 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXudong Liu
LEOD: Label-Efficient Object Detection for Event Cameras
Nov 29, 2023
Object detection with event cameras enjoys the property of low latency and high dynamic range, making it suitable for safety-critical scenarios such as self-driving. However, labeling event streams with high temporal resolutions for supervised training is costly. We address this issue with LEOD, the first framework for label-efficient event-based detection. Our method unifies weakly- and semi-supervised object detection with a self-training mechanism. We first utilize a detector pre-trained on limited labels to produce pseudo ground truth on unlabeled events, and then re-train the detector with both real and generated labels. Leveraging the temporal consistency of events, we run bi-directional inference and apply tracking-based post-processing to enhance the quality of pseudo labels. To stabilize training, we further design a soft anchor assignment strategy to mitigate the noise in labels. We introduce new experimental protocols to evaluate the task of label-efficient event-based detection on Gen1 and 1Mpx datasets. LEOD consistently outperforms supervised baselines across various labeling ratios. For example, on Gen1, it improves mAP by 8.6% and 7.8% for RVT-S trained with 1% and 2% labels. On 1Mpx, RVT-S with 10% labels even surpasses its fully-supervised counterpart using 100% labels. LEOD maintains its effectiveness even when all labeled data are available, reaching new state-of-the-art results. Finally, we show that our method readily scales to improve larger detectors as well.
Code-Style In-Context Learning for Knowledge-Based Question Answering
Sep 09, 2023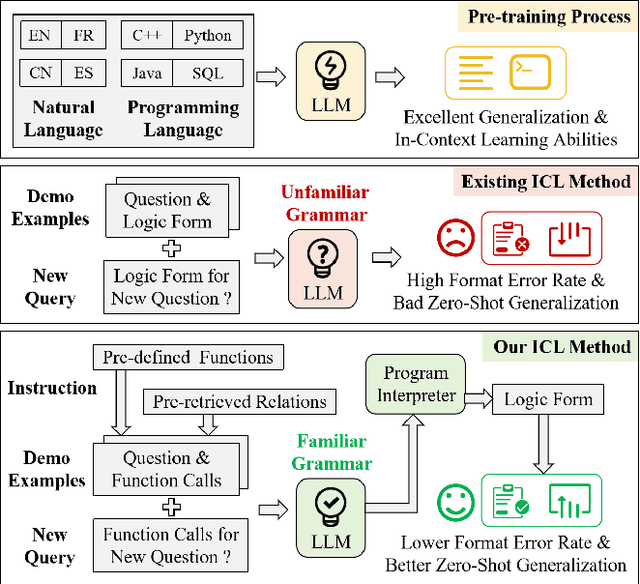


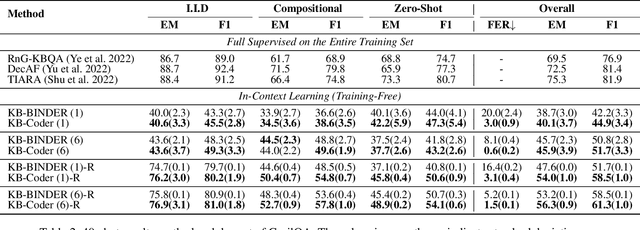
Current methods for Knowledge-Based Question Answering (KBQA) usually rely on complex training techniques and model frameworks, leading to many limitations in practical applications. Recently, the emergence of In-Context Learning (ICL) capabilities in Large Language Models (LLMs) provides a simple and training-free semantic parsing paradigm for KBQA: Given a small number of questions and their labeled logical forms as demo examples, LLMs can understand the task intent and generate the logic form for a new question. However, current powerful LLMs have little exposure to logic forms during pre-training, resulting in a high format error rate. To solve this problem, we propose a code-style in-context learning method for KBQA, which converts the generation process of unfamiliar logical form into the more familiar code generation process for LLMs. Experimental results on three mainstream datasets show that our method dramatically mitigated the formatting error problem in generating logic forms while realizing a new SOTA on WebQSP, GrailQA, and GraphQ under the few-shot setting.
