 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRichong Zhang
Improving Composed Image Retrieval via Contrastive Learning with Scaling Positives and Negatives
Apr 17, 2024
The Composed Image Retrieval (CIR) task aims to retrieve target images using a composed query consisting of a reference image and a modified text. Advanced methods often utilize contrastive learning as the optimization objective, which benefits from adequate positive and negative examples. However, the triplet for CIR incurs high manual annotation costs, resulting in limited positive examples. Furthermore, existing methods commonly use in-batch negative sampling, which reduces the negative number available for the model. To address the problem of lack of positives, we propose a data generation method by leveraging a multi-modal large language model to construct triplets for CIR. To introduce more negatives during fine-tuning, we design a two-stage fine-tuning framework for CIR, whose second stage introduces plenty of static representations of negatives to optimize the representation space rapidly. The above two improvements can be effectively stacked and designed to be plug-and-play, easily applied to existing CIR models without changing their original architectures. Extensive experiments and ablation analysis demonstrate that our method effectively scales positives and negatives and achieves state-of-the-art results on both FashionIQ and CIRR datasets. In addition, our methods also perform well in zero-shot composed image retrieval, providing a new CIR solution for the low-resources scenario.
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Mar 21, 2024
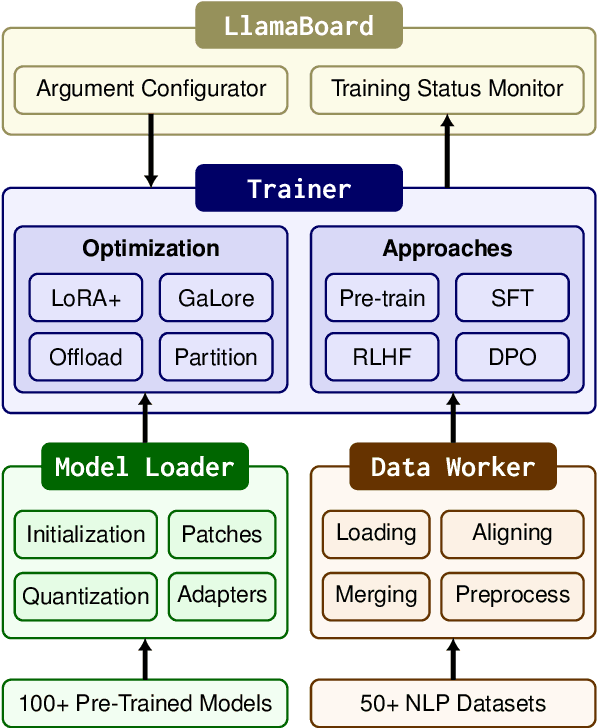

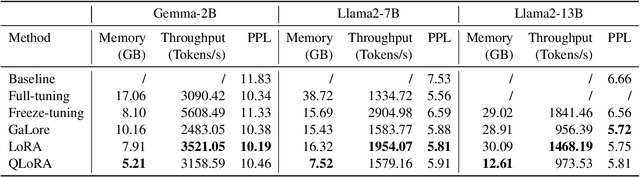
Efficient fine-tuning is vital for adapting large language models (LLMs) to downstream tasks. However, it requires non-trivial efforts to implement these methods on different models. We present LlamaFactory, a unified framework that integrates a suite of cutting-edge efficient training methods. It allows users to flexibly customize the fine-tuning of 100+ LLMs without the need for coding through the built-in web UI LlamaBoard. We empirically validate the efficiency and effectiveness of our framework on language modeling and text generation tasks. It has been released at https://github.com/hiyouga/LLaMA-Factory and already received over 13,000 stars and 1,600 forks.
