 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuoping Wang
Learning the Geodesic Embedding with Graph Neural Networks
Sep 11, 2023
We present GeGnn, a learning-based method for computing the approximate geodesic distance between two arbitrary points on discrete polyhedra surfaces with constant time complexity after fast precomputation. Previous relevant methods either focus on computing the geodesic distance between a single source and all destinations, which has linear complexity at least or require a long precomputation time. Our key idea is to train a graph neural network to embed an input mesh into a high-dimensional embedding space and compute the geodesic distance between a pair of points using the corresponding embedding vectors and a lightweight decoding function. To facilitate the learning of the embedding, we propose novel graph convolution and graph pooling modules that incorporate local geodesic information and are verified to be much more effective than previous designs. After training, our method requires only one forward pass of the network per mesh as precomputation. Then, we can compute the geodesic distance between a pair of points using our decoding function, which requires only several matrix multiplications and can be massively parallelized on GPUs. We verify the efficiency and effectiveness of our method on ShapeNet and demonstrate that our method is faster than existing methods by orders of magnitude while achieving comparable or better accuracy. Additionally, our method exhibits robustness on noisy and incomplete meshes and strong generalization ability on out-of-distribution meshes. The code and pretrained model can be found on https://github.com/IntelligentGeometry/GeGnn.
6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-based Instance Representation Learning
Oct 30, 2021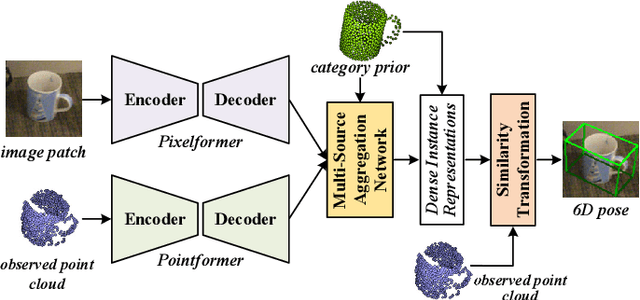



This paper presents 6D-ViT, a transformer-based instance representation learning network, which is suitable for highly accurate category-level object pose estimation on RGB-D images. Specifically, a novel two-stream encoder-decoder framework is dedicated to exploring complex and powerful instance representations from RGB images, point clouds and categorical shape priors. For this purpose, the whole framework consists of two main branches, named Pixelformer and Pointformer. The Pixelformer contains a pyramid transformer encoder with an all-MLP decoder to extract pixelwise appearance representations from RGB images, while the Pointformer relies on a cascaded transformer encoder and an all-MLP decoder to acquire the pointwise geometric characteristics from point clouds. Then, dense instance representations (i.e., correspondence matrix, deformation field) are obtained from a multi-source aggregation network with shape priors, appearance and geometric information as input. Finally, the instance 6D pose is computed by leveraging the correspondence among dense representations, shape priors, and the instance point clouds. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed 3D instance representation learning framework achieves state-of-the-art performance on both datasets, and significantly outperforms all existing methods.