Cross-view Semantic Alignment for Livestreaming Product Recognition
Aug 19, 2023

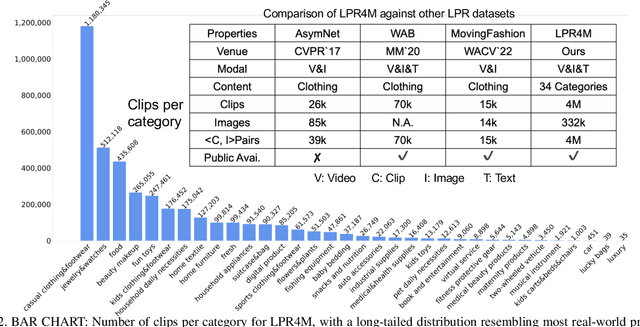
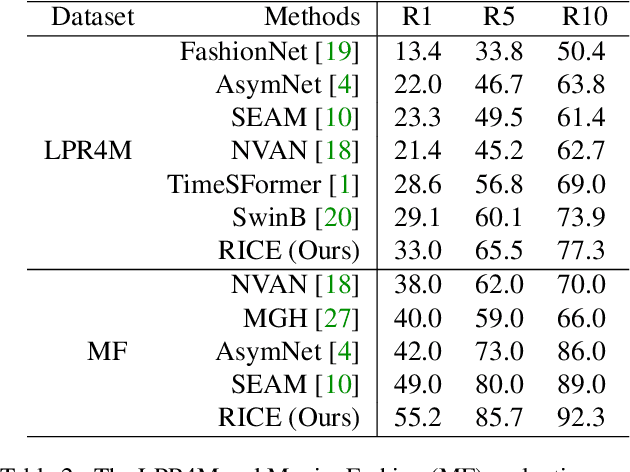
Live commerce is the act of selling products online through live streaming. The customer's diverse demands for online products introduce more challenges to Livestreaming Product Recognition. Previous works have primarily focused on fashion clothing data or utilize single-modal input, which does not reflect the real-world scenario where multimodal data from various categories are present. In this paper, we present LPR4M, a large-scale multimodal dataset that covers 34 categories, comprises 3 modalities (image, video, and text), and is 50x larger than the largest publicly available dataset. LPR4M contains diverse videos and noise modality pairs while exhibiting a long-tailed distribution, resembling real-world problems. Moreover, a cRoss-vIew semantiC alignmEnt (RICE) model is proposed to learn discriminative instance features from the image and video views of the products. This is achieved through instance-level contrastive learning and cross-view patch-level feature propagation. A novel Patch Feature Reconstruction loss is proposed to penalize the semantic misalignment between cross-view patches. Extensive experiments demonstrate the effectiveness of RICE and provide insights into the importance of dataset diversity and expressivity. The dataset and code are available at https://github.com/adxcreative/RICE
The Algonauts Project 2023 Challenge: UARK-UAlbany Team Solution
Aug 01, 2023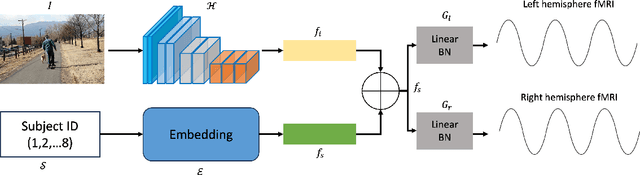

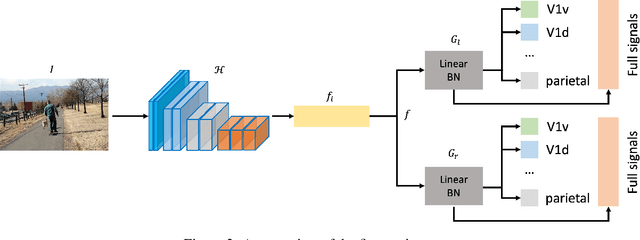