Towards Better Understanding of Contrastive Sentence Representation Learning: A Unified Paradigm for Gradient
Feb 28, 2024Sentence Representation Learning (SRL) is a crucial task in Natural Language Processing (NLP), where contrastive Self-Supervised Learning (SSL) is currently a mainstream approach. However, the reasons behind its remarkable effectiveness remain unclear. Specifically, in other research fields, contrastive SSL shares similarities in both theory and practical performance with non-contrastive SSL (e.g., alignment & uniformity, Barlow Twins, and VICReg). However, in SRL, contrastive SSL outperforms non-contrastive SSL significantly. Therefore, two questions arise: First, what commonalities enable various contrastive losses to achieve superior performance in SRL? Second, how can we make non-contrastive SSL, which is similar to contrastive SSL but ineffective in SRL, effective? To address these questions, we start from the perspective of gradients and discover that four effective contrastive losses can be integrated into a unified paradigm, which depends on three components: the Gradient Dissipation, the Weight, and the Ratio. Then, we conduct an in-depth analysis of the roles these components play in optimization and experimentally demonstrate their significance for model performance. Finally, by adjusting these components, we enable non-contrastive SSL to achieve outstanding performance in SRL.
Anaphor Assisted Document-Level Relation Extraction
Oct 28, 2023Document-level relation extraction (DocRE) involves identifying relations between entities distributed in multiple sentences within a document. Existing methods focus on building a heterogeneous document graph to model the internal structure of an entity and the external interaction between entities. However, there are two drawbacks in existing methods. On one hand, anaphor plays an important role in reasoning to identify relations between entities but is ignored by these methods. On the other hand, these methods achieve cross-sentence entity interactions implicitly by utilizing a document or sentences as intermediate nodes. Such an approach has difficulties in learning fine-grained interactions between entities across different sentences, resulting in sub-optimal performance. To address these issues, we propose an Anaphor-Assisted (AA) framework for DocRE tasks. Experimental results on the widely-used datasets demonstrate that our model achieves a new state-of-the-art performance.
Narrowing the Gap between Supervised and Unsupervised Sentence Representation Learning with Large Language Model
Sep 12, 2023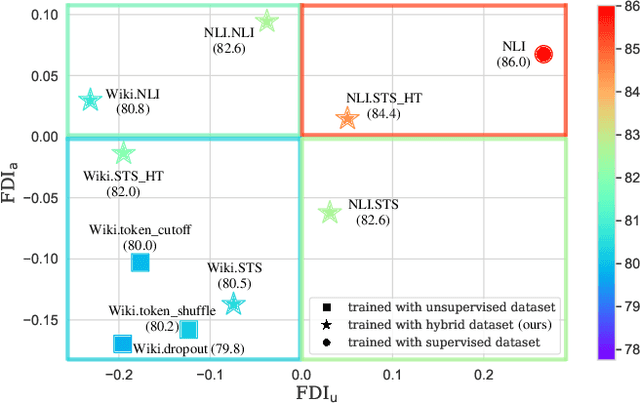
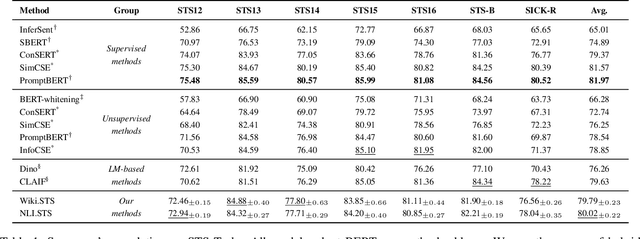
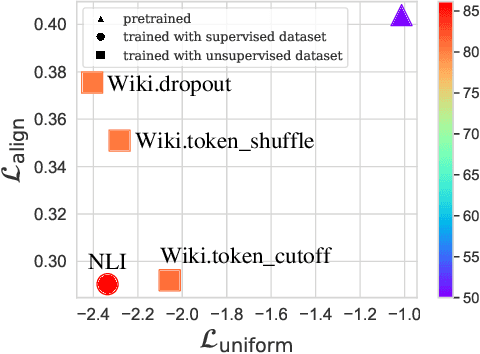
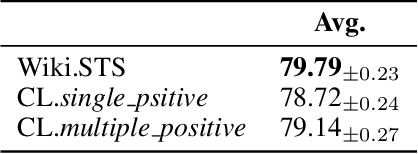
Sentence Representation Learning (SRL) is a fundamental task in Natural Language Processing (NLP), with Contrastive learning of Sentence Embeddings (CSE) as the mainstream technique due to its superior performance. An intriguing phenomenon in CSE is the significant performance gap between supervised and unsupervised methods, even when their sentence encoder and loss function are the same. Previous works attribute this performance gap to differences in two representation properties (alignment and uniformity). However, alignment and uniformity only measure the results, which means they cannot answer "What happens during the training process that leads to the performance gap?" and "How can the performance gap be narrowed?". In this paper, we conduct empirical experiments to answer these "What" and "How" questions. We first answer the "What" question by thoroughly comparing the behavior of supervised and unsupervised CSE during their respective training processes. From the comparison, We observe a significant difference in fitting difficulty. Thus, we introduce a metric, called Fitting Difficulty Increment (FDI), to measure the fitting difficulty gap between the evaluation dataset and the held-out training dataset, and use the metric to answer the "What" question. Then, based on the insights gained from the "What" question, we tackle the "How" question by increasing the fitting difficulty of the training dataset. We achieve this by leveraging the In-Context Learning (ICL) capability of the Large Language Model (LLM) to generate data that simulates complex patterns. By utilizing the hierarchical patterns in the LLM-generated data, we effectively narrow the gap between supervised and unsupervised CSE.
