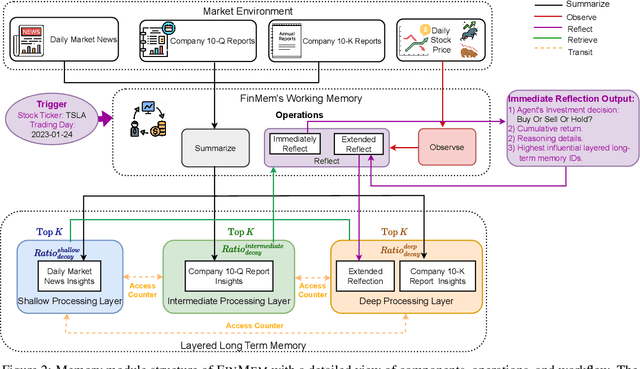
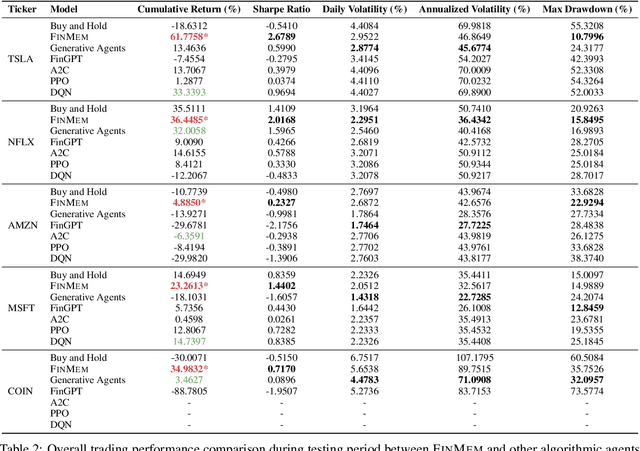

Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMem}, a novel LLM-based agent framework devised for financial decision-making. It encompasses three core modules: Profiling, to customize the agent's characteristics; Memory, with layered message processing, to aid the agent in assimilating hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMem}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMem} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks. We then fine-tuned the agent's perceptual span and character setting to achieve a significantly enhanced trading performance. Collectively, \textsc{FinMem} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
Boosting Urban Traffic Speed Prediction via Integrating Implicit Spatial Correlations
Dec 25, 2022
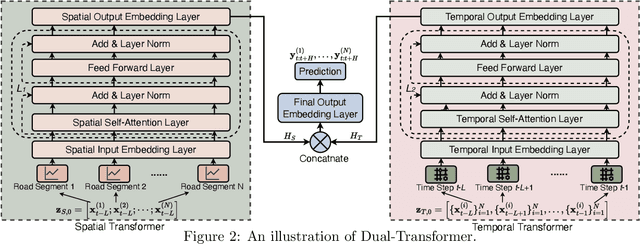

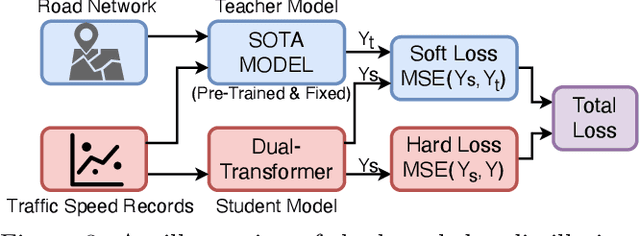
Urban traffic speed prediction aims to estimate the future traffic speed for improving the urban transportation services. Enormous efforts have been made on exploiting spatial correlations and temporal dependencies of traffic speed evolving patterns by leveraging explicit spatial relations (geographical proximity) through pre-defined geographical structures ({\it e.g.}, region grids or road networks). While achieving promising results, current traffic speed prediction methods still suffer from ignoring implicit spatial correlations (interactions), which cannot be captured by grid/graph convolutions. To tackle the challenge, we propose a generic model for enabling the current traffic speed prediction methods to preserve implicit spatial correlations. Specifically, we first develop a Dual-Transformer architecture, including a Spatial Transformer and a Temporal Transformer. The Spatial Transformer automatically learns the implicit spatial correlations across the road segments beyond the boundary of geographical structures, while the Temporal Transformer aims to capture the dynamic changing patterns of the implicit spatial correlations. Then, to further integrate both explicit and implicit spatial correlations, we propose a distillation-style learning framework, in which the existing traffic speed prediction methods are considered as the teacher model, and the proposed Dual-Transformer architectures are considered as the student model. The extensive experiments over three real-world datasets indicate significant improvements of our proposed framework over the existing methods.
