 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLan-Zhe Guo
Investigating the Limitation of CLIP Models: The Worst-Performing Categories
Oct 05, 2023
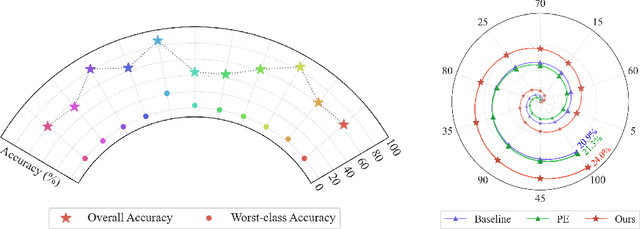
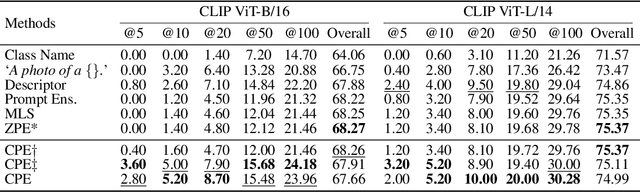
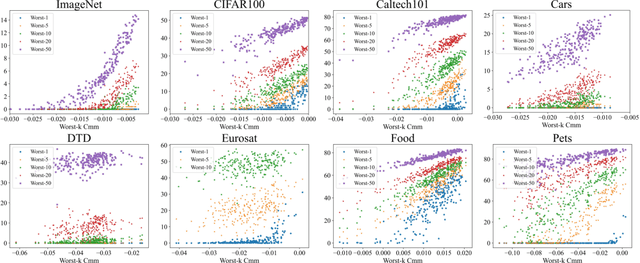
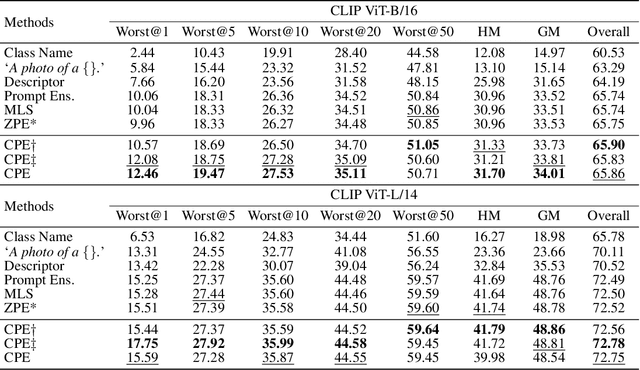
Contrastive Language-Image Pre-training (CLIP) provides a foundation model by integrating natural language into visual concepts, enabling zero-shot recognition on downstream tasks. It is usually expected that satisfactory overall accuracy can be achieved across numerous domains through well-designed textual prompts. However, we found that their performance in the worst categories is significantly inferior to the overall performance. For example, on ImageNet, there are a total of 10 categories with class-wise accuracy as low as 0\%, even though the overall performance has achieved 64.1\%. This phenomenon reveals the potential risks associated with using CLIP models, particularly in risk-sensitive applications where specific categories hold significant importance. To address this issue, we investigate the alignment between the two modalities in the CLIP model and propose the Class-wise Matching Margin (\cmm) to measure the inference confusion. \cmm\ can effectively identify the worst-performing categories and estimate the potential performance of the candidate prompts. We further query large language models to enrich descriptions of worst-performing categories and build a weighted ensemble to highlight the efficient prompts. Experimental results clearly verify the effectiveness of our proposal, where the accuracy on the worst-10 categories on ImageNet is boosted to 5.2\%, without manual prompt engineering, laborious optimization, or access to labeled validation data.
