 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYafu Li
Generating Diverse Criteria On-the-Fly to Improve Point-wise LLM Rankers
Apr 18, 2024
The most recent pointwise Large Language Model (LLM) rankers have achieved remarkable ranking results. However, these rankers are hindered by two major drawbacks: (1) they fail to follow a standardized comparison guidance during the ranking process, and (2) they struggle with comprehensive considerations when dealing with complicated passages. To address these shortcomings, we propose to build a ranker that generates ranking scores based on a set of criteria from various perspectives. These criteria are intended to direct each perspective in providing a distinct yet synergistic evaluation. Our research, which examines eight datasets from the BEIR benchmark demonstrates that incorporating this multi-perspective criteria ensemble approach markedly enhanced the performance of pointwise LLM rankers.
Potential and Challenges of Model Editing for Social Debiasing
Feb 21, 2024Large language models (LLMs) trained on vast corpora suffer from inevitable stereotype biases. Mitigating these biases with fine-tuning could be both costly and data-hungry. Model editing methods, which focus on modifying LLMs in a post-hoc manner, are of great potential to address debiasing. However, it lacks a comprehensive study that facilitates both internal and external model editing methods, supports various bias types, as well as understands the pros and cons of applying editing methods to stereotypical debiasing. To mitigate this gap, we carefully formulate social debiasing into an editing problem and benchmark seven existing model editing algorithms on stereotypical debiasing, i.e., debias editing. Our findings in three scenarios reveal both the potential and challenges of debias editing: (1) Existing model editing methods can effectively preserve knowledge and mitigate biases, while the generalization of debias effect from edited sentences to semantically equivalent sentences is limited.(2) Sequential editing highlights the robustness of SERAC (Mitchell et al. 2022b), while internal editing methods degenerate with the number of edits. (3) Model editing algorithms achieve generalization towards unseen biases both within the same type and from different types. In light of these findings, we further propose two simple but effective methods to improve debias editing, and experimentally show the effectiveness of the proposed methods.
Understanding In-Context Learning from Repetitions
Oct 10, 2023This paper explores the elusive mechanism underpinning in-context learning in Large Language Models (LLMs). Our work provides a novel perspective by examining in-context learning via the lens of surface repetitions. We quantitatively investigate the role of surface features in text generation, and empirically establish the existence of \emph{token co-occurrence reinforcement}, a principle that strengthens the relationship between two tokens based on their contextual co-occurrences. By investigating the dual impacts of these features, our research illuminates the internal workings of in-context learning and expounds on the reasons for its failures. This paper provides an essential contribution to the understanding of in-context learning and its potential limitations, providing a fresh perspective on this exciting capability.
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Sep 03, 2023


While large language models (LLMs) have demonstrated remarkable capabilities across a range of downstream tasks, a significant concern revolves around their propensity to exhibit hallucinations: LLMs occasionally generate content that diverges from the user input, contradicts previously generated context, or misaligns with established world knowledge. This phenomenon poses a substantial challenge to the reliability of LLMs in real-world scenarios. In this paper, we survey recent efforts on the detection, explanation, and mitigation of hallucination, with an emphasis on the unique challenges posed by LLMs. We present taxonomies of the LLM hallucination phenomena and evaluation benchmarks, analyze existing approaches aiming at mitigating LLM hallucination, and discuss potential directions for future research.