This work presents our solutions to the Algonauts Project 2023 Challenge. The primary objective of the challenge revolves around employing computational models to anticipate brain responses captured during participants' observation of intricate natural visual scenes. The goal is to predict brain responses across the entire visual brain, as it is the region where the most reliable responses to images have been observed. We constructed an image-based brain encoder through a two-step training process to tackle this challenge. Initially, we created a pretrained encoder using data from all subjects. Next, we proceeded to fine-tune individual subjects. Each step employed different training strategies, such as different loss functions and objectives, to introduce diversity. Ultimately, our solution constitutes an ensemble of multiple unique encoders. The code is available at https://github.com/uark-cviu/Algonauts2023
EventCLIP: Adapting CLIP for Event-based Object Recognition
Jun 10, 2023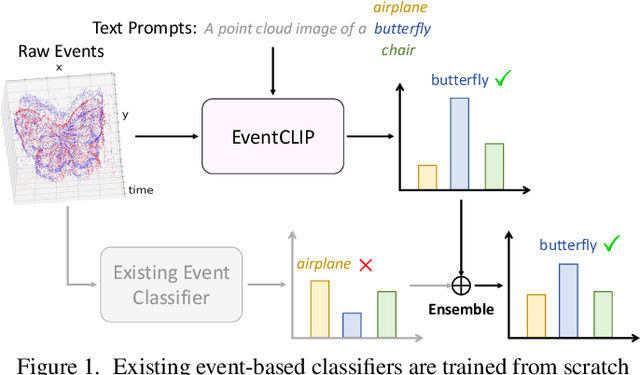

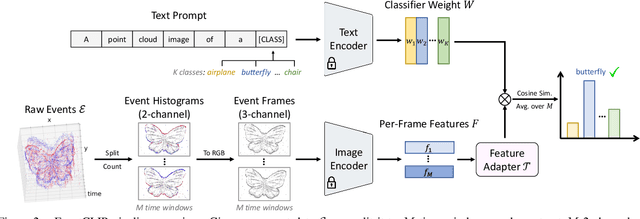
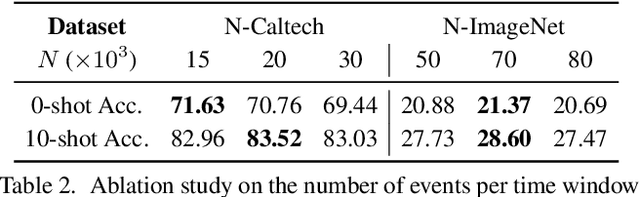
Recent advances in 2D zero-shot and few-shot recognition often leverage large pre-trained vision-language models (VLMs) such as CLIP. Due to a shortage of suitable datasets, it is currently infeasible to train such models for event camera data. Thus, leveraging existing models across modalities is an important research challenge. In this work, we propose EventCLIP, a new method that utilizes CLIP for zero-shot and few-shot recognition on event camera data. First, we demonstrate the suitability of CLIP's image embeddings for zero-shot event classification by converting raw events to 2D grid-based representations. Second, we propose a feature adapter that aggregates temporal information over event frames and refines text embeddings to better align with the visual inputs. We evaluate our work on N-Caltech, N-Cars, and N-ImageNet datasets under the few-shot learning setting, where EventCLIP achieves state-of-the-art performance. Finally, we show that the robustness of existing event-based classifiers against data variations can be further boosted by ensembling with EventCLIP.
