 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNevin L. Zhang
Resilient Practical Test-Time Adaptation: Soft Batch Normalization Alignment and Entropy-driven Memory Bank
Jan 26, 2024
Test-time domain adaptation effectively adjusts the source domain model to accommodate unseen domain shifts in a target domain during inference. However, the model performance can be significantly impaired by continuous distribution changes in the target domain and non-independent and identically distributed (non-i.i.d.) test samples often encountered in practical scenarios. While existing memory bank methodologies use memory to store samples and mitigate non-i.i.d. effects, they do not inherently prevent potential model degradation. To address this issue, we propose a resilient practical test-time adaptation (ResiTTA) method focused on parameter resilience and data quality. Specifically, we develop a resilient batch normalization with estimation on normalization statistics and soft alignments to mitigate overfitting and model degradation. We use an entropy-driven memory bank that accounts for timeliness, the persistence of over-confident samples, and sample uncertainty for high-quality data in adaptation. Our framework periodically adapts the source domain model using a teacher-student model through a self-training loss on the memory samples, incorporating soft alignment losses on batch normalization. We empirically validate ResiTTA across various benchmark datasets, demonstrating state-of-the-art performance.
Robustness May be More Brittle than We Think under Different Degrees of Distribution Shifts
Oct 10, 2023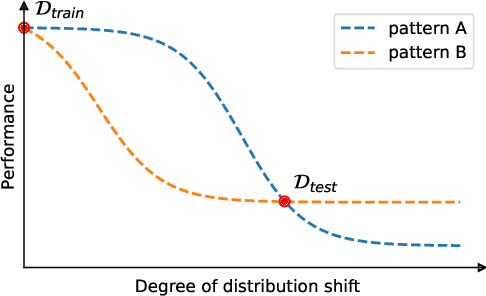
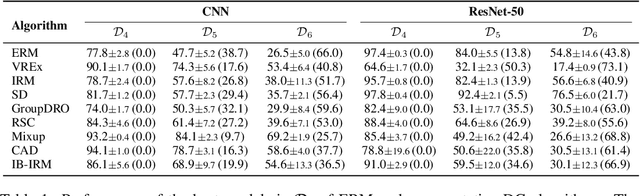

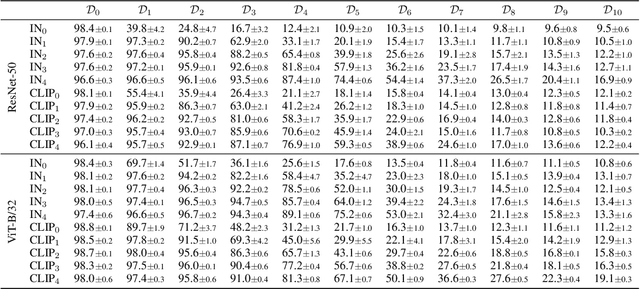
Out-of-distribution (OOD) generalization is a complicated problem due to the idiosyncrasies of possible distribution shifts between training and test domains. Most benchmarks employ diverse datasets to address this issue; however, the degree of the distribution shift between the training domains and the test domains of each dataset remains largely fixed. This may lead to biased conclusions that either underestimate or overestimate the actual OOD performance of a model. Our study delves into a more nuanced evaluation setting that covers a broad range of shift degrees. We show that the robustness of models can be quite brittle and inconsistent under different degrees of distribution shifts, and therefore one should be more cautious when drawing conclusions from evaluations under a limited range of degrees. In addition, we observe that large-scale pre-trained models, such as CLIP, are sensitive to even minute distribution shifts of novel downstream tasks. This indicates that while pre-trained representations may help improve downstream in-distribution performance, they could have minimal or even adverse effects on generalization in certain OOD scenarios of the downstream task if not used properly. In light of these findings, we encourage future research to conduct evaluations across a broader range of shift degrees whenever possible.