Human-instructed Deep Hierarchical Generative Learning for Automated Urban Planning
Dec 01, 2022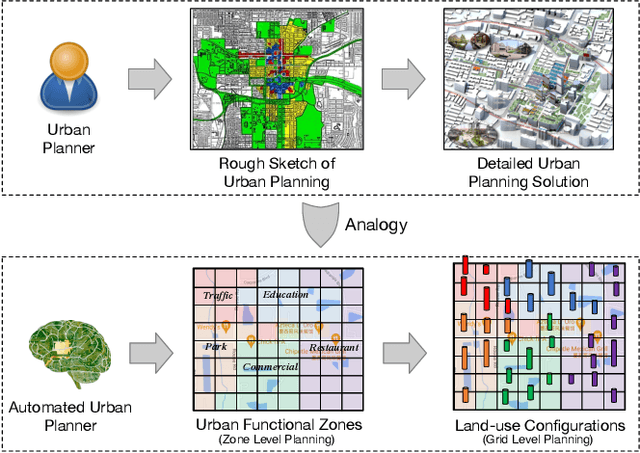
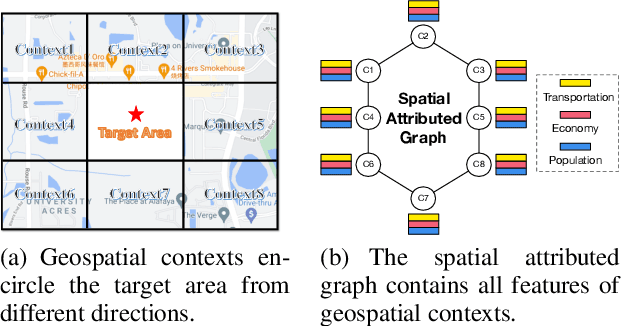
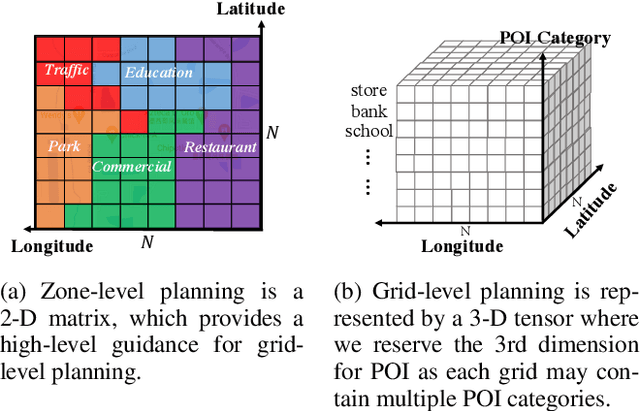
The essential task of urban planning is to generate the optimal land-use configuration of a target area. However, traditional urban planning is time-consuming and labor-intensive. Deep generative learning gives us hope that we can automate this planning process and come up with the ideal urban plans. While remarkable achievements have been obtained, they have exhibited limitations in lacking awareness of: 1) the hierarchical dependencies between functional zones and spatial grids; 2) the peer dependencies among functional zones; and 3) human regulations to ensure the usability of generated configurations. To address these limitations, we develop a novel human-instructed deep hierarchical generative model. We rethink the urban planning generative task from a unique functionality perspective, where we summarize planning requirements into different functionality projections for better urban plan generation. To this end, we develop a three-stage generation process from a target area to zones to grids. The first stage is to label the grids of a target area with latent functionalities to discover functional zones. The second stage is to perceive the planning requirements to form urban functionality projections. We propose a novel module: functionalizer to project the embedding of human instructions and geospatial contexts to the zone-level plan to obtain such projections. Each projection includes the information of land-use portfolios and the structural dependencies across spatial grids in terms of a specific urban function. The third stage is to leverage multi-attentions to model the zone-zone peer dependencies of the functionality projections to generate grid-level land-use configurations. Finally, we present extensive experiments to demonstrate the effectiveness of our framework.