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Aug 21, 2023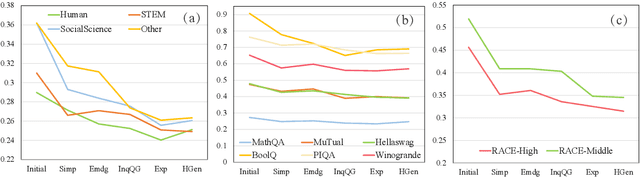

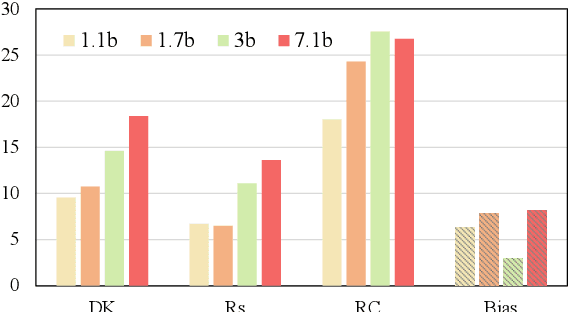
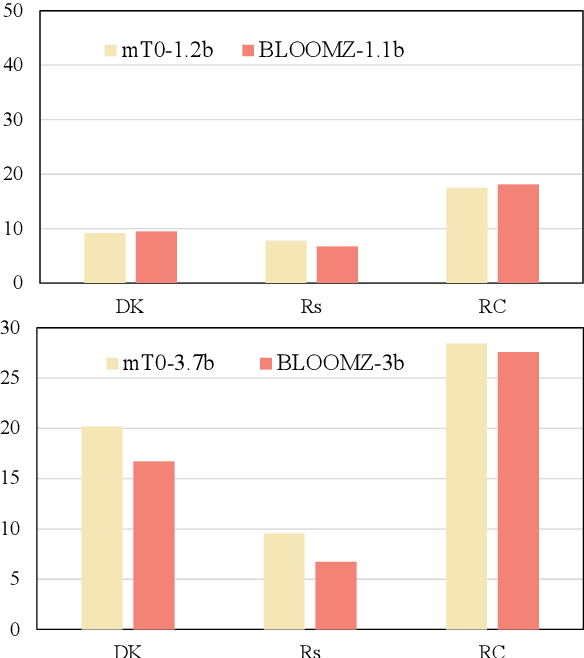
Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information as it learns new information. As large language models (LLMs) have shown excellent performance, it is interesting to uncover whether CF exists in the continual fine-tuning of LLMs. In this study, we empirically evaluate the forgetting phenomenon in LLMs' knowledge, from the perspectives of domain knowledge, reasoning, and reading comprehension. The experiments demonstrate that catastrophic forgetting is generally observed in LLMs ranging from 1b to 7b. Furthermore, as the scale increases, the severity of forgetting also intensifies. Comparing the decoder-only model BLOOMZ with the encoder-decoder model mT0, BLOOMZ suffers less forgetting and maintains more knowledge. We also observe that LLMs can mitigate language bias (e.g. gender bias) during continual fine-tuning. Moreover, we find that ALPACA can maintain more knowledge and capacity compared with LLAMA during the continual fine-tuning, which implies that general instruction tuning can help mitigate the forgetting phenomenon of LLMs in the further fine-tuning process.
Revisiting Cross-Lingual Summarization: A Corpus-based Study and A New Benchmark with Improved Annotation
Jul 08, 2023
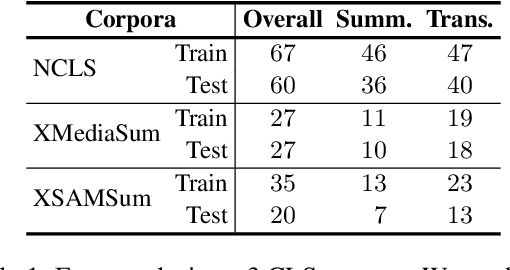

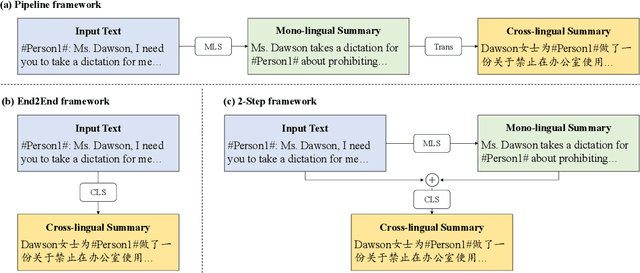
Most existing cross-lingual summarization (CLS) work constructs CLS corpora by simply and directly translating pre-annotated summaries from one language to another, which can contain errors from both summarization and translation processes. To address this issue, we propose ConvSumX, a cross-lingual conversation summarization benchmark, through a new annotation schema that explicitly considers source input context. ConvSumX consists of 2 sub-tasks under different real-world scenarios, with each covering 3 language directions. We conduct thorough analysis on ConvSumX and 3 widely-used manually annotated CLS corpora and empirically find that ConvSumX is more faithful towards input text. Additionally, based on the same intuition, we propose a 2-Step method, which takes both conversation and summary as input to simulate human annotation process. Experimental results show that 2-Step method surpasses strong baselines on ConvSumX under both automatic and human evaluation. Analysis shows that both source input text and summary are crucial for modeling cross-lingual summaries.