High-Fidelity Clothed Avatar Reconstruction from a Single Image
Apr 08, 2023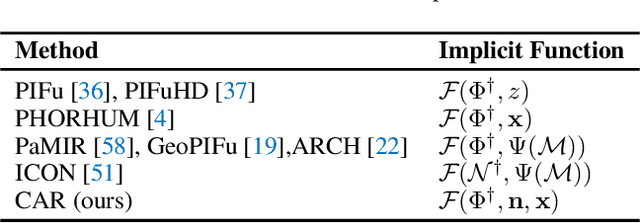
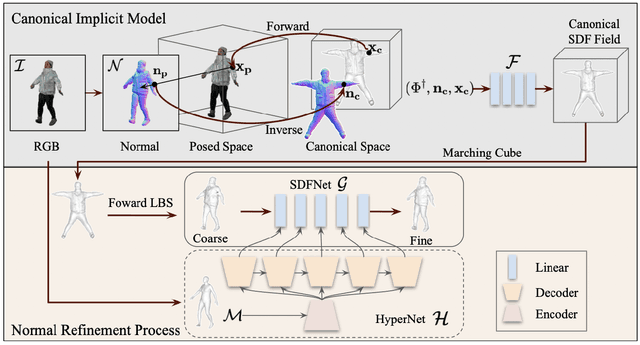

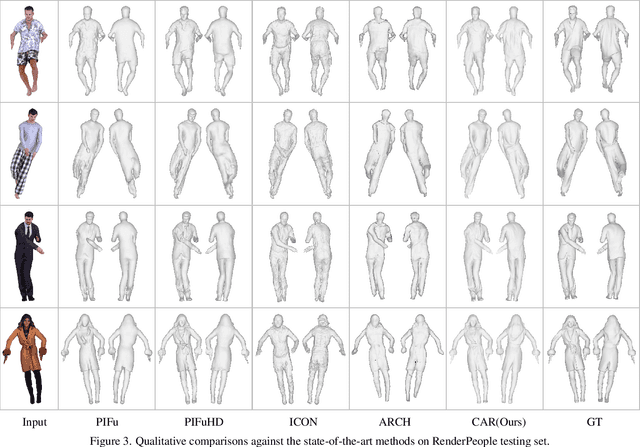
This paper presents a framework for efficient 3D clothed avatar reconstruction. By combining the advantages of the high accuracy of optimization-based methods and the efficiency of learning-based methods, we propose a coarse-to-fine way to realize a high-fidelity clothed avatar reconstruction (CAR) from a single image. At the first stage, we use an implicit model to learn the general shape in the canonical space of a person in a learning-based way, and at the second stage, we refine the surface detail by estimating the non-rigid deformation in the posed space in an optimization way. A hyper-network is utilized to generate a good initialization so that the convergence o f the optimization process is greatly accelerated. Extensive experiments on various datasets show that the proposed CAR successfully produces high-fidelity avatars for arbitrarily clothed humans in real scenes.
Reusing Deep Neural Network Models through Model Re-engineering
Apr 01, 2023
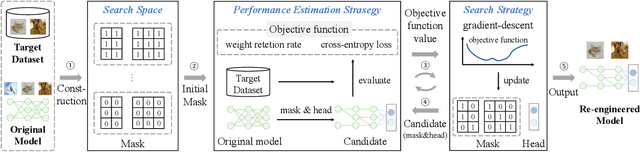
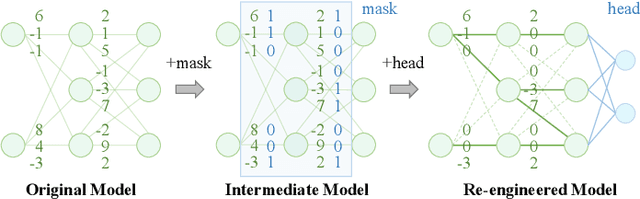
Training deep neural network (DNN) models, which has become an important task in today's software development, is often costly in terms of computational resources and time. With the inspiration of software reuse, building DNN models through reusing existing ones has gained increasing attention recently. Prior approaches to DNN model reuse have two main limitations: 1) reusing the entire model, while only a small part of the model's functionalities (labels) are required, would cause much overhead (e.g., computational and time costs for inference), and 2) model reuse would inherit the defects and weaknesses of the reused model, and hence put the new system under threats of security attack. To solve the above problem, we propose SeaM, a tool that re-engineers a trained DNN model to improve its reusability. Specifically, given a target problem and a trained model, SeaM utilizes a gradient-based search method to search for the model's weights that are relevant to the target problem. The re-engineered model that only retains the relevant weights is then reused to solve the target problem. Evaluation results on widely-used models show that the re-engineered models produced by SeaM only contain 10.11% weights of the original models, resulting 42.41% reduction in terms of inference time. For the target problem, the re-engineered models even outperform the original models in classification accuracy by 5.85%. Moreover, reusing the re-engineered models inherits an average of 57% fewer defects than reusing the entire model. We believe our approach to reducing reuse overhead and defect inheritance is one important step forward for practical model reuse.