Graph Soft-Contrastive Learning via Neighborhood Ranking
Sep 28, 2022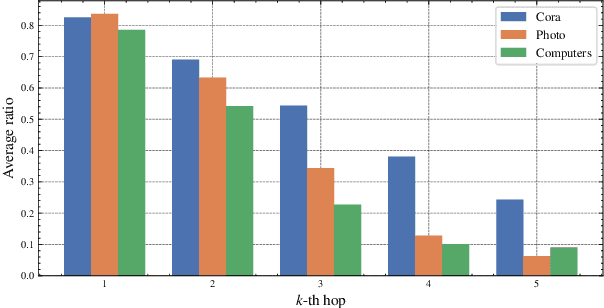
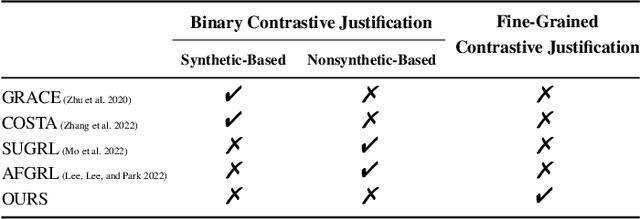

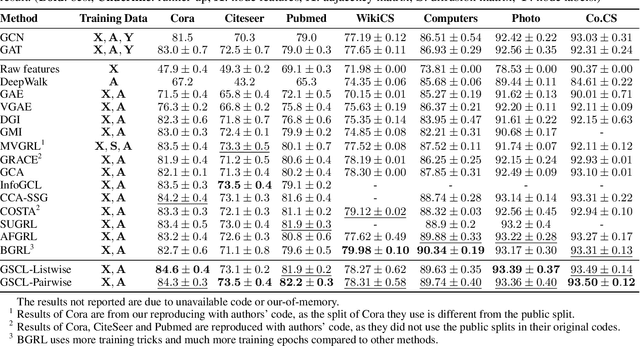
Graph contrastive learning (GCL) has been an emerging solution for graph self-supervised learning. The core principle of GCL is to reduce the distance between samples in the positive view, but increase the distance between samples in the negative view. While achieving promising performances, current GCL methods still suffer from two limitations: (1) uncontrollable validity of augmentation, that graph perturbation may produce invalid views against semantics and feature-topology correspondence of graph data; and (2) unreliable binary contrastive justification, that the positiveness and negativeness of the constructed views are difficult to be determined for non-euclidean graph data. To tackle the above limitations, we propose a new contrastive learning paradigm for graphs, namely Graph Soft-Contrastive Learning (GSCL), that conducts contrastive learning in a finer-granularity via ranking neighborhoods without any augmentations and binary contrastive justification. GSCL is built upon the fundamental assumption of graph proximity that connected neighbors are more similar than far-distant nodes. Specifically, we develop pair-wise and list-wise Gated Ranking infoNCE Loss functions to preserve the relative ranking relationship in the neighborhood. Moreover, as the neighborhood size exponentially expands with more hops considered, we propose neighborhood sampling strategies to improve learning efficiency. The extensive experimental results show that our proposed GSCL can consistently achieve state-of-the-art performances on various public datasets with comparable practical complexity to GCL.