Explicit Syntactic Guidance for Neural Text Generation
Jun 25, 2023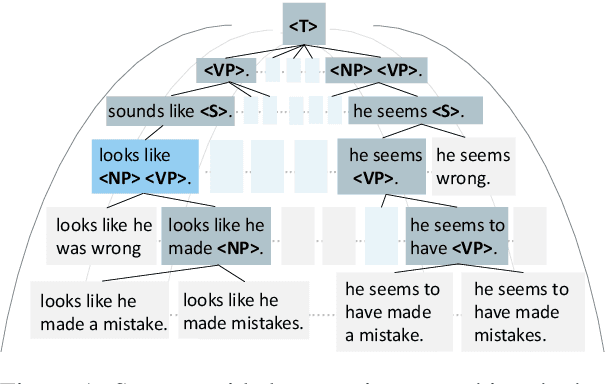
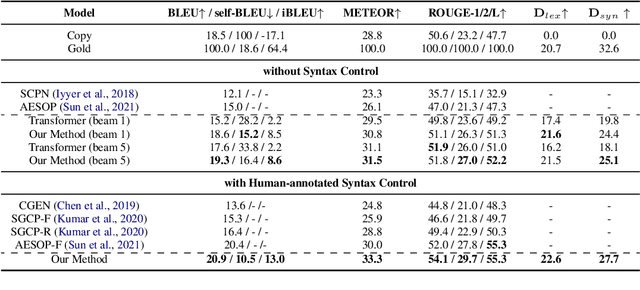
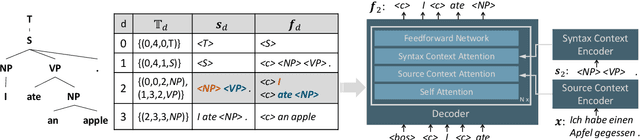

Most existing text generation models follow the sequence-to-sequence paradigm. Generative Grammar suggests that humans generate natural language texts by learning language grammar. We propose a syntax-guided generation schema, which generates the sequence guided by a constituency parse tree in a top-down direction. The decoding process can be decomposed into two parts: (1) predicting the infilling texts for each constituent in the lexicalized syntax context given the source sentence; (2) mapping and expanding each constituent to construct the next-level syntax context. Accordingly, we propose a structural beam search method to find possible syntax structures hierarchically. Experiments on paraphrase generation and machine translation show that the proposed method outperforms autoregressive baselines, while also demonstrating effectiveness in terms of interpretability, controllability, and diversity.
Deepfake Text Detection in the Wild
May 22, 2023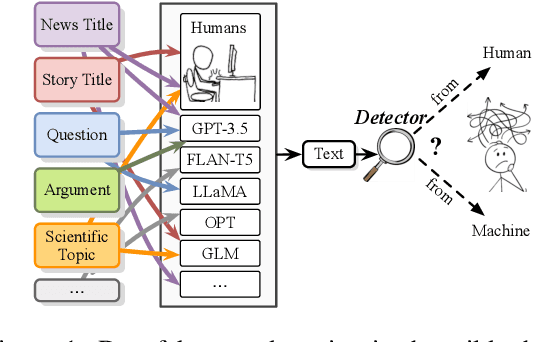


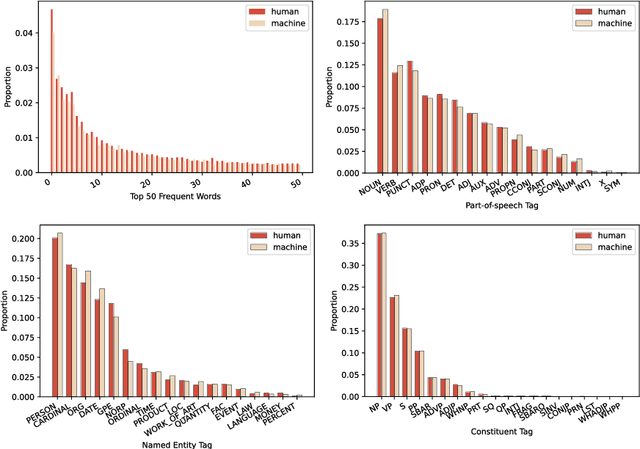
Recent advances in large language models have enabled them to reach a level of text generation comparable to that of humans. These models show powerful capabilities across a wide range of content, including news article writing, story generation, and scientific writing. Such capability further narrows the gap between human-authored and machine-generated texts, highlighting the importance of deepfake text detection to avoid potential risks such as fake news propagation and plagiarism. However, previous work has been limited in that they testify methods on testbed of specific domains or certain language models. In practical scenarios, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a wild testbed by gathering texts from various human writings and deepfake texts generated by different LLMs. Human annotators are only slightly better than random guessing at identifying machine-generated texts. Empirical results on automatic detection methods further showcase the challenges of deepfake text detection in a wild testbed. In addition, out-of-distribution poses a greater challenge for a detector to be employed in realistic application scenarios. We release our resources at https://github.com/yafuly/DeepfakeTextDetect.
