 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolger H. Hoos
Competitions in AI -- Robustly Ranking Solvers Using Statistical Resampling
Aug 09, 2023




Solver competitions play a prominent role in assessing and advancing the state of the art for solving many problems in AI and beyond. Notably, in many areas of AI, competitions have had substantial impact in guiding research and applications for many years, and for a solver to be ranked highly in a competition carries considerable weight. But to which extent can we expect competition results to generalise to sets of problem instances different from those used in a particular competition? This is the question we investigate here, using statistical resampling techniques. We show that the rankings resulting from the standard interpretation of competition results can be very sensitive to even minor changes in the benchmark instance set used as the basis for assessment and can therefore not be expected to carry over to other samples from the same underlying instance distribution. To address this problem, we introduce a novel approach to statistically meaningful analysis of competition results based on resampling performance data. Our approach produces confidence intervals of competition scores as well as statistically robust solver rankings with bounded error. Applied to recent SAT, AI planning and computer vision competitions, our analysis reveals frequent statistical ties in solver performance as well as some inversions of ranks compared to the official results based on simple scoring.
Artificial intelligence to advance Earth observation: a perspective
May 15, 2023
Earth observation (EO) is a prime instrument for monitoring land and ocean processes, studying the dynamics at work, and taking the pulse of our planet. This article gives a bird's eye view of the essential scientific tools and approaches informing and supporting the transition from raw EO data to usable EO-based information. The promises, as well as the current challenges of these developments, are highlighted under dedicated sections. Specifically, we cover the impact of (i) Computer vision; (ii) Machine learning; (iii) Advanced processing and computing; (iv) Knowledge-based AI; (v) Explainable AI and causal inference; (vi) Physics-aware models; (vii) User-centric approaches; and (viii) the much-needed discussion of ethical and societal issues related to the massive use of ML technologies in EO.
Frugal Machine Learning
Nov 05, 2021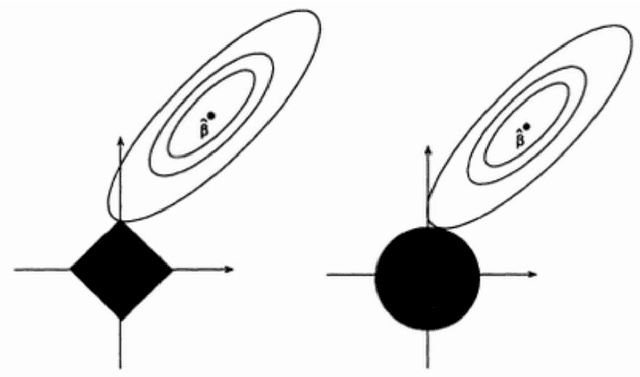
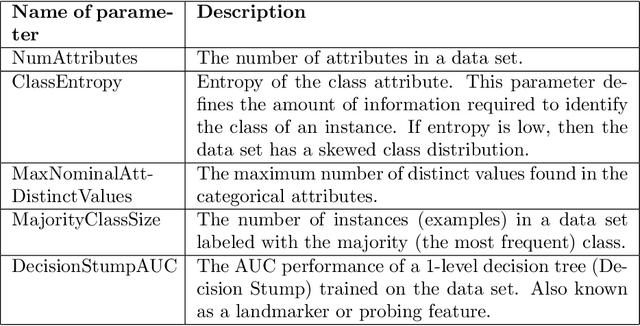
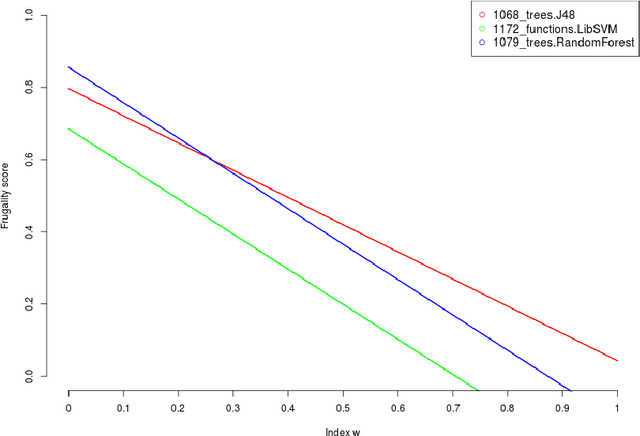
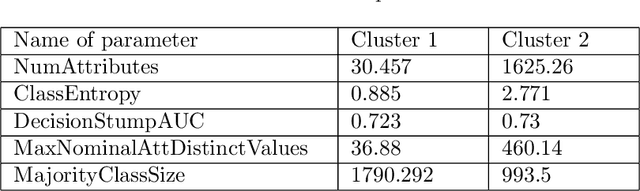
Machine learning, already at the core of increasingly many systems and applications, is set to become even more ubiquitous with the rapid rise of wearable devices and the Internet of Things. In most machine learning applications, the main focus is on the quality of the results achieved (e.g., prediction accuracy), and hence vast amounts of data are being collected, requiring significant computational resources to build models. In many scenarios, however, it is infeasible or impractical to set up large centralized data repositories. In personal health, for instance, privacy issues may inhibit the sharing of detailed personal data. In such cases, machine learning should ideally be performed on wearable devices themselves, which raises major computational limitations such as the battery capacity of smartwatches. This paper thus investigates frugal learning, aimed to build the most accurate possible models using the least amount of resources. A wide range of learning algorithms is examined through a frugal lens, analyzing their accuracy/runtime performance on a wide range of data sets. The most promising algorithms are thereafter assessed in a real-world scenario by implementing them in a smartwatch and letting them learn activity recognition models on the watch itself.
Automating Data Science: Prospects and Challenges
May 12, 2021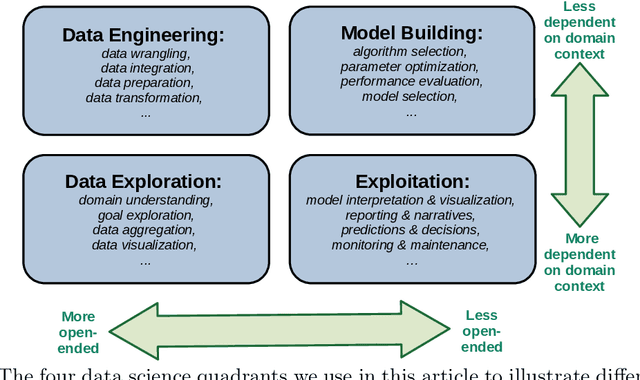