DeepEigen: Learning-based Modal Sound Synthesis with Acoustic Transfer Maps
Aug 17, 2021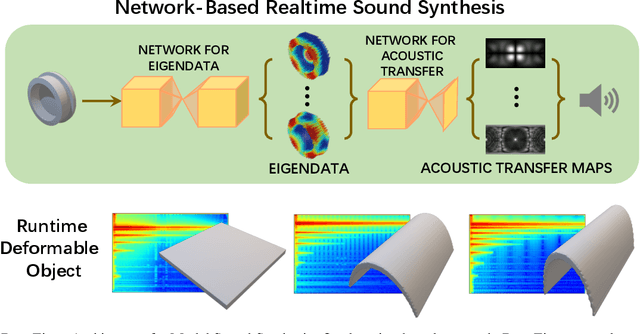
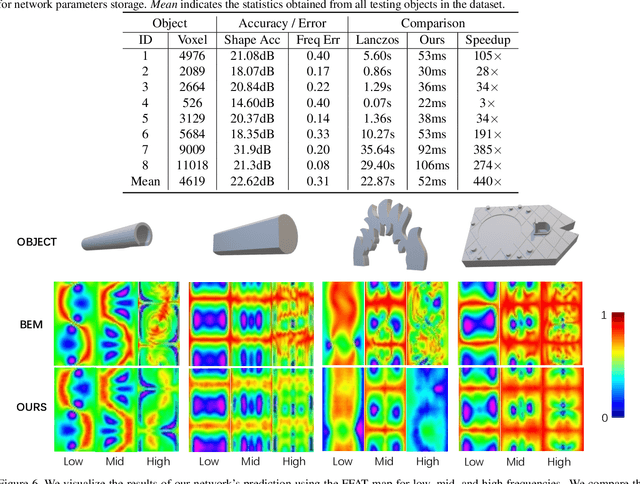
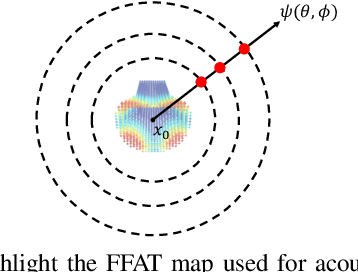
We present a novel learning-based approach to compute the eigenmodes and acoustic transfer data for the sound synthesis of arbitrary solid objects. Our approach combines two network-based solutions to formulate a complete learning-based 3D modal sound model. This includes a 3D sparse convolution network as the eigendecomposition solver and an encoder-decoder network for the prediction of the Far-Field Acoustic Transfer maps (FFAT Maps). We use our approach to compute the vibration modes (eigenmodes) and FFAT maps for each mode (acoustic data) for arbitrary-shaped objects at interactive rates without any precomputed dataset for any new object. Our experimental results demonstrate the effectiveness and benefits of our approach. We compare its accuracy and efficiency with physically-based sound synthesis methods.
AA-RMVSNet: Adaptive Aggregation Recurrent Multi-view Stereo Network
Aug 09, 2021
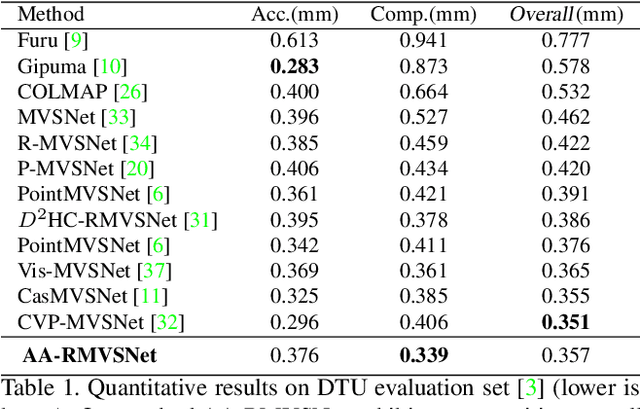
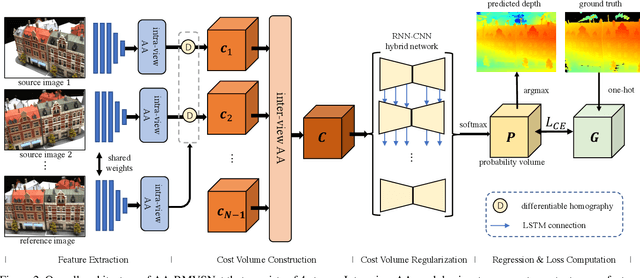
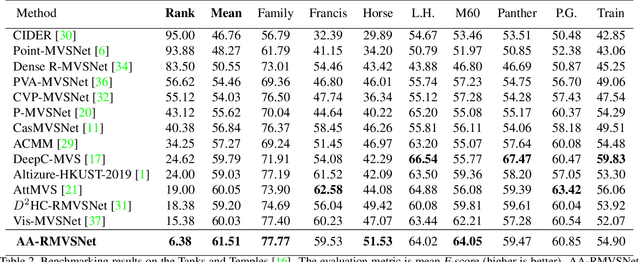
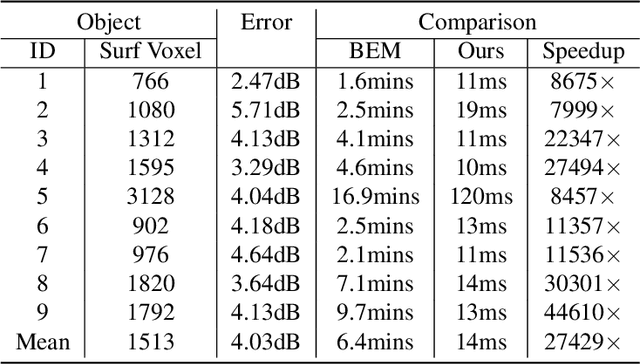
In this paper, we present a novel recurrent multi-view stereo network based on long short-term memory (LSTM) with adaptive aggregation, namely AA-RMVSNet. We firstly introduce an intra-view aggregation module to adaptively extract image features by using context-aware convolution and multi-scale aggregation, which efficiently improves the performance on challenging regions, such as thin objects and large low-textured surfaces. To overcome the difficulty of varying occlusion in complex scenes, we propose an inter-view cost volume aggregation module for adaptive pixel-wise view aggregation, which is able to preserve better-matched