Code-Style In-Context Learning for Knowledge-Based Question Answering
Sep 09, 2023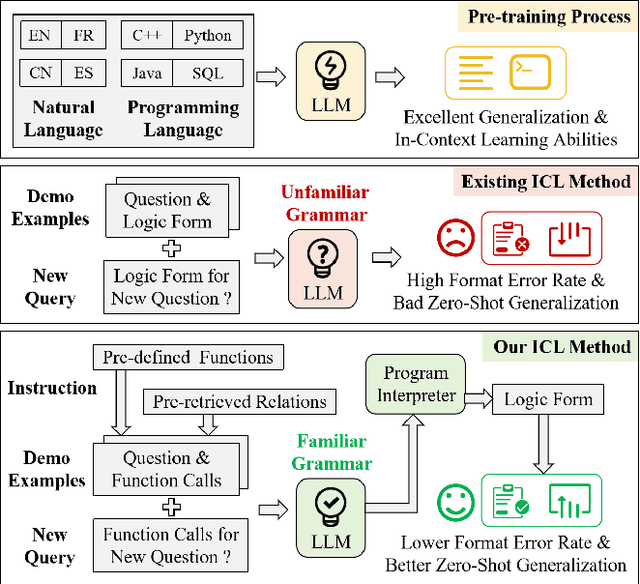


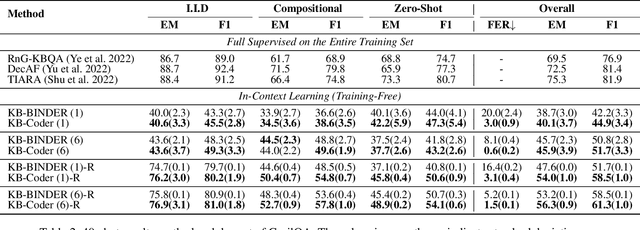
Current methods for Knowledge-Based Question Answering (KBQA) usually rely on complex training techniques and model frameworks, leading to many limitations in practical applications. Recently, the emergence of In-Context Learning (ICL) capabilities in Large Language Models (LLMs) provides a simple and training-free semantic parsing paradigm for KBQA: Given a small number of questions and their labeled logical forms as demo examples, LLMs can understand the task intent and generate the logic form for a new question. However, current powerful LLMs have little exposure to logic forms during pre-training, resulting in a high format error rate. To solve this problem, we propose a code-style in-context learning method for KBQA, which converts the generation process of unfamiliar logical form into the more familiar code generation process for LLMs. Experimental results on three mainstream datasets show that our method dramatically mitigated the formatting error problem in generating logic forms while realizing a new SOTA on WebQSP, GrailQA, and GraphQ under the few-shot setting.