A Preliminary Study of the Intrinsic Relationship between Complexity and Alignment
Aug 10, 2023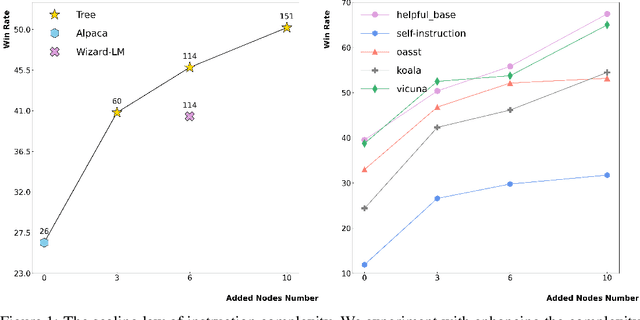
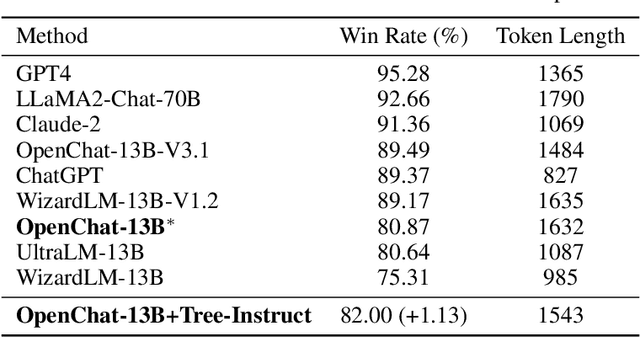
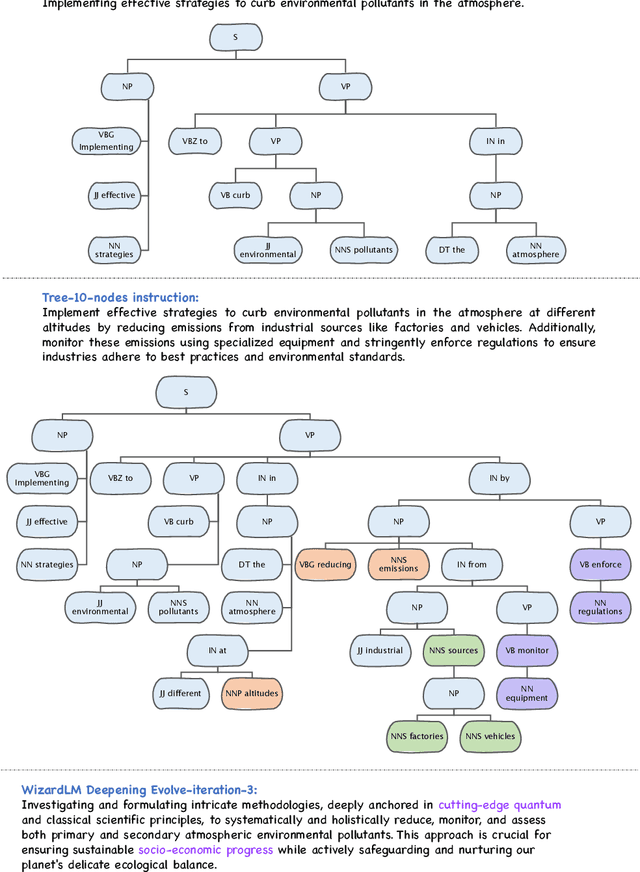
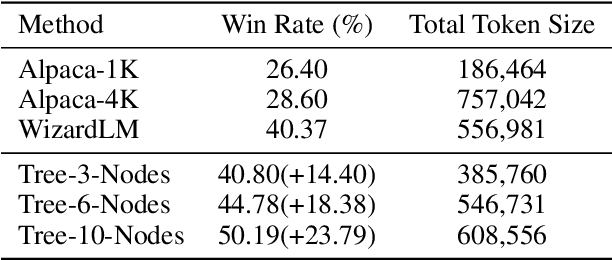
Training large language models (LLMs) with open-domain instruction data has yielded remarkable success in aligning to end tasks and user preferences. Extensive research has highlighted that enhancing the quality and diversity of instruction data consistently improves performance. However, the impact of data complexity, as a crucial metric, remains relatively unexplored in three aspects: (1) scaling law, where the sustainability of performance improvements with increasing complexity is uncertain, (2) additional tokens, whether the improvement brought by complexity comes from introducing more training tokens, and (3) curriculum tuning, where the potential advantages of incorporating instructions ranging from easy to difficult are not yet fully understood. In this paper, we propose \textit{tree-instruct} to systematically enhance the complexity of instruction data in a controllable manner. This approach adds a specified number of nodes into the instruction semantic tree, yielding new instruction data based on the modified tree. By adjusting the number of added nodes, we can control the difficulty level in the modified instruction data. Our preliminary experiments reveal the following insights: (1) Increasing complexity consistently leads to sustained performance improvements. For instance, using 1,000 instruction data and 10 nodes resulted in a substantial 24\% increase in win rate. (2) Under the same token budget, a few complex instructions outperform diverse yet simple instructions. (3) Curriculum instruction tuning might not yield the anticipated results; focusing on increasing complexity appears to be the key.