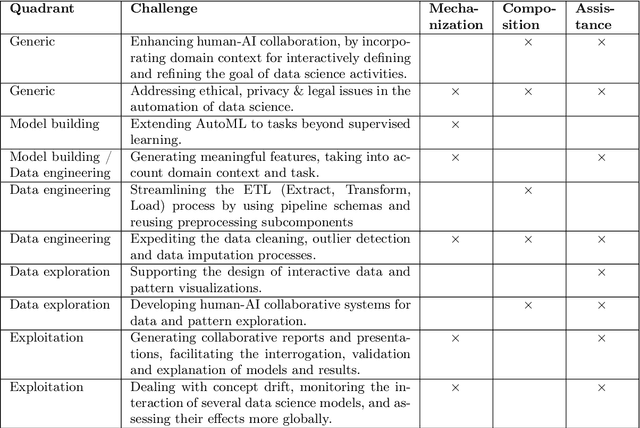
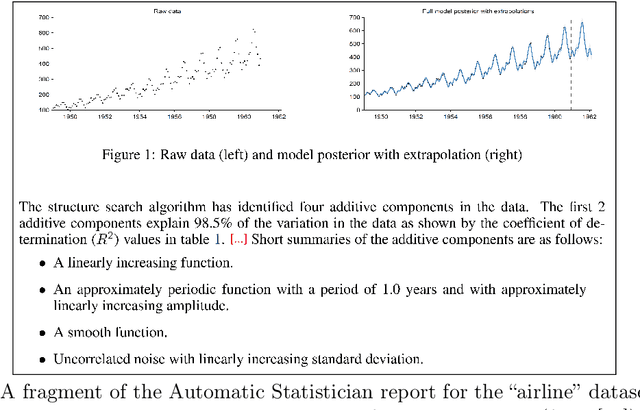
Given the complexity of typical data science projects and the associated demand for human expertise, automation has the potential to transform the data science process. Key insights: * Automation in data science aims to facilitate and transform the work of data scientists, not to replace them. * Important parts of data science are already being automated, especially in the modeling stages, where techniques such as automated machine learning (AutoML) are gaining traction. * Other aspects are harder to automate, not only because of technological challenges, but because open-ended and context-dependent tasks require human interaction.
Automated Configuration of Negotiation Strategies
Mar 31, 2020