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Jul 03, 2023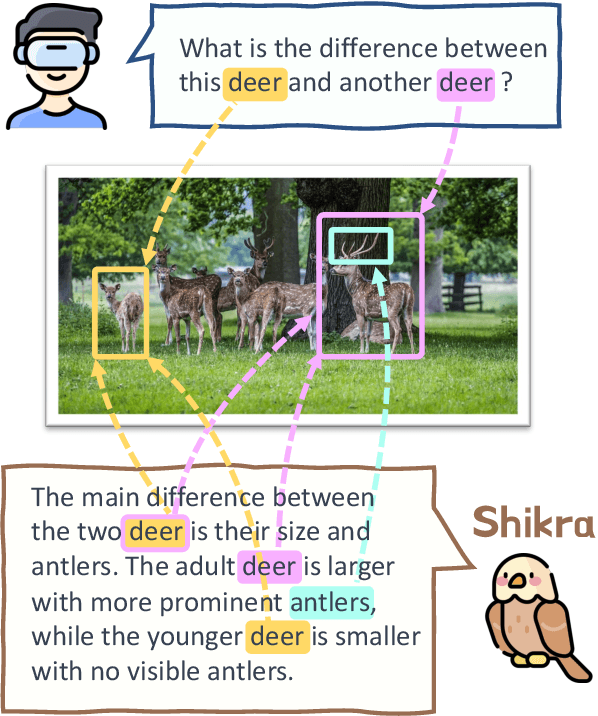
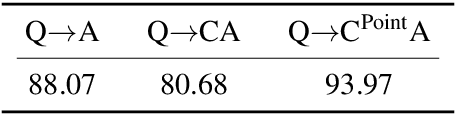

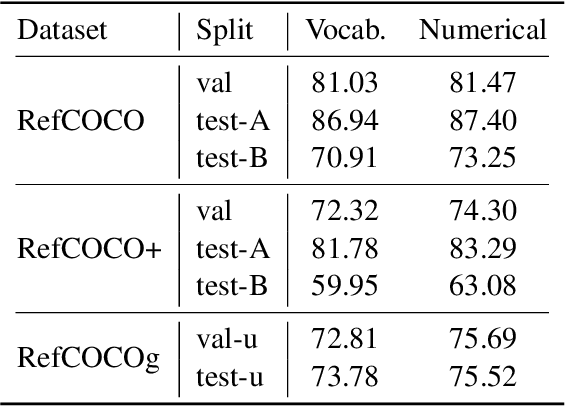
In human conversations, individuals can indicate relevant regions within a scene while addressing others. In turn, the other person can then respond by referring to specific regions if necessary. This natural referential ability in dialogue remains absent in current Multimodal Large Language Models (MLLMs). To fill this gap, this paper proposes an MLLM called Shikra, which can handle spatial coordinate inputs and outputs in natural language. Its architecture consists of a vision encoder, an alignment layer, and a LLM. It is designed to be straightforward and simple, without the need for extra vocabularies, position encoder, pre-/post-detection modules, or external plug-in models. All inputs and outputs are in natural language form. Referential dialogue is a superset of various vision-language (VL) tasks. Shikra can naturally handle location-related tasks like REC and PointQA, as well as conventional VL tasks such as Image Captioning and VQA. Experimental results showcase Shikra's promising performance. Furthermore, it enables numerous exciting applications, like providing mentioned objects' coordinates in chains of thoughts and comparing user-pointed regions similarities. Our code, model and dataset are accessed at https://github.com/shikras/shikra.