A Causal Framework to Unify Common Domain Generalization Approaches
Jul 13, 2023

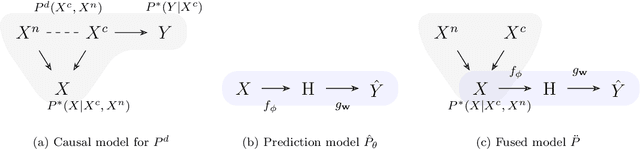
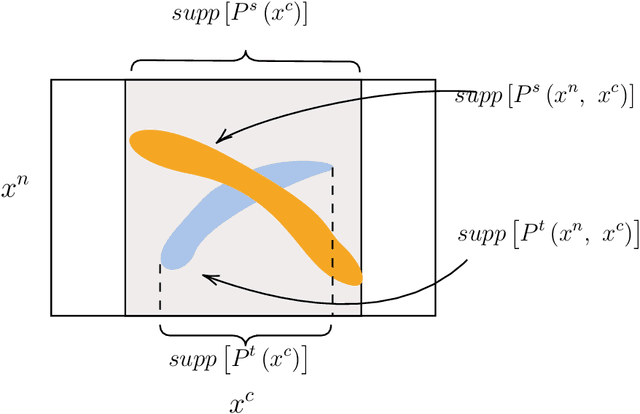
Domain generalization (DG) is about learning models that generalize well to new domains that are related to, but different from, the training domain(s). It is a fundamental problem in machine learning and has attracted much attention in recent years. A large number of approaches have been proposed. Different approaches are motivated from different perspectives, making it difficult to gain an overall understanding of the area. In this paper, we propose a causal framework for domain generalization and present an understanding of common DG approaches in the framework. Our work sheds new lights on the following questions: (1) What are the key ideas behind each DG method? (2) Why is it expected to improve generalization to new domains theoretically? (3) How are different DG methods related to each other and what are relative advantages and limitations? By providing a unified perspective on DG, we hope to help researchers better understand the underlying principles and develop more effective approaches for this critical problem in machine learning.
Two-Stage Holistic and Contrastive Explanation of Image Classification
Jun 10, 2023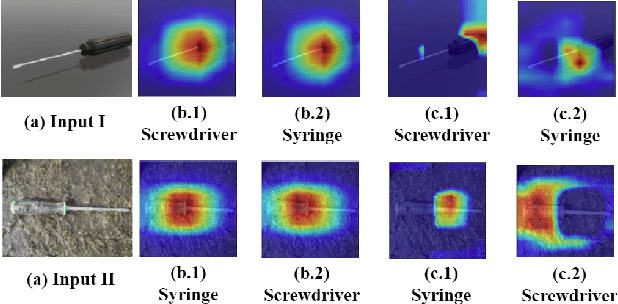
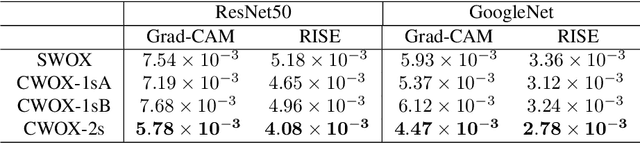

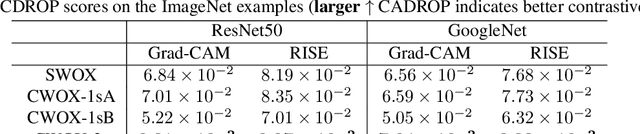
The need to explain the output of a deep neural network classifier is now widely recognized. While previous methods typically explain a single class in the output, we advocate explaining the whole output, which is a probability distribution over multiple classes. A whole-output explanation can help a human user gain an overall understanding of model behaviour instead of only one aspect of it. It can also provide a natural framework where one can examine the evidence used to discriminate between competing classes, and thereby obtain contrastive explanations. In this paper, we propose a contrastive whole-output explanation (CWOX) method for image classification, and evaluate it using quantitative metrics and through human subject studies. The source code of CWOX is available at https://github.com/vaynexie/CWOX.
