 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTong Zhou
TBNet: A Neural Architectural Defense Framework Facilitating DNN Model Protection in Trusted Execution Environments
May 07, 2024
Trusted Execution Environments (TEEs) have become a promising solution to secure DNN models on edge devices. However, the existing solutions either provide inadequate protection or introduce large performance overhead. Taking both security and performance into consideration, this paper presents TBNet, a TEE-based defense framework that protects DNN model from a neural architectural perspective. Specifically, TBNet generates a novel Two-Branch substitution model, to respectively exploit (1) the computational resources in the untrusted Rich Execution Environment (REE) for latency reduction and (2) the physically-isolated TEE for model protection. Experimental results on a Raspberry Pi across diverse DNN model architectures and datasets demonstrate that TBNet achieves efficient model protection at a low cost.
Enhancing Large Language Models with Pseudo- and Multisource- Knowledge Graphs for Open-ended Question Answering
Feb 15, 2024Mitigating the hallucinations of Large Language Models (LLMs) and enhancing them is a crucial task. Although some existing methods employ model self-enhancement techniques, they fall short of effectively addressing unknown factual hallucinations. Using Knowledge Graph (KG) enhancement approaches fails to address the generalization across different KG sources and the enhancement of open-ended answer questions simultaneously. To tackle these limitations, there is a framework that combines Pseudo-Graph Generation and Atomic Knowledge Verification proposed. The enhancement of LLM using KG in an open-ended question-answering setting is implemented by leveraging the Pseudo-Graph Generation. Atomic Knowledge Verification utilizes atomic-level knowledge querying and verification to achieve generalizability under different KG sources. Compared to the baseline, this approach yields a minimum improvement of 11.5 in the ROUGE-L score for open-ended questions. For precise questions, we observe a minimum accuracy improvement of 7.5. Moreover, there is also demonstration that this framework exhibits generalizability across different KG sources. In summary, our results pave the way for enhancing LLMs by incorporating Pseudo- and Multisource-KGs, particularly in the context of open-ended questions.
Minimally-intrusive Navigation in Dense Crowds with Integrated Macro and Micro-level Dynamics
Dec 28, 2023In mobile robot navigation, despite advancements, the generation of optimal paths often disrupts pedestrian areas. To tackle this, we propose three key contributions to improve human-robot coexistence in shared spaces. Firstly, we have established a comprehensive framework to understand disturbances at individual and flow levels. Our framework provides specialized computational strategies for in-depth studies of human-robot interactions from both micro and macro perspectives. By employing novel penalty terms, namely Flow Disturbance Penalty (FDP) and Individual Disturbance Penalty (IDP), our framework facilitates a more nuanced assessment and analysis of the robot navigation's impact on pedestrians. Secondly, we introduce an innovative sampling-based navigation system that adeptly integrates a suite of safety measures with the predictability of robotic movements. This system not only accounts for traditional factors such as trajectory length and travel time but also actively incorporates pedestrian awareness. Our navigation system aims to minimize disturbances and promote harmonious coexistence by considering safety protocols, trajectory clarity, and pedestrian engagement. Lastly, we validate our algorithm's effectiveness and real-time performance through simulations and real-world tests, demonstrating its ability to navigate with minimal pedestrian disturbance in various environments.
Towards the Unification of Generative and Discriminative Visual Foundation Model: A Survey
Dec 15, 2023The advent of foundation models, which are pre-trained on vast datasets, has ushered in a new era of computer vision, characterized by their robustness and remarkable zero-shot generalization capabilities. Mirroring the transformative impact of foundation models like large language models (LLMs) in natural language processing, visual foundation models (VFMs) have become a catalyst for groundbreaking developments in computer vision. This review paper delineates the pivotal trajectories of VFMs, emphasizing their scalability and proficiency in generative tasks such as text-to-image synthesis, as well as their adeptness in discriminative tasks including image segmentation. While generative and discriminative models have historically charted distinct paths, we undertake a comprehensive examination of the recent strides made by VFMs in both domains, elucidating their origins, seminal breakthroughs, and pivotal methodologies. Additionally, we collate and discuss the extensive resources that facilitate the development of VFMs and address the challenges that pave the way for future research endeavors. A crucial direction for forthcoming innovation is the amalgamation of generative and discriminative paradigms. The nascent application of generative models within discriminative contexts signifies the early stages of this confluence. This survey aspires to be a contemporary compendium for scholars and practitioners alike, charting the course of VFMs and illuminating their multifaceted landscape.