Adversarial Attacks on ASR Systems: An Overview
Aug 03, 2022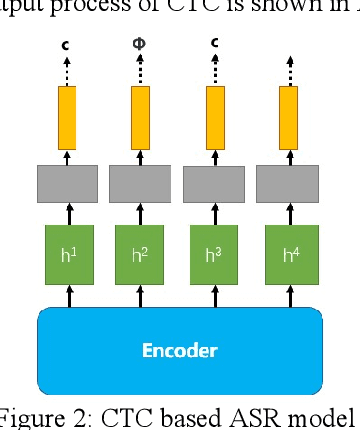
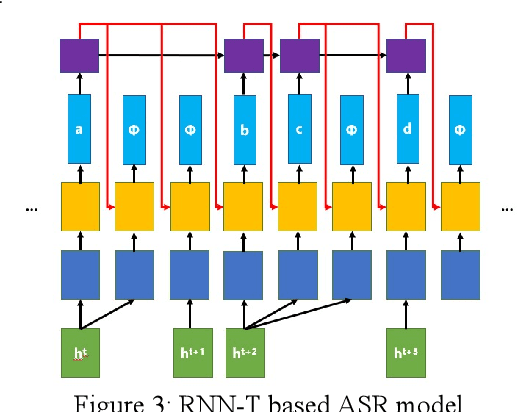
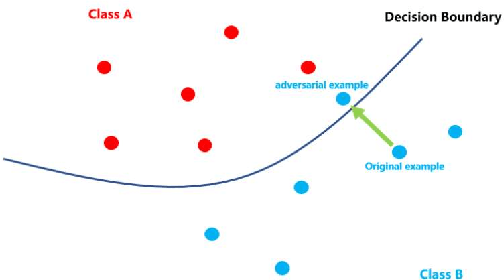
With the development of hardware and algorithms, ASR(Automatic Speech Recognition) systems evolve a lot. As The models get simpler, the difficulty of development and deployment become easier, ASR systems are getting closer to our life. On the one hand, we often use APPs or APIs of ASR to generate subtitles and record meetings. On the other hand, smart speaker and self-driving car rely on ASR systems to control AIoT devices. In past few years, there are a lot of works on adversarial examples attacks against ASR systems. By adding a small perturbation to the waveforms, the recognition results make a big difference. In this paper, we describe the development of ASR system, different assumptions of attacks, and how to evaluate these attacks. Next, we introduce the current works on adversarial examples attacks from two attack assumptions: white-box attack and black-box attack. Different from other surveys, we pay more attention to which layer they perturb waveforms in ASR system, the relationship between these attacks, and their implementation methods. We focus on the effect of their works.
Learning to Walk with Dual Agents for Knowledge Graph Reasoning
Dec 23, 2021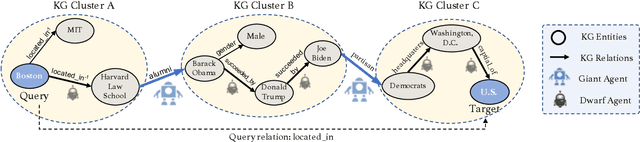
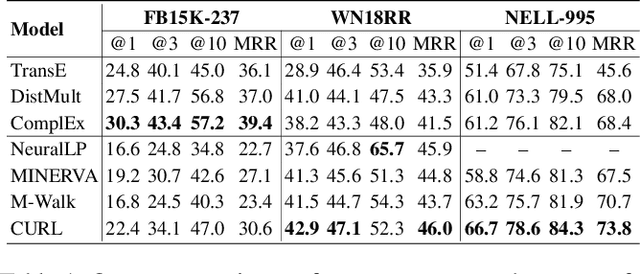
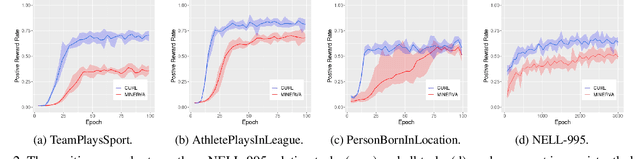
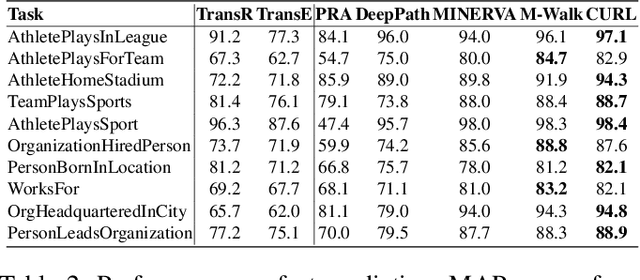
Graph walking based on reinforcement learning (RL) has shown great success in navigating an agent to automatically complete various reasoning tasks over an incomplete knowledge graph (KG) by exploring multi-hop relational paths. However, existing multi-hop reasoning approaches only work well on short reasoning paths and tend to miss the target entity with the increasing path length. This is undesirable for many reason-ing tasks in real-world scenarios, where short paths connecting the source and target entities are not available in incomplete KGs, and thus the reasoning performances drop drastically unless the agent is able to seek out more clues from longer paths. To address the above challenge, in this paper, we propose a dual-agent reinforcement learning framework, which trains two agents (GIANT and DWARF) to walk over a KG jointly and search for the answer collaboratively. Our approach tackles the reasoning challenge in long paths by assigning one of the agents (GIANT) searching on cluster-level paths quickly and providing stage-wise hints for another agent (DWARF). Finally, experimental results on several KG reasoning benchmarks show that our approach can search answers more accurately and efficiently, and outperforms existing RL-based methods for long path queries by a large margin.