Causal Document-Grounded Dialogue Pre-training
May 19, 2023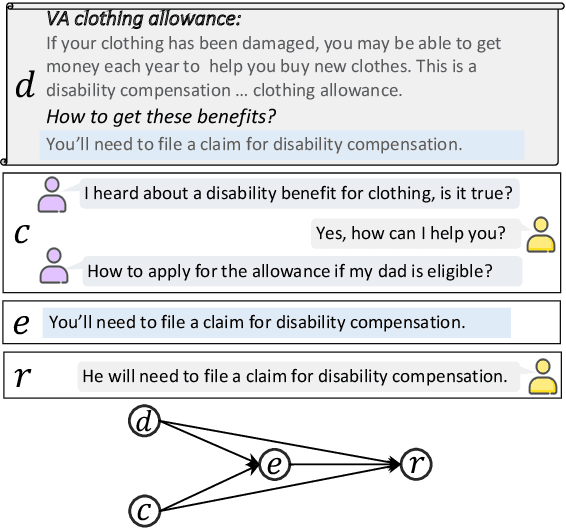


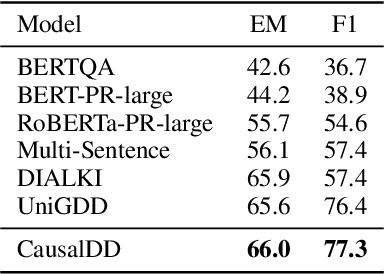
The goal of document-grounded dialogue (DocGD) is to generate a response by grounding the evidence in a supporting document in accordance with the dialogue context. This process involves four variables that are causally connected. Recently, task-specific pre-training has greatly boosted performances on many downstream tasks. Existing DocGD methods, however, continue to rely on general pre-trained language models without a specifically tailored pre-training approach that explicitly captures the causal relationships. To tackle this issue, we are the first to present a causally-complete dataset construction strategy for building million-level DocGD pre-training corpora. To better capture causality, we further propose a causally-perturbed pre-training strategy, which introduces causal perturbations on the variables and optimizes the overall causal effect. Experiments on three benchmark datasets demonstrate that our causal pre-training achieves considerable and consistent improvements under fully-supervised, low-resource, few-shot, and zero-shot settings.
Contrastive Domain Generalization via Logit Attribution Matching
May 13, 2023

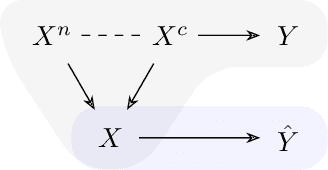

Domain Generalization (DG) is an important open problem in machine learning. Deep models are susceptible to domain shifts of even minute degrees, which severely compromises their reliability in real applications. To alleviate the issue, most existing methods enforce various invariant constraints across multiple training domains. However,such an approach provides little performance guarantee for novel test domains in general. In this paper, we investigate a different approach named Contrastive Domain Generalization (CDG), which exploits semantic invariance exhibited by strongly contrastive data pairs in lieu of multiple domains. We present a causal DG theory that shows the potential capability of CDG; together with a regularization technique, Logit Attribution Matching (LAM), for realizing CDG. We empirically show that LAM outperforms state-of-the-art DG methods with only a small portion of paired data and that LAM helps models better focus on semantic features which are crucial to DG.