GLUE-X: Evaluating Natural Language Understanding Models from an Out-of-distribution Generalization Perspective
Nov 15, 2022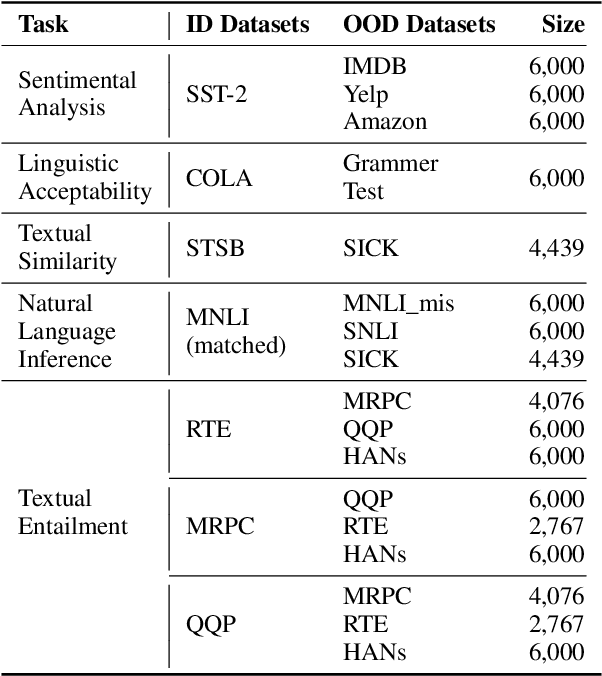
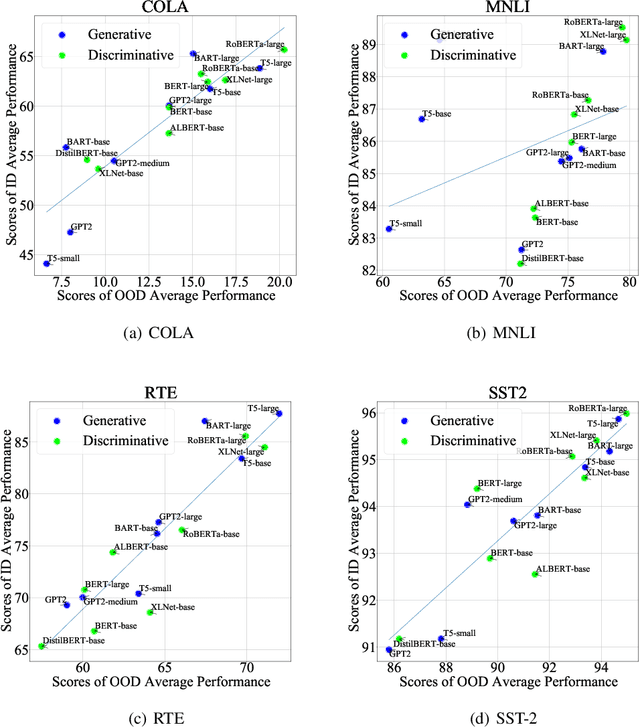
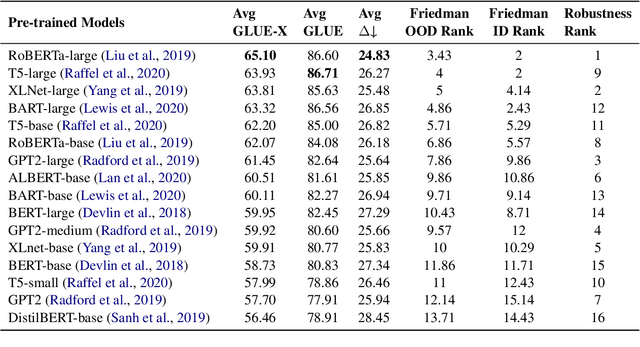

Pre-trained language models (PLMs) improve the model generalization by leveraging massive data as the training corpus in the pre-training phase. However, currently, the out-of-distribution (OOD) generalization becomes a generally ill-posed problem, even for the large-scale PLMs in natural language understanding tasks, which prevents the deployment of NLP methods in the real world. To facilitate the research in this direction, this paper makes the first attempt to establish a unified benchmark named GLUE-X, highlighting the importance of OOD robustness and providing insights on how to measure the robustness of a model and how to improve it. To this end, we collect 13 publicly available datasets as OOD test data, and conduct evaluations on 8 classic NLP tasks over \emph{18} popularly used models. Our findings confirm that the OOD accuracy in NLP tasks needs to be paid more attention to since the significant performance decay compared to ID accuracy has been found in all settings.