Domain-oriented Language Pre-training with Adaptive Hybrid Masking and Optimal Transport Alignment
Dec 01, 2021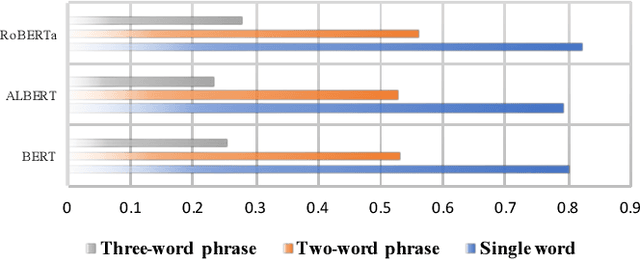


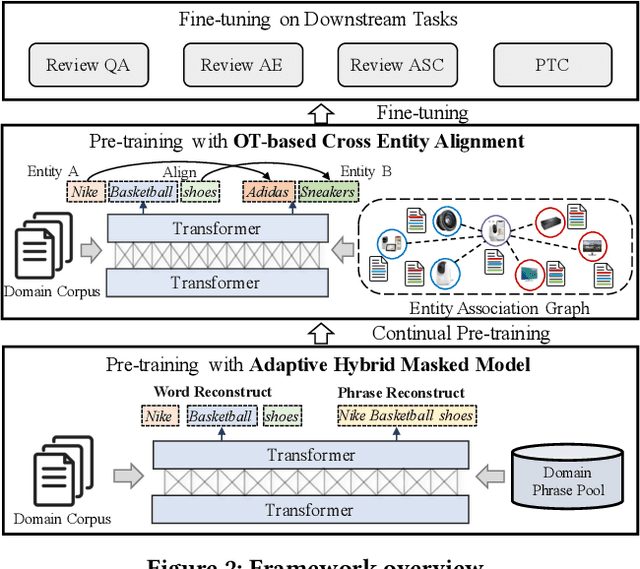
Motivated by the success of pre-trained language models such as BERT in a broad range of natural language processing (NLP) tasks, recent research efforts have been made for adapting these models for different application domains. Along this line, existing domain-oriented models have primarily followed the vanilla BERT architecture and have a straightforward use of the domain corpus. However, domain-oriented tasks usually require accurate understanding of domain phrases, and such fine-grained phrase-level knowledge is hard to be captured by existing pre-training scheme. Also, the word co-occurrences guided semantic learning of pre-training models can be largely augmented by entity-level association knowledge. But meanwhile, by doing so there is a risk of introducing noise due to the lack of groundtruth word-level alignment. To address the above issues, we provide a generalized domain-oriented approach, which leverages auxiliary domain knowledge to improve the existing pre-training framework from two aspects. First, to preserve phrase knowledge effectively, we build a domain phrase pool as auxiliary training tool, meanwhile we introduce Adaptive Hybrid Masked Model to incorporate such knowledge. It integrates two learning modes, word learning and phrase learning, and allows them to switch between each other. Second, we introduce Cross Entity Alignment to leverage entity association as weak supervision to augment the semantic learning of pre-trained models. To alleviate the potential noise in this process, we introduce an interpretable Optimal Transport based approach to guide alignment learning. Experiments on four domain-oriented tasks demonstrate the superiority of our framework.