Oasis: Data Curation and Assessment System for Pretraining of Large Language Models
Nov 21, 2023Data is one of the most critical elements in building a large language model. However, existing systems either fail to customize a corpus curation pipeline or neglect to leverage comprehensive corpus assessment for iterative optimization of the curation. To this end, we present a pretraining corpus curation and assessment platform called Oasis -- a one-stop system for data quality improvement and quantification with user-friendly interactive interfaces. Specifically, the interactive modular rule filter module can devise customized rules according to explicit feedback. The debiased neural filter module builds the quality classification dataset in a negative-centric manner to remove the undesired bias. The adaptive document deduplication module could execute large-scale deduplication with limited memory resources. These three parts constitute the customized data curation module. And in the holistic data assessment module, a corpus can be assessed in local and global views, with three evaluation means including human, GPT-4, and heuristic metrics. We exhibit a complete process to use Oasis for the curation and assessment of pretraining data. In addition, an 800GB bilingual corpus curated by Oasis is publicly released.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.
LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios
Oct 12, 2023
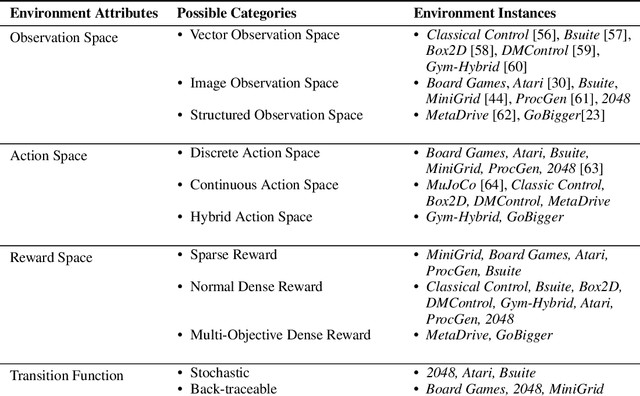
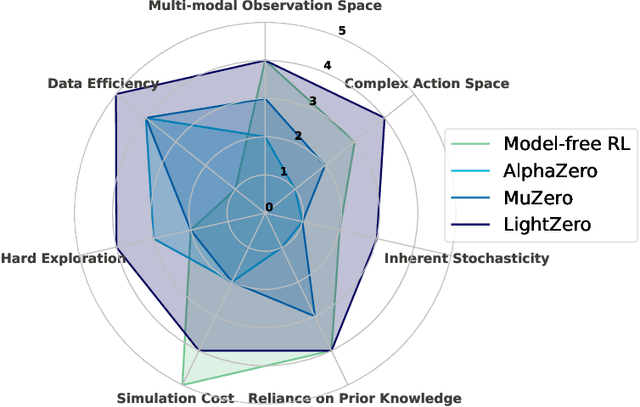
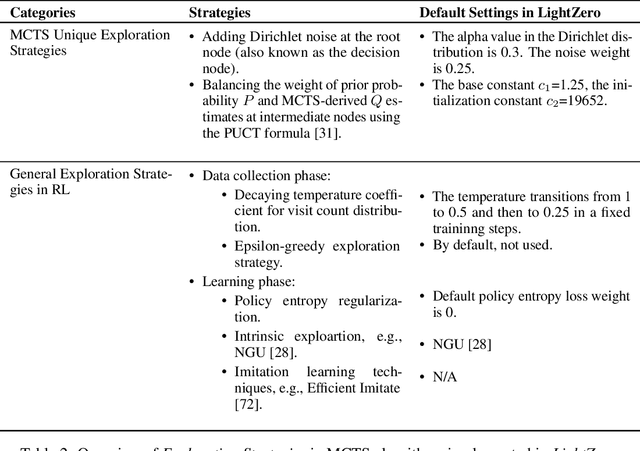
Building agents based on tree-search planning capabilities with learned models has achieved remarkable success in classic decision-making problems, such as Go and Atari. However, it has been deemed challenging or even infeasible to extend Monte Carlo Tree Search (MCTS) based algorithms to diverse real-world applications, especially when these environments involve complex action spaces and significant simulation costs, or inherent stochasticity. In this work, we introduce LightZero, the first unified benchmark for deploying MCTS/MuZero in general sequential decision scenarios. Specificially, we summarize the most critical challenges in designing a general MCTS-style decision-making solver, then decompose the tightly-coupled algorithm and system design of tree-search RL methods into distinct sub-modules. By incorporating more appropriate exploration and optimization strategies, we can significantly enhance these sub-modules and construct powerful LightZero agents to tackle tasks across a wide range of domains, such as board games, Atari, MuJoCo, MiniGrid and GoBigger. Detailed benchmark results reveal the significant potential of such methods in building scalable and efficient decision intelligence. The code is available as part of OpenDILab at https://github.com/opendilab/LightZero.