Semi-Supervised Lifelong Language Learning
Nov 23, 2022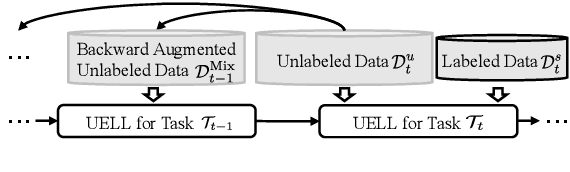
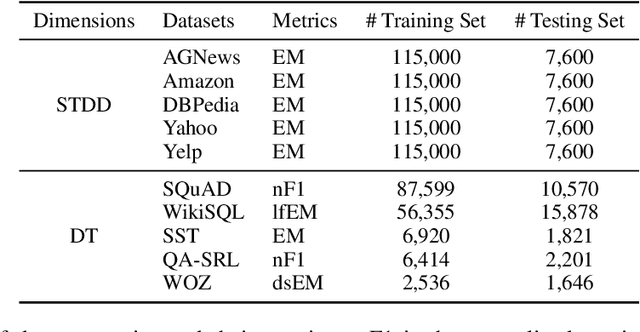

Lifelong learning aims to accumulate knowledge and alleviate catastrophic forgetting when learning tasks sequentially. However, existing lifelong language learning methods only focus on the supervised learning setting. Unlabeled data, which can be easily accessed in real-world scenarios, are underexplored. In this paper, we explore a novel setting, semi-supervised lifelong language learning (SSLL), where a model learns sequentially arriving language tasks with both labeled and unlabeled data. We propose an unlabeled data enhanced lifelong learner to explore SSLL. Specially, we dedicate task-specific modules to alleviate catastrophic forgetting and design two modules to exploit unlabeled data: (1) a virtual supervision enhanced task solver is constructed on a teacher-student framework to mine the underlying knowledge from unlabeled data; and (2) a backward augmented learner is built to encourage knowledge transfer from newly arrived unlabeled data to previous tasks. Experimental results on various language tasks demonstrate our model's effectiveness and superiority over competitive baselines under the new setting SSLL.
ViT-CX: Causal Explanation of Vision Transformers
Nov 06, 2022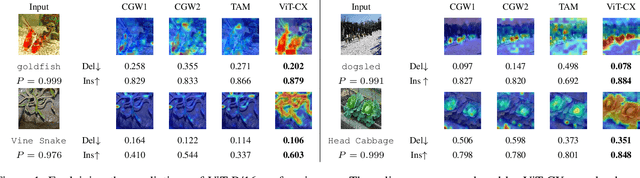
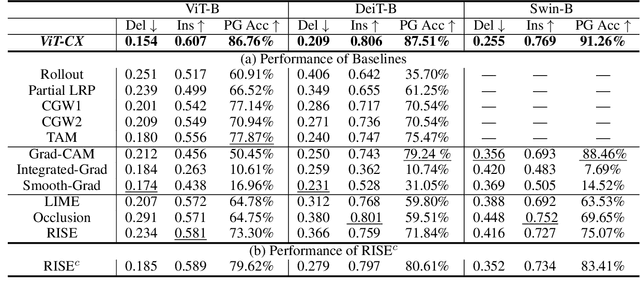
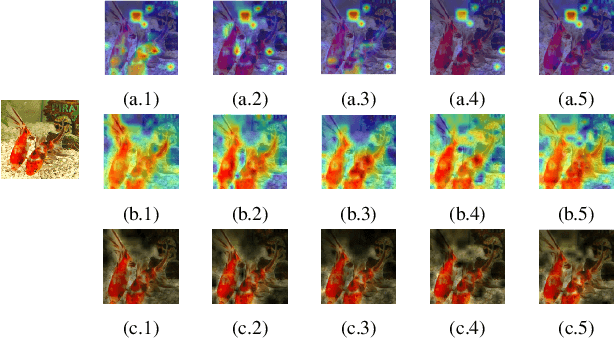
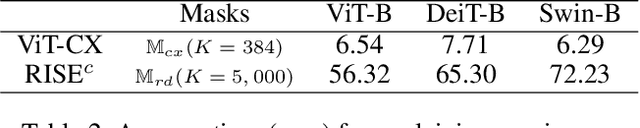
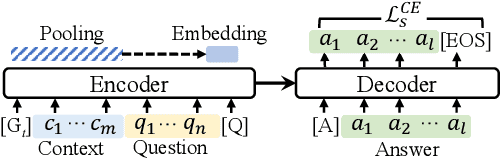
Despite the popularity of Vision Transformers (ViTs) and eXplainable AI (XAI), only a few explanation methods have been proposed for ViTs thus far. They use attention weights of the classification token on patch embeddings and often produce unsatisfactory saliency maps. In this paper, we propose a novel method for explaining ViTs called ViT-CX. It is based on patch embeddings, rather than attentions paid to them, and their causal impacts on the model output. ViT-CX can be used to explain different ViT models. Empirical results show that, in comparison with previous methods, ViT-CX produces more meaningful saliency maps and does a better job at revealing all the important evidence for prediction. It is also significantly more faithful to the model as measured by deletion AUC and insertion AUC.