Self-training through Classifier Disagreement for Cross-Domain Opinion Target Extraction
Feb 28, 2023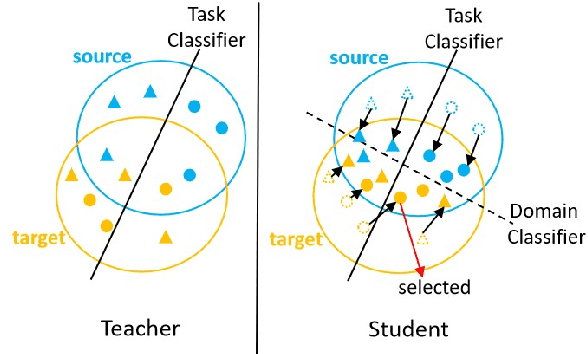
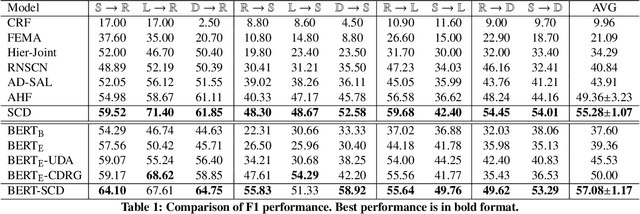
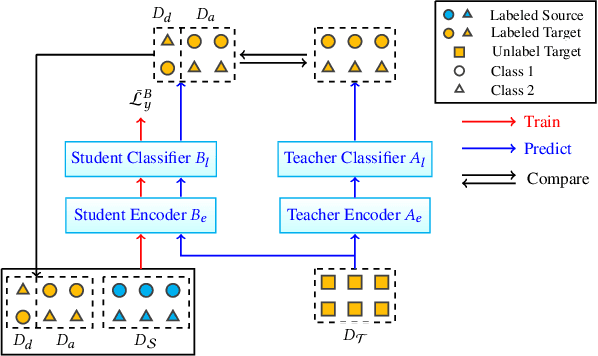
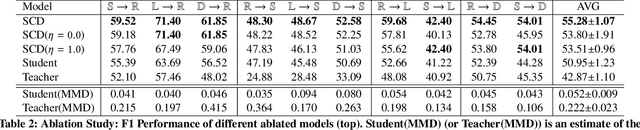
Opinion target extraction (OTE) or aspect extraction (AE) is a fundamental task in opinion mining that aims to extract the targets (or aspects) on which opinions have been expressed. Recent work focus on cross-domain OTE, which is typically encountered in real-world scenarios, where the testing and training distributions differ. Most methods use domain adversarial neural networks that aim to reduce the domain gap between the labelled source and unlabelled target domains to improve target domain performance. However, this approach only aligns feature distributions and does not account for class-wise feature alignment, leading to suboptimal results. Semi-supervised learning (SSL) has been explored as a solution, but is limited by the quality of pseudo-labels generated by the model. Inspired by the theoretical foundations in domain adaptation [2], we propose a new SSL approach that opts for selecting target samples whose model output from a domain-specific teacher and student network disagree on the unlabelled target data, in an effort to boost the target domain performance. Extensive experiments on benchmark cross-domain OTE datasets show that this approach is effective and performs consistently well in settings with large domain shifts.