pairs among all views. The two proposed adaptive aggregation modules are lightweight, effective and complementary regarding improving the accuracy and completeness of 3D reconstruction. Instead of conventional 3D CNNs, we utilize a hybrid network with recurrent structure for cost volume regularization, which allows high-resolution reconstruction and finer hypothetical plane sweep. The proposed network is trained end-to-end and achieves excellent performance on various datasets. It ranks $1^{st}$ among all submissions on Tanks and Temples benchmark and achieves competitive results on DTU dataset, which exhibits strong generalizability and robustness. Implementation of our method is available at https://github.com/QT-Zhu/AA-RMVSNet.
Dense Hybrid Recurrent Multi-view Stereo Net with Dynamic Consistency Checking
Jul 21, 2020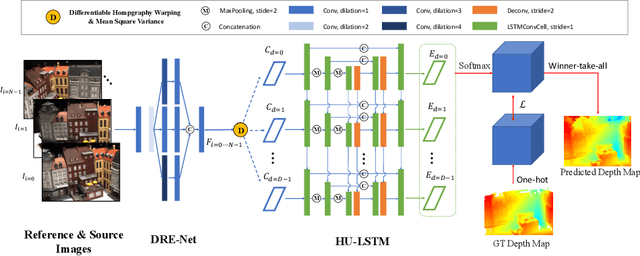
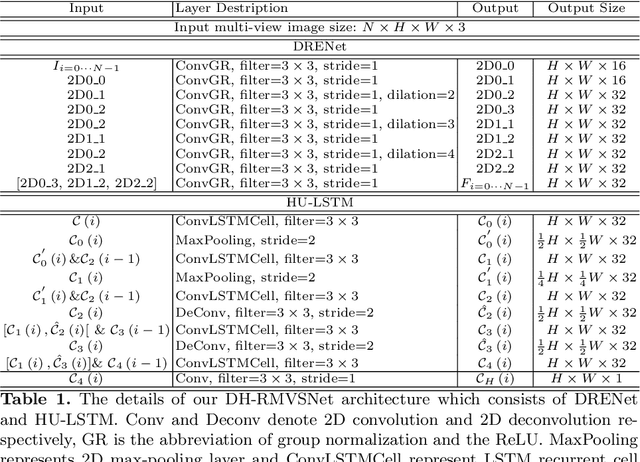
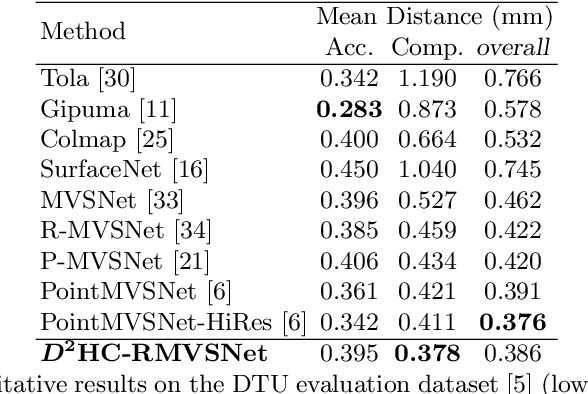

In this paper, we propose an efficient and effective dense hybrid recurrent multi-view stereo net with dynamic consistency checking, namely $D^{2}$HC-RMVSNet, for accurate dense point cloud reconstruction. Our novel hybrid recurrent multi-view stereo net consists of two core modules: 1) a light DRENet (Dense Reception Expanded) module to extract dense feature maps of original size with multi-scale context information, 2) a HU-LSTM (Hybrid U-LSTM) to regularize 3D matching volume into predicted depth map, which efficiently aggregates different scale information by coupling LSTM and U-Net architecture. To further improve the accuracy and completeness of reconstructed point clouds, we leverage a dynamic consistency checking strategy instead of prefixed parameters and strategies widely adopted in existing methods for dense point cloud reconstruction. In doing so, we dynamically aggregate geometric consistency matching error among all the