Prompt Conditioned VAE: Enhancing Generative Replay for Lifelong Learning in Task-Oriented Dialogue
Oct 14, 2022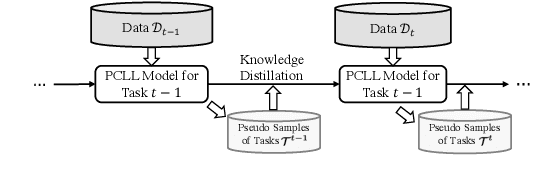
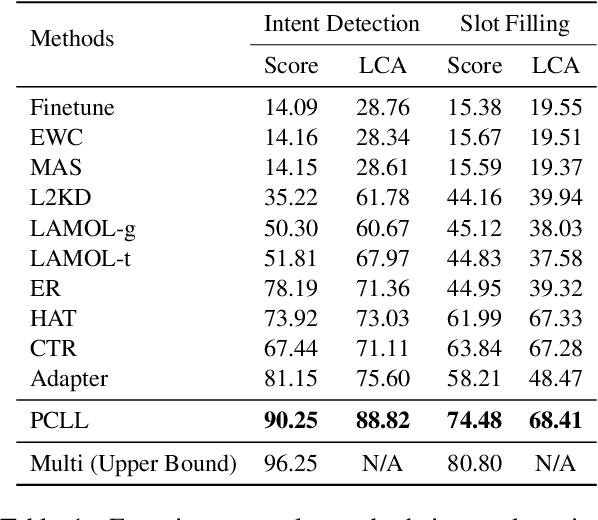
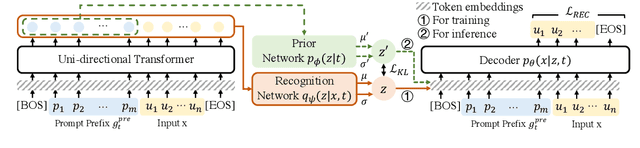
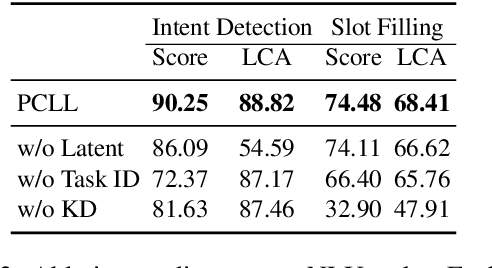
Lifelong learning (LL) is vital for advanced task-oriented dialogue (ToD) systems. To address the catastrophic forgetting issue of LL, generative replay methods are widely employed to consolidate past knowledge with generated pseudo samples. However, most existing generative replay methods use only a single task-specific token to control their models. This scheme is usually not strong enough to constrain the generative model due to insufficient information involved. In this paper, we propose a novel method, prompt conditioned VAE for lifelong learning (PCLL), to enhance generative replay by incorporating tasks' statistics. PCLL captures task-specific distributions with a conditional variational autoencoder, conditioned on natural language prompts to guide the pseudo-sample generation. Moreover, it leverages a distillation process to further consolidate past knowledge by alleviating the noise in pseudo samples. Experiments on natural language understanding tasks of ToD systems demonstrate that PCLL significantly outperforms competitive baselines in building LL models.