USB: A Unified Semi-supervised Learning Benchmark
Aug 12, 2022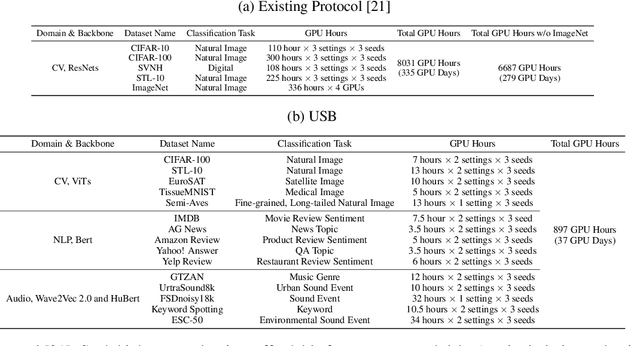
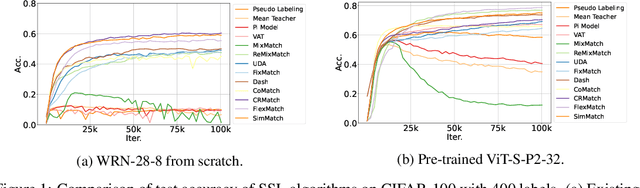
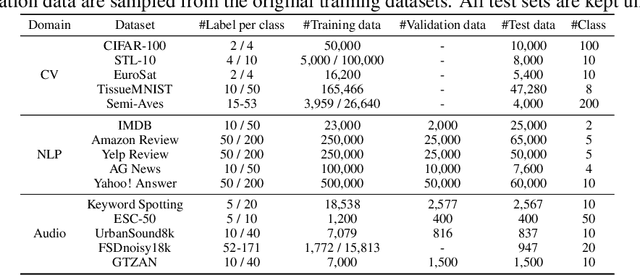
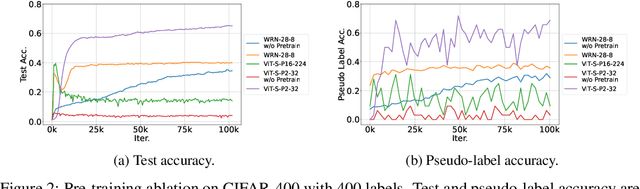
Semi-supervised learning (SSL) improves model generalization by leveraging massive unlabeled data to augment limited labeled samples. However, currently, popular SSL evaluation protocols are often constrained to computer vision (CV) tasks. In addition, previous work typically trains deep neural networks from scratch, which is time-consuming and environmentally unfriendly. To address the above issues, we construct a Unified SSL Benchmark (USB) by selecting 15 diverse, challenging, and comprehensive tasks from CV, natural language processing (NLP), and audio processing (Audio), on which we systematically evaluate dominant SSL methods, and also open-source a modular and extensible codebase for fair evaluation on these SSL methods. We further provide pre-trained versions of the state-of-the-art neural models for CV tasks to make the cost affordable for further tuning. USB enables the evaluation of a single SSL algorithm on more tasks from multiple domains but with less cost. Specifically, on a single NVIDIA V100, only 37 GPU days are required to evaluate FixMatch on 15 tasks in USB while 335 GPU days (279 GPU days on 4 CV datasets except for ImageNet) are needed on 5 CV tasks with the typical protocol.
LAMDA-SSL: Semi-Supervised Learning in Python
Aug 09, 2022
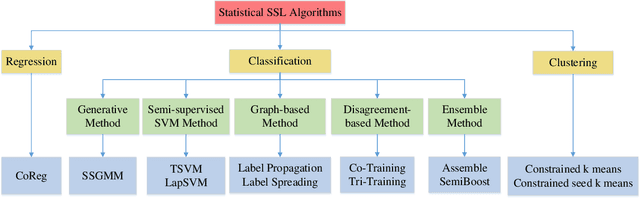
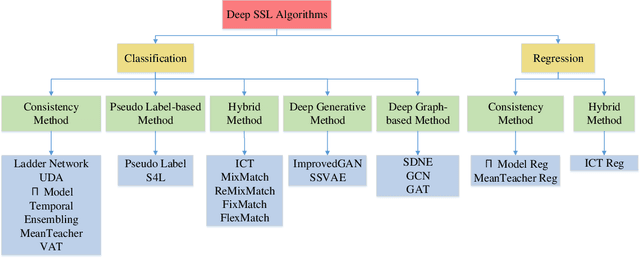
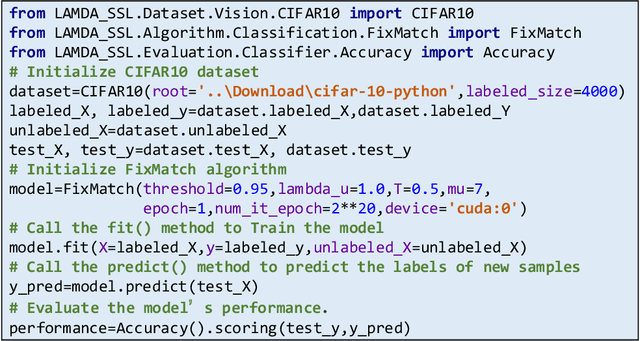
LAMDA-SSL is open-sourced on GitHub and its detailed usage documentation is available at https://ygzwqzd.github.io/LAMDA-SSL/. This documentation introduces LAMDA-SSL in detail from various aspects and can be divided into four parts. The first part introduces the design idea, features and functions of LAMDA-SSL. The second part shows the usage of LAMDA-SSL by abundant examples in detail. The third part introduces all algorithms implemented by LAMDA-SSL to help users quickly understand and choose SSL algorithms. The fourth part shows the APIs of LAMDA-SSL. This detailed documentation greatly reduces the cost of familiarizing users with LAMDA-SSL toolkit and SSL algorithms.