views. Our method ranks \textbf{$1^{st}$} on the complex outdoor \textsl{Tanks and Temples} benchmark over all the methods. Extensive experiments on the in-door DTU dataset show our method exhibits competitive performance to the state-of-the-art method while dramatically reduces memory consumption, which costs only $19.4\%$ of R-MVSNet memory consumption. The codebase is available at \hyperlink{https://github.com/yhw-yhw/D2HC-RMVSNet}{https://github.com/yhw-yhw/D2HC-RMVSNet}.
* Accepted by ECCV2020 as Spotlight
SegVoxelNet: Exploring Semantic Context and Depth-aware Features for 3D Vehicle Detection from Point Cloud
Feb 13, 2020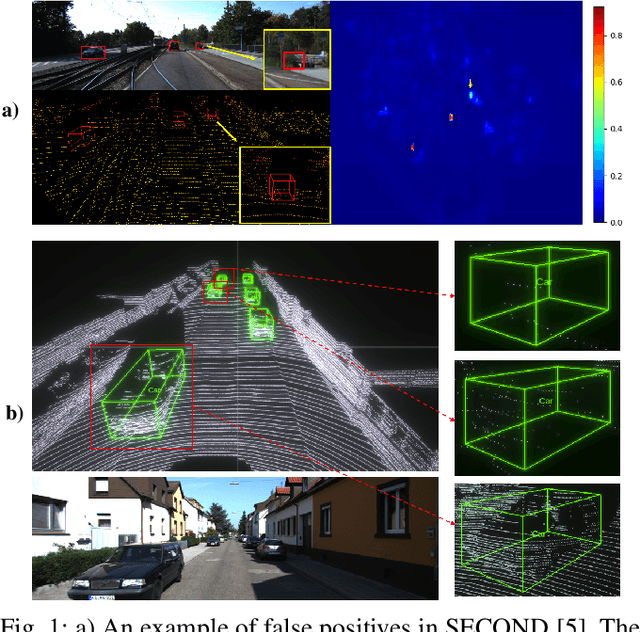
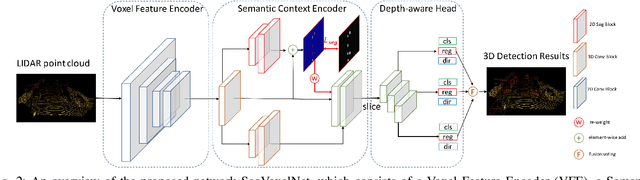


3D vehicle detection based on point cloud is a challenging task in real-world applications such as autonomous driving. Despite significant progress has been made, we observe two aspects to be further improved. First, the semantic context information in LiDAR is seldom explored in previous works, which may help identify ambiguous vehicles. Second, the distribution of point cloud on vehicles varies continuously with increasing depths, which may not be well modeled by a single model. In this work, we propose a unified model SegVoxelNet to address the above two problems. A semantic context encoder is proposed to leverage the free-of-charge semantic segmentation masks in the bird's eye view. Suspicious regions could be highlighted while noisy regions are suppressed by this module. To better deal with vehicles at different depths, a novel depth-aware head is designed to explicitly model the distribution differences and each part of the depth-aware head is made to focus on its own target detection range. Extensive experiments on the KITTI dataset show that the proposed method outperforms the state-of-the-art alternatives in both accuracy and efficiency with point cloud as input only.