Learning Disentangled Representations for Time Series
May 21, 2021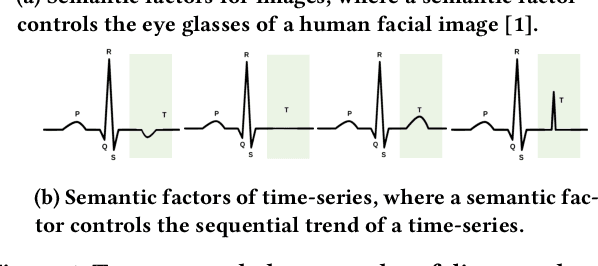
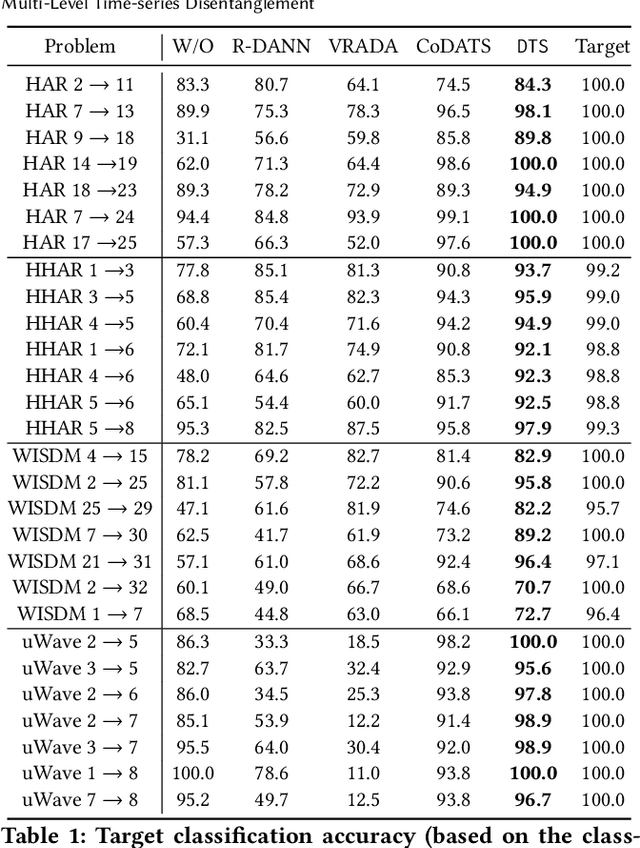
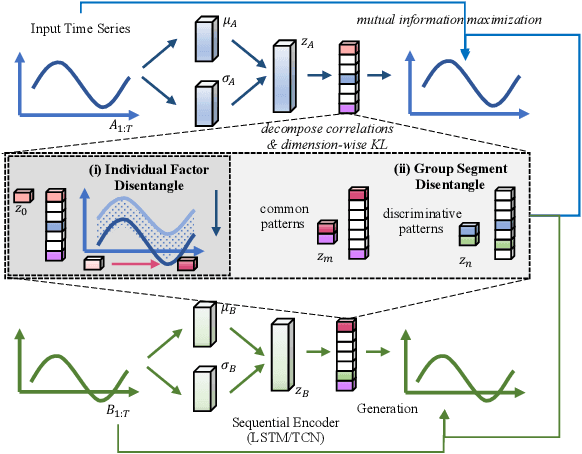
Time-series representation learning is a fundamental task for time-series analysis. While significant progress has been made to achieve accurate representations for downstream applications, the learned representations often lack interpretability and do not expose semantic meanings. Different from previous efforts on the entangled feature space, we aim to extract the semantic-rich temporal correlations in the latent interpretable factorized representation of the data. Motivated by the success of disentangled representation learning in computer vision, we study the possibility of learning semantic-rich time-series representations, which remains unexplored due to three main challenges: 1) sequential data structure introduces complex temporal correlations and makes the latent representations hard to interpret, 2) sequential models suffer from KL vanishing problem, and 3) interpretable semantic concepts for time-series often rely on multiple factors instead of individuals. To bridge the gap, we propose Disentangle Time Series (DTS), a novel disentanglement enhancement framework for sequential data. Specifically, to generate hierarchical semantic concepts as the interpretable and disentangled representation of time-series, DTS introduces multi-level disentanglement strategies by covering both individual latent factors and group semantic segments. We further theoretically show how to alleviate the KL vanishing problem: DTS introduces a mutual information maximization term, while preserving a heavier penalty on the total correlation and the dimension-wise KL to keep the disentanglement property. Experimental results on various real-world benchmark datasets demonstrate that the representations learned by DTS achieve superior performance in downstream applications, with high interpretability of semantic concepts.