Transfer and Share: Semi-Supervised Learning from Long-Tailed Data
May 26, 2022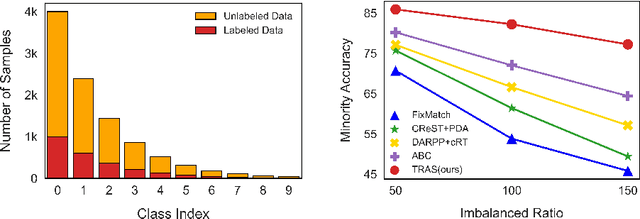
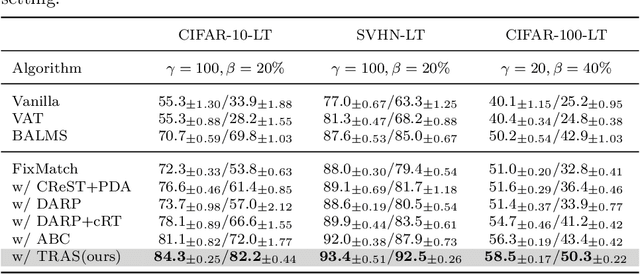
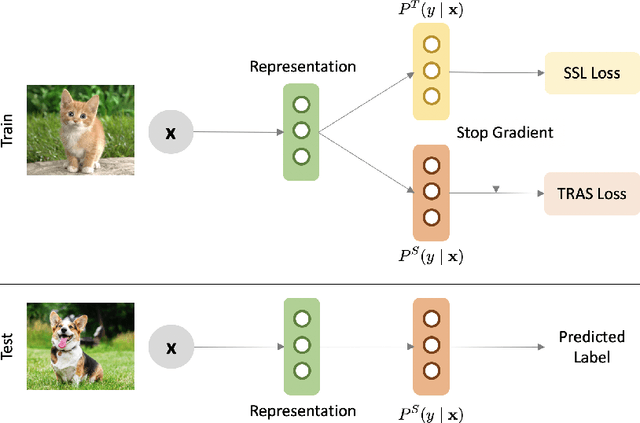

Long-Tailed Semi-Supervised Learning (LTSSL) aims to learn from class-imbalanced data where only a few samples are annotated. Existing solutions typically require substantial cost to solve complex optimization problems, or class-balanced undersampling which can result in information loss. In this paper, we present the TRAS (TRAnsfer and Share) to effectively utilize long-tailed semi-supervised data. TRAS transforms the imbalanced pseudo-label distribution of a traditional SSL model via a delicate function to enhance the supervisory signals for minority classes. It then transfers the distribution to a target model such that the minority class will receive significant attention. Interestingly, TRAS shows that more balanced pseudo-label distribution can substantially benefit minority-class training, instead of seeking to generate accurate pseudo-labels as in previous works. To simplify the approach, TRAS merges the training of the traditional SSL model and the target model into a single procedure by sharing the feature extractor, where both classifiers help improve the representation learning. According to extensive experiments, TRAS delivers much higher accuracy than state-of-the-art methods in the entire set of classes as well as minority classes.
Robust Deep Semi-Supervised Learning: A Brief Introduction
Feb 12, 2022
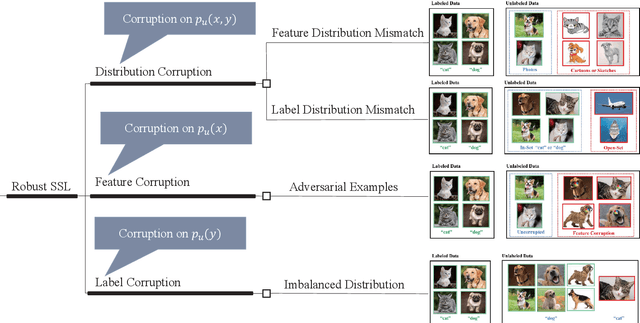


Semi-supervised learning (SSL) is the branch of machine learning that aims to improve learning performance by leveraging unlabeled data when labels are insufficient. Recently, SSL with deep models has proven to be successful on standard benchmark tasks. However, they are still vulnerable to various robustness threats in real-world applications as these benchmarks provide perfect unlabeled data, while in realistic scenarios, unlabeled data could be corrupted. Many researchers have pointed out that after exploiting corrupted unlabeled data, SSL suffers severe performance degradation problems. Thus, there is an urgent need to develop SSL algorithms that could work robustly with corrupted unlabeled data. To fully understand robust SSL, we conduct a survey study. We first clarify a formal definition of robust SSL from the perspective of machine learning. Then, we classify the robustness threats into three categories: i) distribution corruption, i.e., unlabeled data distribution is mismatched with labeled data; ii) feature corruption, i.e., the features of unlabeled examples are adversarially attacked; and iii) label corruption, i.e., the label distribution of unlabeled data is imbalanced. Under this unified taxonomy, we provide a thorough review and discussion of recent works that focus on these issues. Finally, we propose possible promising directions within robust SSL to provide insights for future research.