Graph-Based Parallel Large Scale Structure from Motion
Dec 23, 2019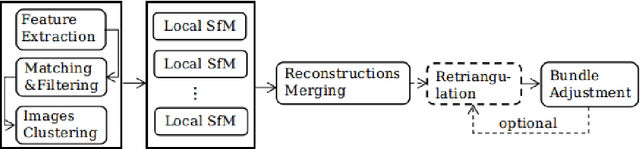
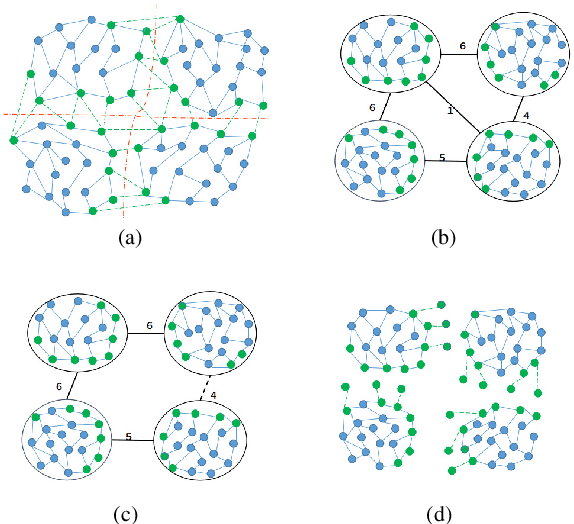
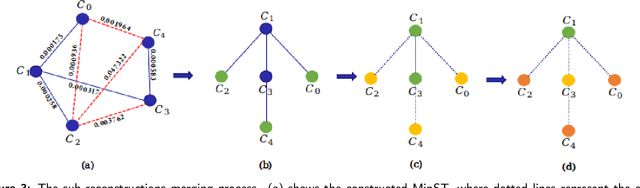

While Structure from Motion (SfM) achieves great success in 3D reconstruction, it still meets challenges on large scale scenes. In this work, large scale SfM is deemed as a graph problem, and we tackle it in a divide-and-conquer manner. Firstly, the images clustering algorithm divides images into clusters with strong connectivity, leading to robust local reconstructions. Then followed with an image expansion step, the connection and completeness of scenes are enhanced by expanding along with a maximum spanning tree. After local reconstructions, we construct a minimum spanning tree (MinST) to find accurate similarity transformations. Then the MinST is transformed into a Minimum Height Tree (MHT) to find a proper anchor node and is further utilized to prevent error accumulation. When evaluated on different kinds of datasets, our approach shows superiority over the state-of-the-art in accuracy and efficiency. Our algorithm is open-sourced at https://github.com/AIBluefisher/GraphSfM.
Bundle Adjustment Revisited
Dec 09, 2019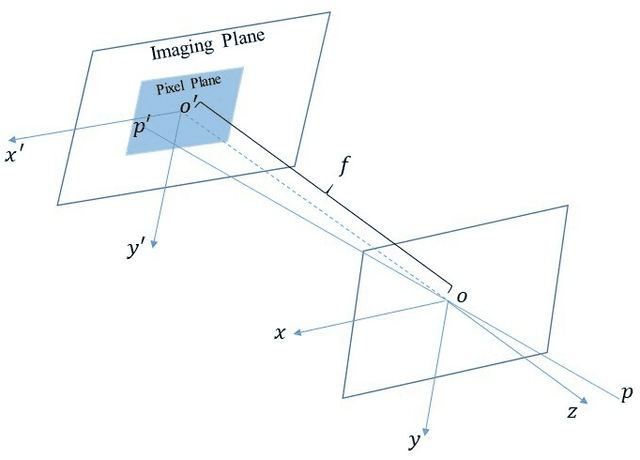
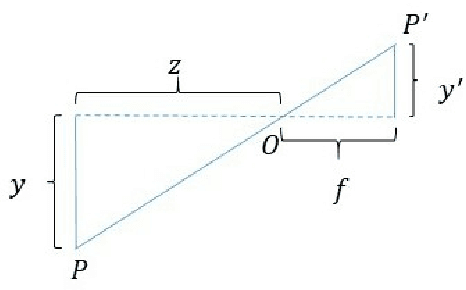

3D reconstruction has been developing all these two decades, from moderate to medium size and to large scale. It's well known that bundle adjustment plays an important role in 3D reconstruction, mainly in Structure from Motion(SfM) and Simultaneously Localization and Mapping(SLAM). While bundle adjustment optimizes camera parameters and 3D points as a non-negligible final step, it suffers from memory and efficiency requirements in very large scale reconstruction. In this paper, we study the development of bundle adjustment elaborately in both conventional and distributed approaches. The detailed derivation and pseudo code are also given in this paper.