AdversarialWord Dilution as Text Data Augmentation in Low-Resource Regime
May 16, 2023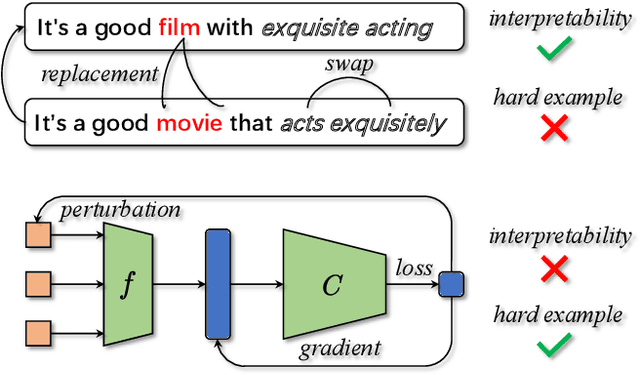
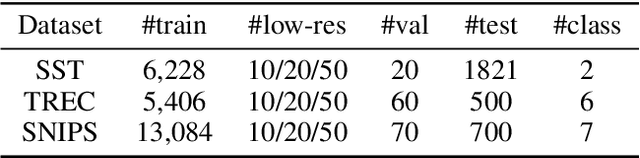
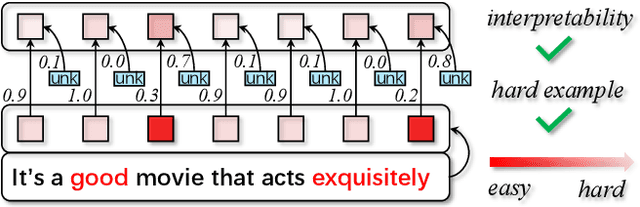
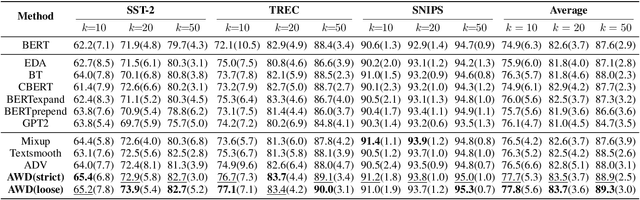
Data augmentation is widely used in text classification, especially in the low-resource regime where a few examples for each class are available during training. Despite the success, generating data augmentations as hard positive examples that may increase their effectiveness is under-explored. This paper proposes an Adversarial Word Dilution (AWD) method that can generate hard positive examples as text data augmentations to train the low-resource text classification model efficiently. Our idea of augmenting the text data is to dilute the embedding of strong positive words by weighted mixing with unknown-word embedding, making the augmented inputs hard to be recognized as positive by the classification model. We adversarially learn the dilution weights through a constrained min-max optimization process with the guidance of the labels. Empirical studies on three benchmark datasets show that AWD can generate more effective data augmentations and outperform the state-of-the-art text data augmentation methods. The additional analysis demonstrates that the data augmentations generated by AWD are interpretable and can flexibly extend to new examples without further training.
ContrastNet: A Contrastive Learning Framework for Few-Shot Text Classification
May 16, 2023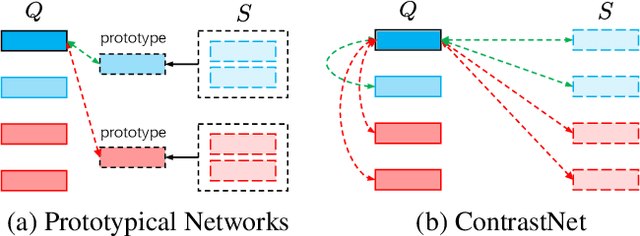
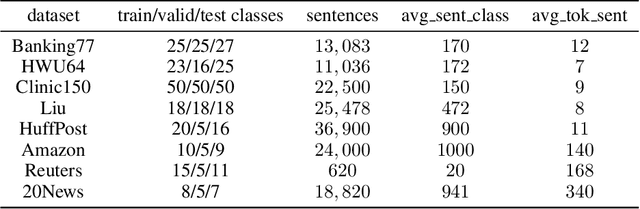
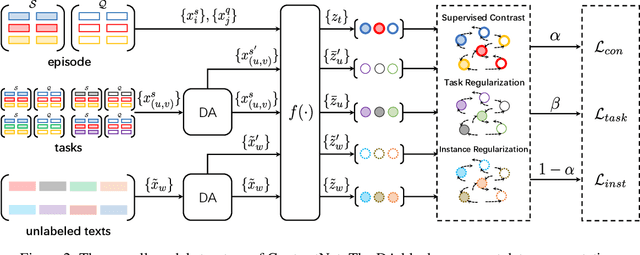
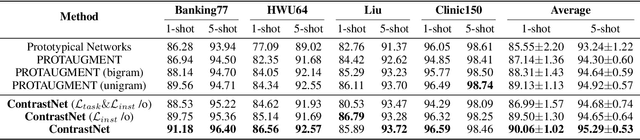
Few-shot text classification has recently been promoted by the meta-learning paradigm which aims to identify target classes with knowledge transferred from source classes with sets of small tasks named episodes. Despite their success, existing works building their meta-learner based on Prototypical Networks are unsatisfactory in learning discriminative text representations between similar classes, which may lead to contradictions during label prediction. In addition, the tasklevel and instance-level overfitting problems in few-shot text classification caused by a few training examples are not sufficiently tackled. In this work, we propose a contrastive learning framework named ContrastNet to tackle both discriminative representation and overfitting problems in few-shot text classification. ContrastNet learns to pull closer text representations belonging to the same class and push away text representations belonging to different classes, while simultaneously introducing unsupervised contrastive regularization at both task-level and instance-level to prevent overfitting. Experiments on 8 few-shot text classification datasets show that ContrastNet outperforms the current state-of-the-art models.