Weakly Supervised Learning Meets Ride-Sharing User Experience Enhancement
Jan 19, 2020
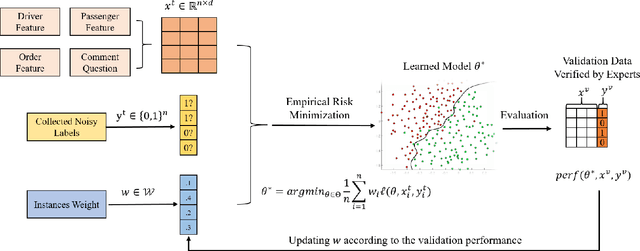
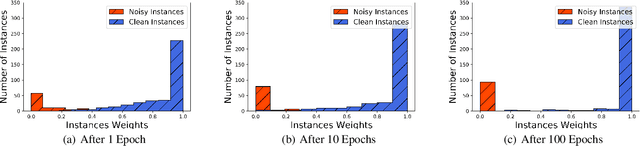
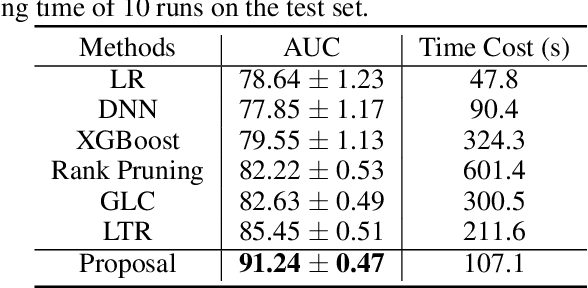
Weakly supervised learning aims at coping with scarce labeled data. Previous weakly supervised studies typically assume that there is only one kind of weak supervision in data. In many applications, however, raw data usually contains more than one kind of weak supervision at the same time. For example, in user experience enhancement from Didi, one of the largest online ride-sharing platforms, the ride comment data contains severe label noise (due to the subjective factors of passengers) and severe label distribution bias (due to the sampling bias). We call such a problem as "compound weakly supervised learning". In this paper, we propose the CWSL method to address this problem based on Didi ride-sharing comment data. Specifically, an instance reweighting strategy is employed to cope with severe label noise in comment data, where the weights for harmful noisy instances are small. Robust criteria like AUC rather than accuracy and the validation performance are optimized for the correction of biased data label. Alternating optimization and stochastic gradient methods accelerate the optimization on large-scale data. Experiments on Didi ride-sharing comment data clearly validate the effectiveness. We hope this work may shed some light on applying weakly supervised learning to complex real situations.
Reliable Weakly Supervised Learning: Maximize Gain and Maintain Safeness
Apr 22, 2019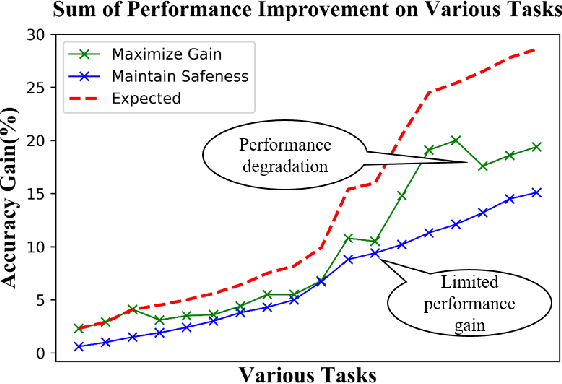
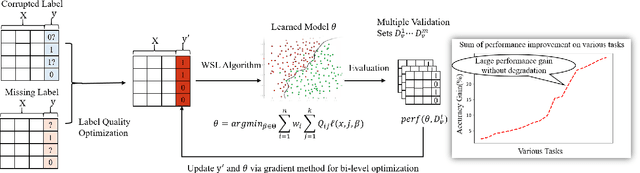


Weakly supervised data are widespread and have attracted much attention. However, since label quality is often difficult to guarantee, sometimes the use of weakly supervised data will lead to unsatisfactory performance, i.e., performance degradation or poor performance gains. Moreover, it is usually not feasible to manually increase the label quality, which results in weakly supervised learning being somewhat difficult to rely on. In view of this crucial issue, this paper proposes a simple and novel weakly supervised learning framework. We guide the optimization of label quality through a small amount of validation data, and to ensure the safeness of performance while maximizing performance gain. As validation set is a good approximation for describing generalization risk, it can effectively avoid the unsatisfactory performance caused by incorrect data distribution assumptions. We formalize this underlying consideration into a novel Bi-Level optimization and give an effective solution. Extensive experimental results verify that the new framework achieves impressive performance on weakly supervised learning with a small amount of validation data.