MorphGANFormer: Transformer-based Face Morphing and De-Morphing
Feb 18, 2023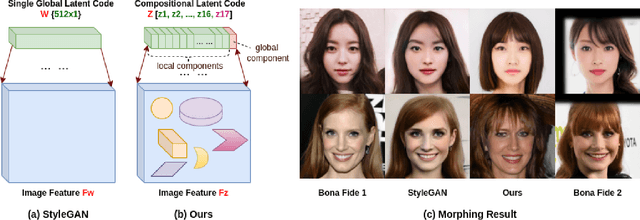



Semantic face image manipulation has received increasing attention in recent years. StyleGAN-based approaches to face morphing are among the leading techniques; however, they often suffer from noticeable blurring and artifacts as a result of the uniform attention in the latent feature space. In this paper, we propose to develop a transformer-based alternative to face morphing and demonstrate its superiority to StyleGAN-based methods. Our contributions are threefold. First, inspired by GANformer, we introduce a bipartite structure to exploit long-range interactions in face images for iterative propagation of information from latent variables to salient facial features. Special loss functions are designed to support the optimization of face morphing. Second, we extend the study of transformer-based face morphing to demorphing by presenting an effective defense strategy with access to a reference image using the same generator of MorphGANFormer. Such demorphing is conceptually similar to unmixing of hyperspectral images but operates in the latent (instead of pixel) space. Third, for the first time, we address a fundamental issue of vulnerability-detectability trade-off for face morphing studies. It is argued that neither doppelganger norrandom pair selection is optimal, and a Lagrangian multiplier-based approach should be used to achieve an improved trade-off between recognition vulnerability and attack detectability.
Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech
Jul 13, 2022
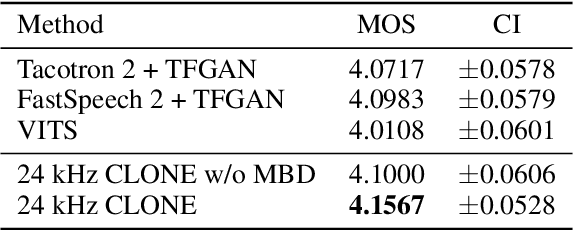
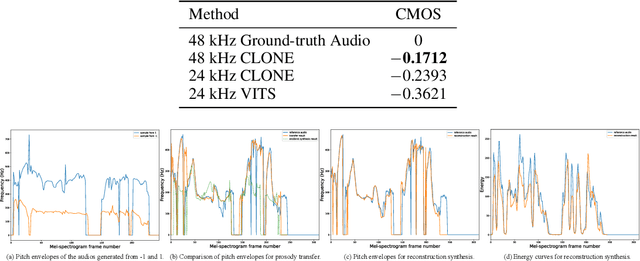

Some recent studies have demonstrated the feasibility of single-stage neural text-to-speech, which does not need to generate mel-spectrograms but generates the raw waveforms directly from the text. Single-stage text-to-speech often faces two problems: a) the one-to-many mapping problem due to multiple speech variations and b) insufficiency of high frequency reconstruction due to the lack of supervision of ground-truth acoustic features during training. To solve the a) problem and generate more expressive speech, we propose a novel phoneme-level prosody modeling method based on a variational autoencoder with normalizing flows to model underlying prosodic information in speech. We also use the prosody predictor to support end-to-end expressive speech synthesis. Furthermore, we propose the dual parallel autoencoder to introduce supervision of the ground-truth acoustic features during training to solve the b) problem enabling our model to generate high-quality speech. We compare the synthesis quality with state-of-the-art text-to-speech systems on an internal expressive English dataset. Both qualitative and quantitative evaluations demonstrate the superiority and robustness of our method for lossless speech generation while also showing a strong capability in prosody modeling.