Self-training through Classifier Disagreement for Cross-Domain Opinion Target Extraction
Feb 28, 2023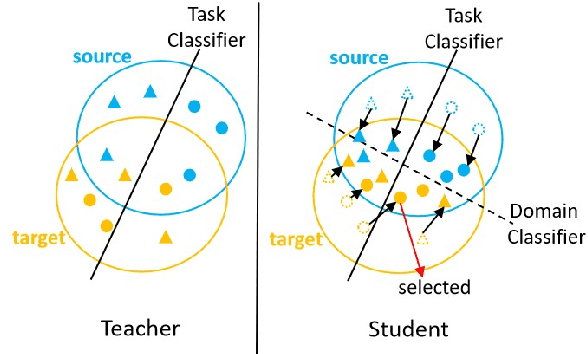
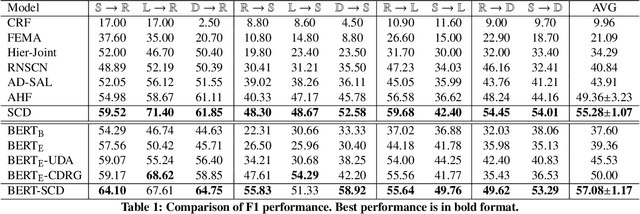
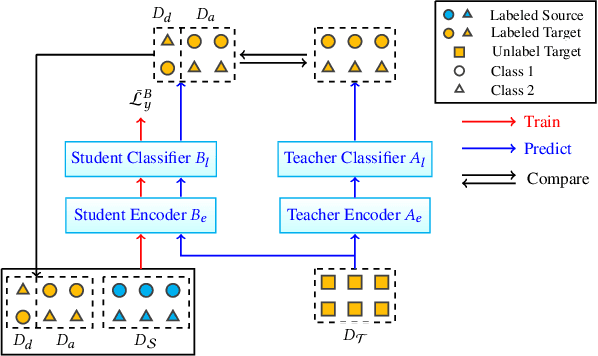
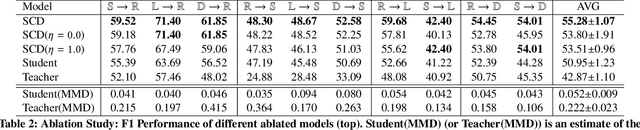
Opinion target extraction (OTE) or aspect extraction (AE) is a fundamental task in opinion mining that aims to extract the targets (or aspects) on which opinions have been expressed. Recent work focus on cross-domain OTE, which is typically encountered in real-world scenarios, where the testing and training distributions differ. Most methods use domain adversarial neural networks that aim to reduce the domain gap between the labelled source and unlabelled target domains to improve target domain performance. However, this approach only aligns feature distributions and does not account for class-wise feature alignment, leading to suboptimal results. Semi-supervised learning (SSL) has been explored as a solution, but is limited by the quality of pseudo-labels generated by the model. Inspired by the theoretical foundations in domain adaptation [2], we propose a new SSL approach that opts for selecting target samples whose model output from a domain-specific teacher and student network disagree on the unlabelled target data, in an effort to boost the target domain performance. Extensive experiments on benchmark cross-domain OTE datasets show that this approach is effective and performs consistently well in settings with large domain shifts.