Pyramid Multi-view Stereo Net with Self-adaptive View Aggregation
Dec 06, 2019
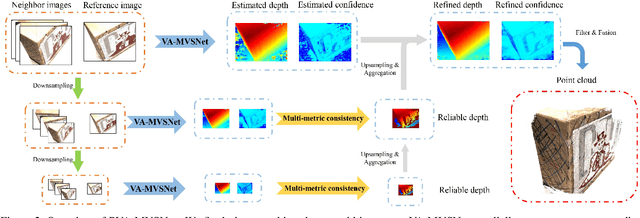

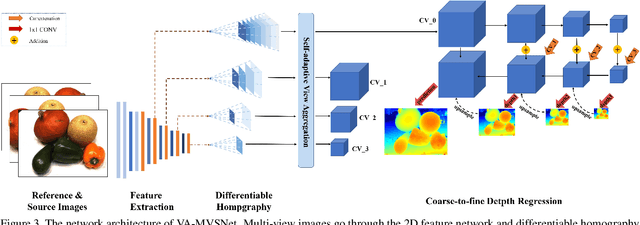
In this paper, we propose an effective and efficient pyramid multi-view stereo (MVS) net for accurate and complete dense point cloud reconstruction. Different from existing deep-learning based MVS methods, our VA-MVSNet incorporates the cost variance between different views by introducing two novel self-adaptive view aggregation: pixel-wise view aggregation and voxel-wise view aggregation. Moreover, to enhance the point cloud reconstruction on the texture-less regions, we extend VA-MVSNet with pyramid multi-scale images input as PVA-MVSNet, where multi-metric constraints are leveraged to aggregate the reliable depth estimation at the coarser scale to fill-in the mismatched regions at the finer scale. Experimental results show that our approach establishes a new state-of-the-art on the DTU dataset with significant improvements in the completeness and overall quality of 3D reconstruction, and ranks 1st on the Tanks and Temples benchmark among all published deep-learning based methods. Our codebase is available at https://github.com/yhw-yhw/PVAMVSNet.