Bidding and acceptance strategies have a substantial impact on the outcome of negotiations in scenarios with linear additive and nonlinear utility functions. Over the years, it has become clear that there is no single best strategy for all negotiation settings, yet many fixed strategies are still being developed. We envision a shift in the strategy design question from: What is a good strategy?, towards: What could be a good strategy? For this purpose, we developed a method leveraging automated algorithm configuration to find the best strategies for a specific set of negotiation settings. By empowering automated negotiating agents using automated algorithm configuration, we obtain a flexible negotiation agent that can be configured automatically for a rich space of opponents and negotiation scenarios. To critically assess our approach, the agent was tested in an ANAC-like bilateral automated negotiation tournament setting against past competitors. We show that our automatically configured agent outperforms all other agents, with a 5.1% increase in negotiation payoff compared to the next-best agent. We note that without our agent in the tournament, the top-ranked agent wins by a margin of only 0.01%.
Improving the Performance of Stochastic Local Search for Maximum Vertex Weight Clique Problem Using Programming by Optimization
Feb 27, 2020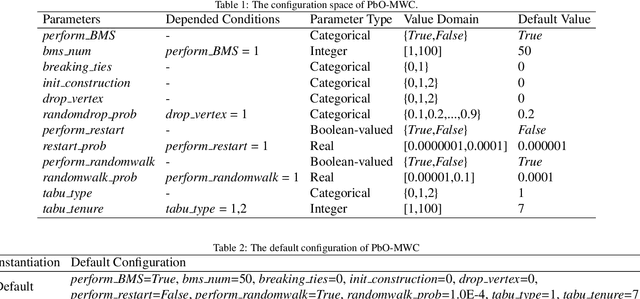



The maximum vertex weight clique problem (MVWCP) is an important generalization of the maximum clique problem (MCP) that has a wide range of real-world applications. In situations where rigorous guarantees regarding the optimality of solutions are not required, MVWCP is usually solved using stochastic local search (SLS) algorithms, which also define the state of the art for solving this problem. However, there is no single SLS algorithm which gives the best performance across all classes of MVWCP instances, and it is challenging to effectively identify the most suitable algorithm for each class of MVWCP instances. In this work, we follow the paradigm of Programming by Optimization (PbO) to develop a new, flexible and highly parametric SLS framework for solving MVWCP, combining, for the first time, a broad range of effective heuristic mechanisms. By automatically configuring this PbO-MWC framework, we achieve substantial advances in the state-of-the-art in solving MVWCP over a broad range of prominent benchmarks, including two derived from real-world applications in transplantation medicine (kidney exchange) and assessment of research excellence.
Automated Algorithm Selection: Survey and Perspectives
Nov 28, 2018It has long been observed that for practically any computational problem that has been intensely studied, different instances are best solved using different algorithms. This is particularly pronounced for computationally hard problems, where in most cases, no single algorithm defines the state of the art; instead, there is a set of algorithms with complementary strengths. This performance complementarity can be exploited in various ways, one of which is based on the idea of selecting, from a set of given algorithms, for each problem instance to be solved the one expected to perform best. The task of automatically selecting an algorithm from a given set is known as the per-instance algorithm selection problem and has been intensely studied over the past 15 years, leading to major improvements in the state of the art in solving a growing number of discrete combinatorial problems, including propositional satisfiability and AI planning. Per-instance algorithm selection also shows much promise for boosting performance in solving continuous and mixed discrete/continuous optimisation problems. This survey provides an overview of research in automated algorithm selection, ranging from early and seminal works to recent and promising application areas. Different from earlier work, it covers applications to discrete and continuous problems, and discusses algorithm selection in context with conceptually related approaches, such as algorithm configuration, scheduling or portfolio selection. Since informative and cheaply computable problem instance features provide the basis for effective per-instance algorithm selection systems, we also provide an overview of such features for discrete and continuous problems. Finally, we provide perspectives on future work in the area and discuss a number of open research challenges.
Hot-Rodding the Browser Engine: Automatic Configuration of JavaScript Compilers
Jul 11, 2017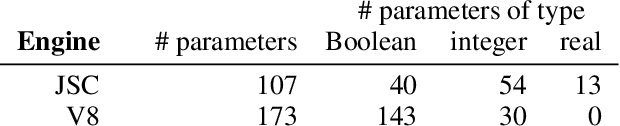
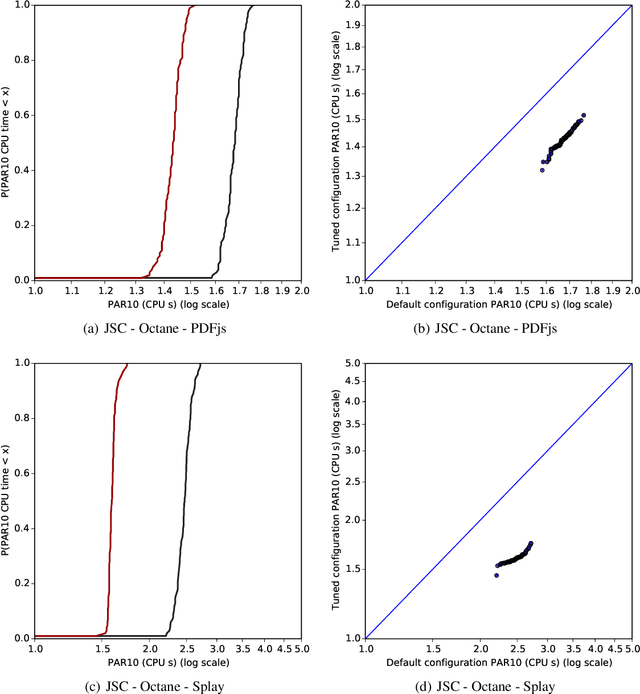
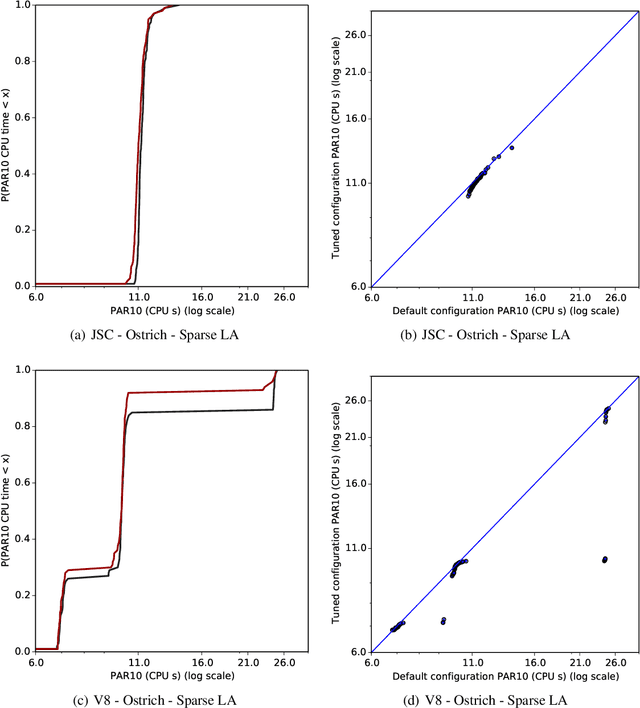