Categorizing Semantic Representations for Neural Machine Translation
Oct 13, 2022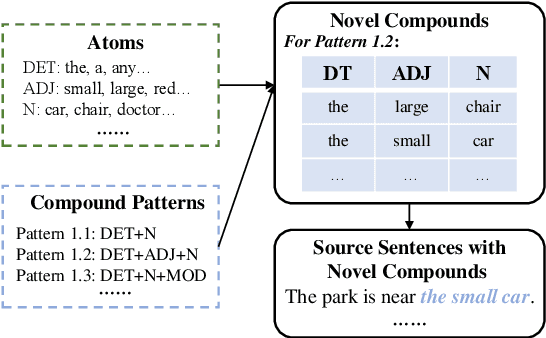

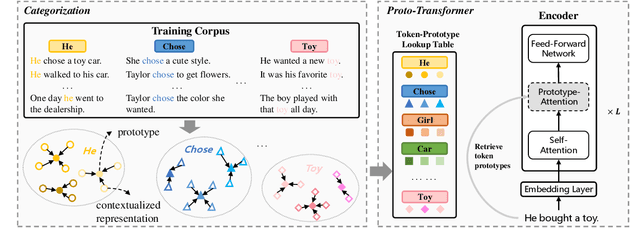
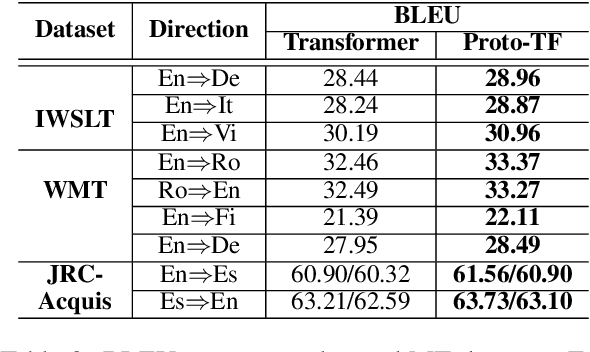
Modern neural machine translation (NMT) models have achieved competitive performance in standard benchmarks. However, they have recently been shown to suffer limitation in compositional generalization, failing to effectively learn the translation of atoms (e.g., words) and their semantic composition (e.g., modification) from seen compounds (e.g., phrases), and thus suffering from significantly weakened translation performance on unseen compounds during inference. We address this issue by introducing categorization to the source contextualized representations. The main idea is to enhance generalization by reducing sparsity and overfitting, which is achieved by finding prototypes of token representations over the training set and integrating their embeddings into the source encoding. Experiments on a dedicated MT dataset (i.e., CoGnition) show that our method reduces compositional generalization error rates by 24\% error reduction. In addition, our conceptually simple method gives consistently better results than the Transformer baseline on a range of general MT datasets.