Towards High Efficient Long-horizon Planning with Expert-guided Motion-encoding Tree Search
Sep 30, 2023Autonomous driving holds promise for increased safety, optimized traffic management, and a new level of convenience in transportation. While model-based reinforcement learning approaches such as MuZero enables long-term planning, the exponentially increase of the number of search nodes as the tree goes deeper significantly effect the searching efficiency. To deal with this problem, in this paper we proposed the expert-guided motion-encoding tree search (EMTS) algorithm. EMTS extends the MuZero algorithm by representing possible motions with a comprehensive motion primitives latent space and incorporating expert policies toimprove the searching efficiency. The comprehensive motion primitives latent space enables EMTS to sample arbitrary trajectories instead of raw action to reduce the depth of the search tree. And the incorporation of expert policies guided the search and training phases the EMTS algorithm to enable early convergence. In the experiment section, the EMTS algorithm is compared with other four algorithms in three challenging scenarios. The experiment result verifies the effectiveness and the searching efficiency of the proposed EMTS algorithm.
AutoReP: Automatic ReLU Replacement for Fast Private Network Inference
Aug 20, 2023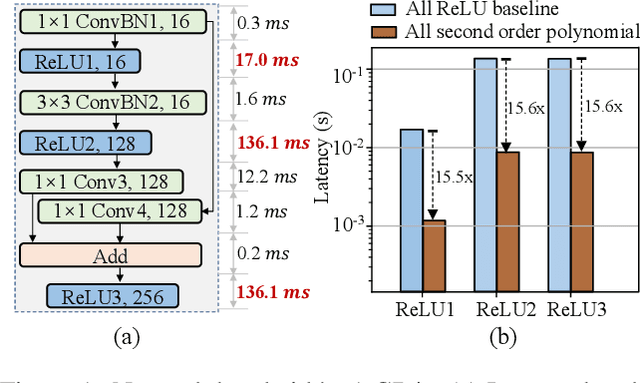


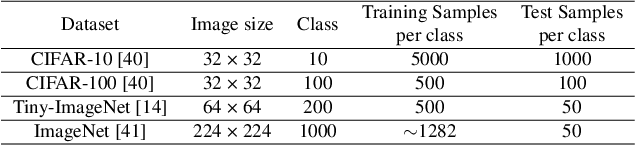
The growth of the Machine-Learning-As-A-Service (MLaaS) market has highlighted clients' data privacy and security issues. Private inference (PI) techniques using cryptographic primitives offer a solution but often have high computation and communication costs, particularly with non-linear operators like ReLU. Many attempts to reduce ReLU operations exist, but they may need heuristic threshold selection or cause substantial accuracy loss. This work introduces AutoReP, a gradient-based approach to lessen non-linear operators and alleviate these issues. It automates the selection of ReLU and polynomial functions to speed up PI applications and introduces distribution-aware polynomial approximation (DaPa) to maintain model expressivity while accurately approximating ReLUs. Our experimental results demonstrate significant accuracy improvements of 6.12% (94.31%, 12.9K ReLU budget, CIFAR-10), 8.39% (74.92%, 12.9K ReLU budget, CIFAR-100), and 9.45% (63.69%, 55K ReLU budget, Tiny-ImageNet) over current state-of-the-art methods, e.g., SNL. Morever, AutoReP is applied to EfficientNet-B2 on ImageNet dataset, and achieved 75.55% accuracy with 176.1 times ReLU budget reduction.
Improved Sales Forecasting using Trend and Seasonality Decomposition with LightGBM
May 26, 2023



Retail sales forecasting presents a significant challenge for large retailers such as Walmart and Amazon, due to the vast assortment of products, geographical location heterogeneity, seasonality, and external factors including weather, local economic conditions, and geopolitical events. Various methods have been employed to tackle this challenge, including traditional time series models, machine learning models, and neural network mechanisms, but the difficulty persists. Categorizing data into relevant groups has been shown to improve sales forecast accuracy as time series from different categories may exhibit distinct patterns. In this paper, we propose a new measure to indicate the unique impacts of the trend and seasonality components on a time series and suggest grouping time series based on this measure. We apply this approach to Walmart sales data from 01/29/2011 to 05/22/2016 and generate sales forecasts from 05/23/2016 to 06/19/2016. Our experiments show that the proposed strategy can achieve improved accuracy. Furthermore, we present a robust pipeline for conducting retail sales forecasting.