T$^2$-Net: A Semi-supervised Deep Model for Turbulence Forecasting
Oct 26, 2020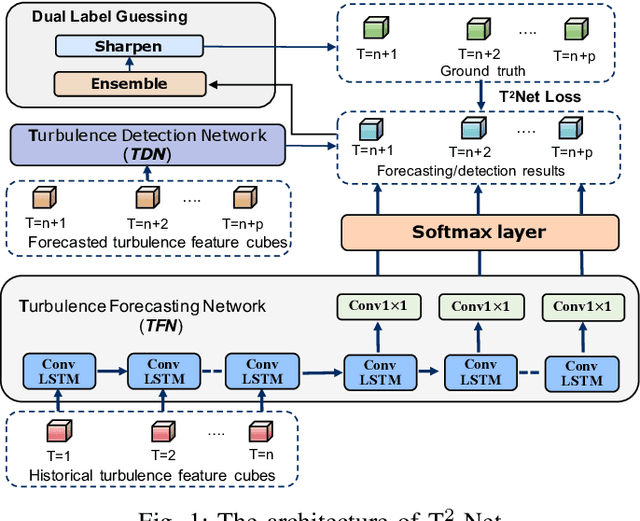
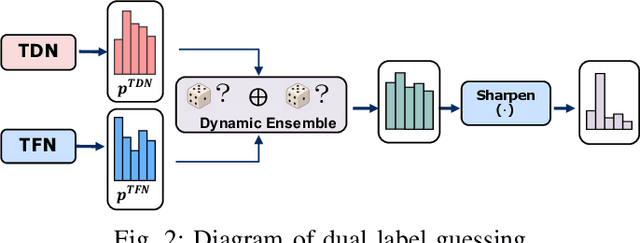

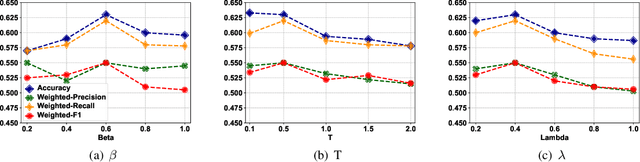
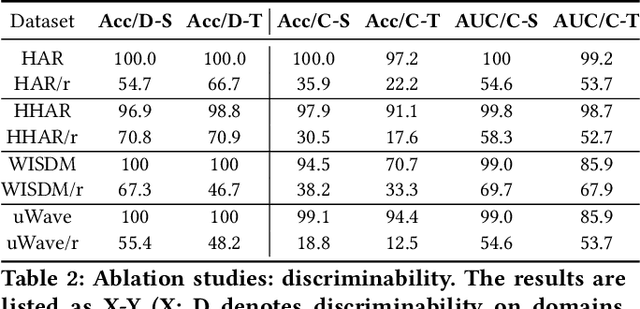
Accurate air turbulence forecasting can help airlines avoid hazardous turbulence, guide the routes that keep passengers safe, maximize efficiency, and reduce costs. Traditional turbulence forecasting approaches heavily rely on painstakingly customized turbulence indexes, which are less effective in dynamic and complex weather conditions. The recent availability of high-resolution weather data and turbulence records allows more accurate forecasting of the turbulence in a data-driven way. However, it is a non-trivial task for developing a machine learning based turbulence forecasting system due to two challenges: (1) Complex spatio-temporal correlations, turbulence is caused by air movement with complex spatio-temporal patterns, (2) Label scarcity, very limited turbulence labels can be obtained. To this end, in this paper, we develop a unified semi-supervised framework, T$^2$-Net, to address the above challenges. Specifically, we first build an encoder-decoder paradigm based on the convolutional LSTM to model the spatio-temporal correlations. Then, to tackle the label scarcity problem, we propose a novel Dual Label Guessing method to take advantage of massive unlabeled turbulence data. It integrates complementary signals from the main Turbulence Forecasting task and the auxiliary Turbulence Detection task to generate pseudo-labels, which are dynamically utilized as additional training data. Finally, extensive experimental results on a real-world turbulence dataset validate the superiority of our method on turbulence forecasting.