AADS: Augmented Autonomous Driving Simulation using Data-driven Algorithms
Jan 23, 2019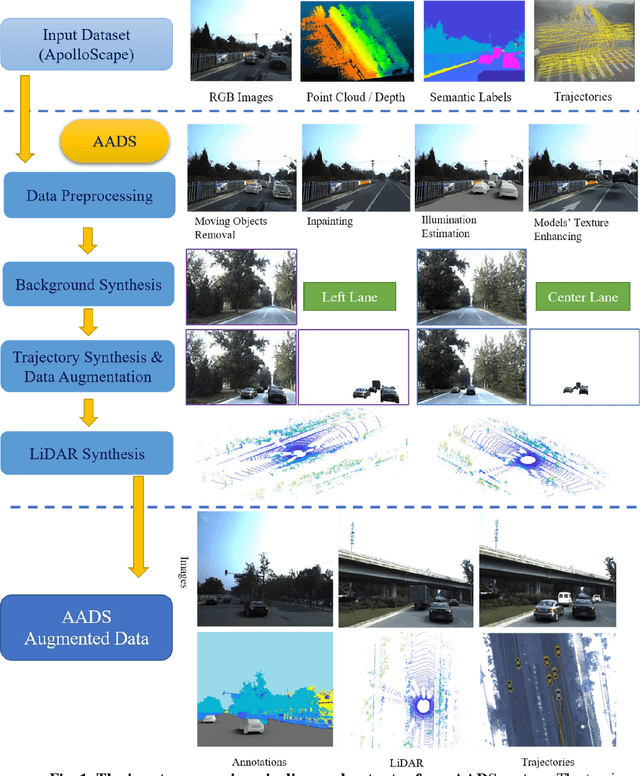
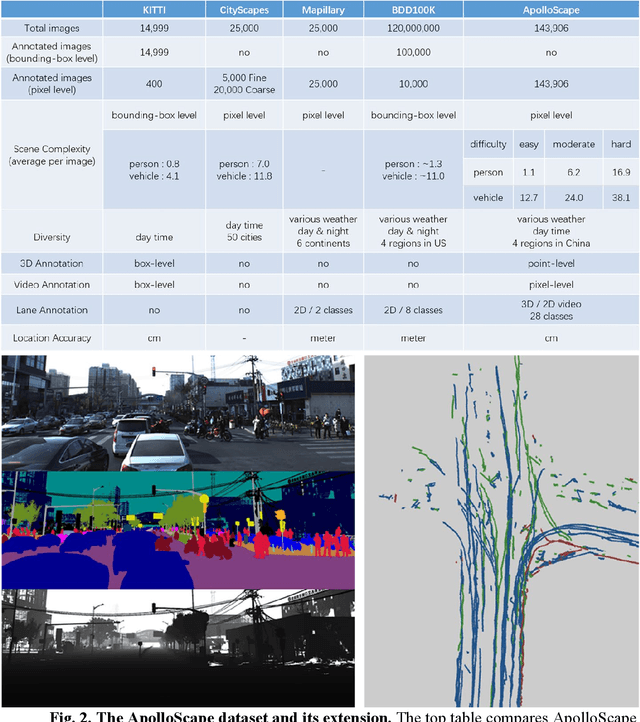

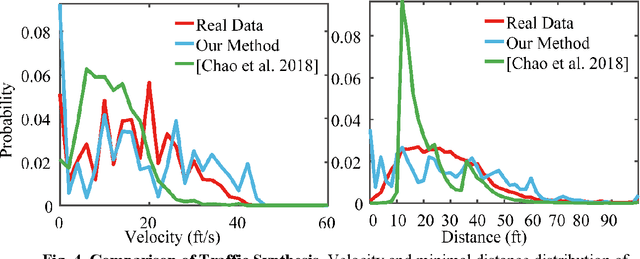
Simulation systems have become an essential component in the development and validation of autonomous driving technologies. The prevailing state-of-the-art approach for simulation is to use game engines or high-fidelity computer graphics (CG) models to create driving scenarios. However, creating CG models and vehicle movements (e.g., the assets for simulation) remains a manual task that can be costly and time-consuming. In addition, the fidelity of CG images still lacks the richness and authenticity of real-world images and using these images for training leads to degraded performance. In this paper we present a novel approach to address these issues: Augmented Autonomous Driving Simulation (AADS). Our formulation augments real-world pictures with a simulated traffic flow to create photo-realistic simulation images and renderings. More specifically, we use LiDAR and cameras to scan street scenes. From the acquired trajectory data, we generate highly plausible traffic flows for cars and pedestrians and compose them into the background. The composite images can be re-synthesized with different viewpoints and sensor models. The resulting images are photo-realistic, fully annotated, and ready for end-to-end training and testing of autonomous driving systems from perception to planning. We explain our system design and validate our algorithms with a number of autonomous driving tasks from detection to segmentation and predictions. Compared to traditional approaches, our method offers unmatched scalability and realism. Scalability is particularly important for AD simulation and we believe the complexity and diversity of the real world cannot be realistically captured in a virtual environment. Our augmented approach combines the flexibility in a virtual environment (e.g., vehicle movements) with the richness of the real world to allow effective simulation of anywhere on earth.