Modern software systems in many application areas offer to the user a multitude of parameters, switches and other customisation hooks. Humans tend to have difficulties determining the best configurations for particular applications. Modern optimising compilers are an example of such software systems; their many parameters need to be tuned for optimal performance, but are often left at the default values for convenience. In this work, we automatically determine compiler parameter settings that result in optimised performance for particular applications. Specifically, we apply a state-of-the-art automated parameter configuration procedure based on cutting-edge machine learning and optimisation techniques to two prominent JavaScript compilers and demonstrate that significant performance improvements, more than 35% in some cases, can be achieved over the default parameter settings on a diverse set of benchmarks.
Efficient Benchmarking of Algorithm Configuration Procedures via Model-Based Surrogates
Mar 30, 2017



The optimization of algorithm (hyper-)parameters is crucial for achieving peak performance across a wide range of domains, ranging from deep neural networks to solvers for hard combinatorial problems. The resulting algorithm configuration (AC) problem has attracted much attention from the machine learning community. However, the proper evaluation of new AC procedures is hindered by two key hurdles. First, AC benchmarks are hard to set up. Second and even more significantly, they are computationally expensive: a single run of an AC procedure involves many costly runs of the target algorithm whose performance is to be optimized in a given AC benchmark scenario. One common workaround is to optimize cheap-to-evaluate artificial benchmark functions (e.g., Branin) instead of actual algorithms; however, these have different properties than realistic AC problems. Here, we propose an alternative benchmarking approach that is similarly cheap to evaluate but much closer to the original AC problem: replacing expensive benchmarks by surrogate benchmarks constructed from AC benchmarks. These surrogate benchmarks approximate the response surface corresponding to true target algorithm performance using a regression model, and the original and surrogate benchmark share the same (hyper-)parameter space. In our experiments, we construct and evaluate surrogate benchmarks for hyperparameter optimization as well as for AC problems that involve performance optimization of solvers for hard combinatorial problems, drawing training data from the runs of existing AC procedures. We show that our surrogate benchmarks capture overall important characteristics of the AC scenarios, such as high- and low-performing regions, from which they were derived, while being much easier to use and orders of magnitude cheaper to evaluate.
Stacked Quantizers for Compositional Vector Compression
Nov 08, 2014



Recently, Babenko and Lempitsky introduced Additive Quantization (AQ), a generalization of Product Quantization (PQ) where a non-independent set of codebooks is used to compress vectors into small binary codes. Unfortunately, under this scheme encoding cannot be done independently in each codebook, and optimal encoding is an NP-hard problem. In this paper, we observe that PQ and AQ are both compositional quantizers that lie on the extremes of the codebook dependence-independence assumption, and explore an intermediate approach that exploits a hierarchical structure in the codebooks. This results in a method that achieves quantization error on par with or lower than AQ, while being several orders of magnitude faster. We perform a complexity analysis of PQ, AQ and our method, and evaluate our approach on standard benchmarks of SIFT and GIST descriptors, as well as on new datasets of features obtained from state-of-the-art convolutional neural networks.