Job2Vec: Job Title Benchmarking with Collective Multi-View Representation Learning
Sep 16, 2020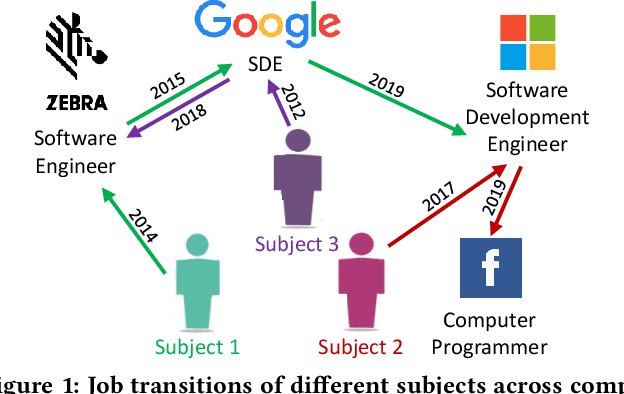

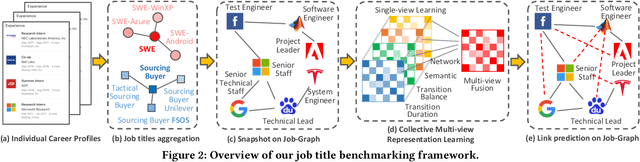
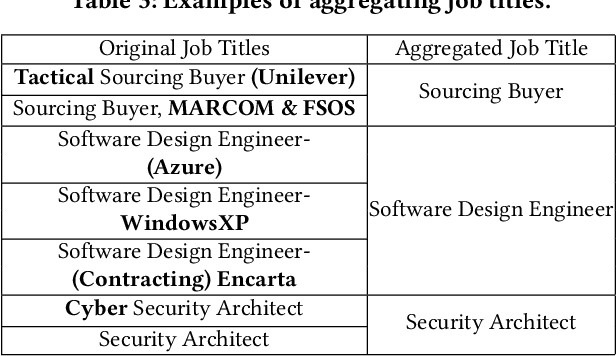
Job Title Benchmarking (JTB) aims at matching job titles with similar expertise levels across various companies. JTB could provide precise guidance and considerable convenience for both talent recruitment and job seekers for position and salary calibration/prediction. Traditional JTB approaches mainly rely on manual market surveys, which is expensive and labor-intensive. Recently, the rapid development of Online Professional Graph has accumulated a large number of talent career records, which provides a promising trend for data-driven solutions. However, it is still a challenging task since (1) the job title and job transition (job-hopping) data is messy which contains a lot of subjective and non-standard naming conventions for the same position (e.g., Programmer, Software Development Engineer, SDE, Implementation Engineer), (2) there is a large amount of missing title/transition information, and (3) one talent only seeks limited numbers of jobs which brings the incompleteness and randomness modeling job transition patterns. To overcome these challenges, we aggregate all the records to construct a large-scale Job Title Benchmarking Graph (Job-Graph), where nodes denote job titles affiliated with specific companies and links denote the correlations between jobs. We reformulate the JTB as the task of link prediction over the Job-Graph that matched job titles should have links. Along this line, we propose a collective multi-view representation learning method (Job2Vec) by examining the Job-Graph jointly in (1) graph topology view, (2)semantic view, (3) job transition balance view, and (4) job transition duration view. We fuse the multi-view representations in the encode-decode paradigm to obtain a unified optimal representation for the task of link prediction. Finally, we conduct extensive experiments to validate the effectiveness of our proposed method.